Zamknięta budowa procesorów nie gwarantuje bezpieczeństwa – dowodzą tego dobitnie kolejne, odkryte w 2018, nieudokumentowane funkcje, błędy i podatności. Koniecznością stają się zatem systematyczne i kompleksowe testy w celu audytu używanych układów. W jaki sposób je przeprowadzić?
Fuzzing to technika zautomatyzowanych testów, w trakcie których dostarcza się nieprawidłowych lub losowych danych jako danych wejściowych dla programu komputerowego. Program jest następnie monitorowany pod kątem występowania wyjątków, błędów projektowych (źle zaalokowana pamięć, luki bezpieczeństwa) czy celowo zaimplementowanych podatności (backdoory, trojany). Podczas gdy zastosowanie fuzzingu do testów oprogramowania jest dobrze znaną i często używaną techniką, fuzzing w odniesieniu do sprzętu jest rzadko stosowany. W tym tekście przedstawiam podstawy i sposoby stosowania tej metody w odniesieniu do procesora.
Cele i zasady działania fuzzingu sprzętowego
Większość układów elektronicznych ma budowę zamkniętą, tzn. producent nie ujawnia informacji na temat wykonania (implementacji) urządzenia, a jedynie informuje użytkownika o podstawowych zasadach pracy produktu. Informacje zawarte w podręcznikach użytkownika, np. “IA-32 Architectures Software Developer’s Manual” firmy Intel, koncentrują się zatem na sposobie wykorzystania i możliwościach danego układu. Samo wdrożenie przedstawiane jest ogólnikowo i tylko w zakresie niezbędnym do zrozumienia zasad pracy produktu. W przypadku procesorów ten podział znajduje odzwierciedlenie między innymi w rozróżnieniu tzw. mikroarchitektury (ang. microarchitecture) i modelu programowego ISA (od ang. instruction set architecture). Mikroarchitektura jest opisem sprzętowej implementacji procesora, definiującym jego działanie, a ISA – jego funkcji widocznych z perspektywy programisty. Na model programowy procesora składają się m.in. typy danych, dostępne tryby adresowania, zestaw rejestrów dostępnych dla programisty, zasady obsługi wyjątków i przerwań czy tryby pracy układu (np. tryb jądra lub użytkownika). Wszystkie te elementy mogą zostać wykorzystane w procesie fuzzingu. Ponadto model programowy definiuje instrukcje i przyjmowane przez procesor dane. W większości implementacji instrukcja składa się z kodu opcode, który określa operację do wykonania (np. dodanie zawartości pamięci do wybranego rejestru) i parametrów, tzw. operand. Operandy, mogą określać rejestry, adresy w pamięci lub bezpośrednio dane. Instrukcje przechowywane są zazwyczaj razem z danymi w pamięci (architektura von Neumanna) w postaci binarnej, jak przedstawiono w przykładzie z Rysunku 1.
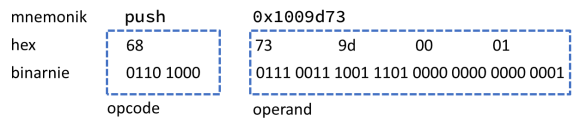
Rysunek 1. Wersja mnemoniczna i binarna instrukcji
W tym kontekście fuzzing procesorów można zdefiniować jako zestaw testów sprawdzających spójność mikroarchitektury i modelu programowego produktu. Cele mogą być następujące:
- sprawdzenie poprawności dostarczonej dokumentacji i implementacji, np. czy wyniki operacji pokrywają się z naszymi oczekiwaniami,
- sprawdzenie kompletności dostarczonej dokumentacji i implementacji, np. pod kątem ukrytych funkcjonalności, takich jak nieudokumentowane instrukcje czy potencjalne luki bezpieczeństwa (w tym backdoory sprzętowe),
- sprawdzenie poprawności oprogramowania, np. asemblery, deasemblery, oprogramowanie nadzorcy (ang. hypervisor), działanie maszyn wirtualnych i emulatorów.
Proces fuzzingu procesora jest zbliżony do procesu testów oprogramowania. Najpierw trzeba zdefiniować wejścia i model działania urządzenia. Punktem wyjścia jest zazwyczaj oficjalna dokumentacja, np. wspomniany “IA-32 Architectures Software Developer’s Manual” firmy Intel. Następnie starannie wprowadzamy procesor w pożądany stan, by móc potem wykonać instrukcje i ocenić zmiany. Ocena sprowadza się do porównania wyników oczekiwanych (np. wynikających z teorii bądź dokumentacji technicznej, czyli tzw. „złotego wzorca”) ze stanem faktycznym. Intuicyjnie najprostsze testy będą zatem wykonane w następujących etapach:
- wygenerowanie instrukcji pokrywających jak największą część modelu programowego ISA, czyli wszystkich opcodów – wszystkie kombinacje bitów – z wszystkimi dostępnymi operandami,
- wykonanie tych instrukcji przez procesor o znanym stanie wejściowym,
- przeanalizowanie stanu procesora po wykonaniu instrukcji.
Jak to zwykle bywa, zadanie to w praktyce nie jest jednak tak proste, jakby się mogło wydawać.
Problem pierwszy: Przygotowanie testów
Po pierwsze nie ma spójnej definicji stanu procesora. W rozumieniu intuicyjnym chodzi o zawartość rejestrów, a także stopień wykonania potoku (ang. pipeline). Jednak współczesne architektury procesorów wysoko wydajnościowych (ang. high performance processor) wprowadzają wiele dodatkowych optymalizacji i rozszerzeń („akcelarotorów”) sprzętowych. W rezultacie pomiędzy instrukcjami następują zależności, które nie wynikają z logiki programu, a z implementacji mechanizmów optymalizacyjnych, np. wykonanie poza kolejnością, w tym wykonanie spekulacyjne. Zależności tego typu są zazwyczaj nieudokumentowane przez producenta, gdyż często nie zdaje on sobie nawet sprawy z ich istnienia – dobrym przykładem są luki Meltdown i Spectre. Dlatego kompleksowe testy powinny sprawdzać dowolnie długie kombinacje następujących po sobie instrukcji.
Dodatkowo wykonane wcześniej instrukcje mogą zmieniać tryby pracy procesora (ang. processor mode, CPU privilege level). Tryby te nakładają ograniczenia na typ i zakres operacji w celu poprawy bezpieczeństwa systemu. Mechanizmem tego typu jest ochrona pierścieniowa, znana np. z implementacji architektury x86, która pozwala oprogramowaniu systemowemu działać z większymi uprawnieniami niż oprogramowanie użytkownika. W rezultacie trybów pracy procesora może być wiele, patrz Rysunek 2.
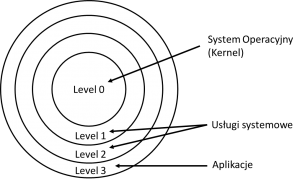
Rysunek 2. Tryby pracy procesora w architekturze x86
W celu ustalenia ewentualnego błędu bądź anomalii w interpretacji i działaniu instrukcji, należałoby testy przeprowadzić dla wszystkich instrukcji we wszystkich trybach i przy znanej historii.
Problem drugi: Zakres testów
W przypadku użycia fuzzingu do audytu oprogramowania jednym z podstawowym problemów jest ustalenie zakresu testów. Nie inaczej jest w przypadku zastosowania tej techniki do sprzętu. Jeśli testujemy jedną wybraną instrukcję w architekturze (modelu programowym) z instrukcjami o stałej długości, to liczba kombinacji (a zatem czas niezbędny do przeprowadzenia testów) jest dość ograniczona. Jeśli jednak zamierzamy przetestować całą ISA współczesnego procesora, to liczba możliwych kombinacji wrasta bardzo szybko. Z tym problemem możemy się spotkać nawet w modelach programowych o zredukowanej liczbie rozkazów (ang. reduced instruction set computer RISC). Na przykład, architektury ARMv6–7 zawierają ponad 50 niezależnych instrukcji, co wydaje się być liczbą stosunkowo niską. Jednak instrukcje te mogą mieć wiele różnych trybów adresowania, rejestrów źródłowych i docelowych, warunków wykonania, flag itp. Większość z tych „pod-instrukcji” musi mieć przypisany własny opcode. To powoduje, że liczba wariantów wykonania poszczególnych instrukcji jest liczona w setki. Jeszcze gorzej sprawa przedstawia się w architekturach CISC, np. x86. ISA x86 wspiera instrukcje o zmiennej długości, tzn. od jednego bajta do piętnastu bajtów, co daje nam 1.3×10^36 możliwych kombinacji.
Dodatkowo liczba dostępnych poleceń zwiększa się wraz z ilością mechanizmów sprzętowych poszerzających zakres pracy procesora. W przypadku architektury x86 rozszerzeń jest bardzo dużo: x87, IA-32, x86-64, MMX, 3DNow!, SSE, SSE2, SSE3, SSSE3, SSE4, SSE4.2, SSE5, AES-NI, CLMUL, RdRand, SHA, MPX, SGX, XOP, F16C, ADX, BMI, FMA, AVX, AVX2, AVX512, VT-x, AMD-V, TSX, ASF.
Iteracyjne sprawdzanie każdej możliwej kombinacji jest w większości wypadków zbyt czasochłonne i wysoce nieefektywne. Sprawdzanie tylko części instrukcji generowanych w sposób losowy będzie obejmowało jedynie niewielki fragment całego modelu programowego, nie dając gwarancji sukcesu. Co więcej, zdecydowana większość wygenerowanych i sprawdzonych w ten sposób instrukcji nie będzie obsługiwana przez mikroarchitekturę.
Oczywiście zakres wyszukiwania można zawęzić do generowania instrukcji zgodnych z formatami opisanymi w dokumentacji technicznej. Pierwszym celem będą zatem zakresy operand i opcodów zawarte w instrukcji i opisane jako niewykorzystane przez mikroarchitekturę, przykład na Rysunku 3. Dlaczego takie elementy znajdują się w modelu programowym? Niezaalokowane fragmenty ISA zostawia się, by umożliwić ewentualne zmiany w przyszłości (np. nowe rozszerzenia typu VT-x czy SSE5) albo by zachować kompatybilność pomiędzy różnymi generacjami, seriami czy wersjami produktów. Istnieją też instrukcje tzw. nieudokumentowane, które wspiera mikroarchitektura, a których nie opisuje producent.
Rysunek 3. Niezaalokowane operandy w procesorach Intela (źródło)
Historycznym przykładem jest LOADALL, czyli wspólna nazwa dwóch różnych, nieudokumentowanych instrukcji procesorów Intel 80286 i Intel 80386. Instrukcje te umożliwiają odczyt stanu procesora z zakresów adresowych, które normalnie znajdują się poza zakresem IA-32 API, takich jak deskryptor rejestrów pamięci podręcznej. LOADALL dla procesorów 286 jest kodowany jako 0fh 05h, podczas gdy LOADALL dla 386 procesorów jako 0fh 07h.
Kolejnym rozwiązaniem jest zawężenie zakresu fuzzingu poprzez zastosowanie „inteligentnego” algorytmu wyszukującego. Jedno z możliwych rozwiązań zaprezentował Christopher Domas na konferencji Black Hat 2017 (prezentacja i wideo są dostępne online). Aby skutecznie zmniejszyć przestrzeń wyszukiwanych instrukcji, autor narzędzia sandsifter do fuzzingu architektury x86 ogranicza procedurę generowania opcodów i operand tylko do kombinacji sensownych z punktu widzenia logiki modelu programowego x86.
W modelu programowym x86 jednym z podstawowych problemów (w kontekście fuzzingu) jest określenie długości wykonywanych instrukcji, w przypadku gdy możliwe jest użycie wielu operand. W tym celu algorytm użyty w narzędziu sandsifter przechowuje bajty wygenerowanych instrukcji na granicy dwóch stron pamięci (ang. memory page), z których tylko pierwsza strona w pamięci jest oznaczona jako wykonywalna – druga jest oznaczona jako niewykonywalna. Jeśli część polecenia znajduje się na kolejnej stronie, system zarządzania pamięcią generuje błąd podczas próby wykonania polecenia. Algorytm zatem rozszerza (przesuwa) instrukcje bajt po bajcie ze strony niewykonywalnej do wykonywalnej do momentu, gdy będzie mógł ją wykonać, patrz Rysunek 4.

Rysunek 4. Poszukiwanie długości wygenerowanej instrukcji (na podstawie: źródło)
Posiadając mechanizm umożliwiający sprawdzenie długości instrukcji, można szybciej sprawdzać wygenerowane kombinacje poprzez pominięcie pól (operand) mniej istotnych z perspektywy testującego, np. stałych symbolicznych, przesunięć etc. Przykład z „Breaking the x86 ISA” jest przedstawiony na Rysunku 5.
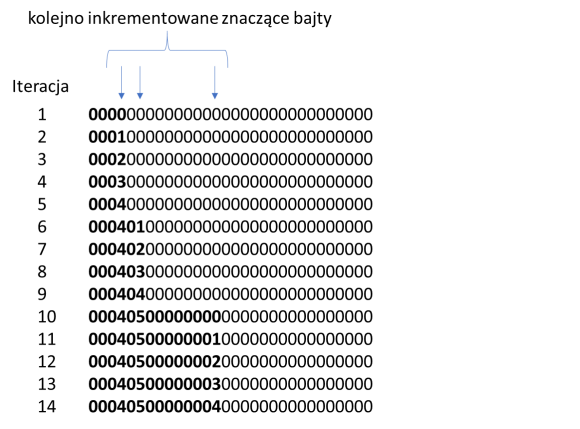
Rysunek 5. Poszukiwanie instrucji za pomocą algorytmu użytego w narzędziu sandsifter (na podstawie: źródło)
W pierwszej iteracji 15-bajtowy bufor jest zapełniany wartościami 0. Następnie instrukcja jest wykonywana iteratywnie za pomocą opisanej wcześniej techniki, by określić jej długość. W rezultacie okazuje się, że instrukcja ma dwa bajty. W następnej iteracji bajt pierwszy pozostawiany bez zmian, a inkrementujemy tylko drugi bajt. Procedura do określenia długości jest następnie ponownie przeprowadzana z otrzymaną w ten sposób nową instrukcją. Algorytm powtarza inkrementacje aż i) długość instrukcji ulegnie zmianie lub ii) procesor wygeneruje wyjątek. Gdy ostatni bajt instrukcji został zwiększony 256 razy (wyczerpanie wszystkich możliwości), a nie wystąpił żaden z opisanych warunków końcowych, algorytm przesuwa proces inkrementacji wstecz (czyli do poprzedniego bajtu instrukcji).
Dzięki temu algorytmowi sandsifter jest w stanie zredukować liczbę kombinacji możliwych instrukcji do około 100 milionów dla architektury x86. Umożliwia to przetestowanie np. procesora Intel Core i7-4650U w ciągu jednego dnia. Sandsifter wykonuje wszystkie instrukcje na tym samym procesorze, na którym jest uruchomiony i zapisuje wszystkie dostępne informacje o błędach. Jeśli CPU nie utworzy nieprawidłowego wyjątku opcode (#UD), wiadomo, że polecenie istnieje. Jeśli wyjątek jest udokumentowany, można instrukcje określić za pomocą dokumentacji i disassemblera, np. Capstone. Jeśli kod wyjątku jest nieznany, to mamy do czynienia albo z nieudokumentowanym poleceniem, albo z błędem. W tym przypadku niezbędna jest dokładna analiza przeprowadzona ręcznie w celu ustalenia szczegółów.
Otrzymane rezultaty
Dobry przekrój wyników, które można osiągnąć za pomocą fuzzingu procesorów, został opisany w publikacji „Breaking the x86 ISA” autorstwa C. Domasa. Pierwszym i najbardziej oczekiwanym rezultatem są rozbieżności pomiędzy mikroarchitekturą a dostarczoną dokumentacją. W procesorze Intel Core i7-4650U pracującym w trybie 64-bitowym znaleziono na przykład następujące nieudokumentowane instrukcje:
- 0f0dxx /non-1 jest instrukcją, która w podręczniku użytkownika jest opisana jako prefetchw dla /1. Jej wykonanie z operandami (pola rejestrów) nie prowadzi do błędów, mimo że operandy te nie są udokumentowane.
- Innym przykładem może być grupa instrukcji 0f18xx, które w przeważającej większości dawały się wykonać, mimo że nie były opisane do wersji -061 (grudzień 2016) podręcznika użytkownika Intela. Warto zauważyć, że procesor, na którym prowadzone były testy, był wyprodukowany w 2012 roku.
Fuzzing sprzętowy można zastosować również do testowania oprogramowania, w tym disassemblerów, maszyn wirtualnych czy emulatorów. Na przykład, narzędzie sandsifter umożliwiło znalezienie błędów w popularnych narzędziach tego typu: IDA, QEMU, gdb, objdump, valgrind, Visual Studio czy Capstone. Przykładem może być nieprawidłowe parsowanie instrukcji skoku (jmp z opcodem e9) i wywołania (call z opcodem e8), jeśli są one poprzedzone prefiksem nadpisującym rozmiar operandy (66) w 64-bitowym pliku wykonywalnym. Na fizycznych procesorach firmy Intel, pracujących w trybie 64-bitowym, prefiks 66 wydaje się być ignorowany, a instrukcja pobiera 4-bajtowy operand tak samo jak w przypadku pracy bez prefiksu. Jednak większość disasemblerów błędnie interpretuje instrukcję i zamiast tego pobiera operand 2-bajtowy (a nawet te, które pobierają operand 4-bajtowy i tak błędnie obliczają cel skoku, zakładając, że jest on skrócony do 16 bitów).
W końcu, fuzzing pozwolił na znalezienie i udokumentowanie błędów sprzętowych w konkretnych produktach implementujących model programowy x86. Na przykład, niektóre procesory firmy AMD generują wyjątek #UD (niezdefiniowany opcode) przed zakończeniem pobierania instrukcji z pamięci. Zgodnie ze specyfikacją AMD, wyjątek #PF (błąd strony) występujący podczas pobierania instrukcji powinien był zastąpić wyjątek #UD. Jednak w testowanych implementacjach #UD był generowany, zanim bajty końcowe zostały usunięte ze strony odczytu/zapisu w przypadku instrukcji, które umieszczają ostatnie bajty na stronie oznaczonej jako niewykonywalna. Co ciekawe, okazało się, że firma AMD odkryła ten sam błąd niezależnie i równolegle do prowadzonych przez Domasa badań. Podręcznik programisty dla produktów AMD został zaktualizowany w marcu 2017 roku.
Czytelników zainteresowanych dokładnym opisem wszystkich rezultatów zachęcam do lektury całości raportu. Kod narzędzia sandsifter jest dostępny na zasadach otwartego oprogramowania.
Podsumowanie
Bezpieczeństwo większości współczesnych programowalnych systemów komputerowych opiera się na założeniu, że procesor funkcjonuje według ściśle określonego i znanego zestawu zasad zaimplementowanego za pomocą mechanizmów sprzętowych. Dlatego błędy i luki w architekturze procesora osiągają często poziom krytyczny dla bezpieczeństwa całego systemu. Zastanawiające jest to, że gdy zapewnienia producentów o bezpieczeństwie oprogramowania z zamkniętym kodem (ang. closed source) już dawno przestały być brane na poważnie, to w analogicznej sytuacji sprzęt uważa się z reguły za bezpieczny. Podczas gdy zastosowanie fuzzingu do audytów oprogramowania jest w wielu wypadkach normą produkcyjną, fuzzing sprzętowy (np. procesorów, routerów, kart sieciowych, kontrolerów USB) nie jest już tak często stosowany. Liczba narzędzi jest mocno ograniczona, brakuje też dokumentacji technicznej. Może warto się zastanowić nad sprawdzeniem własnej infrastruktury w kontekście ilości i znaczenia opisanych wcześniej luk.
Adam Kostrzewa: Od ośmiu lat zajmuję się badaniami naukowymi i doradztwem przemysłowym w zakresie elektroniki motoryzacyjnej, a w szczególności systemów wbudowanych pracujących w czasie rzeczywistym do zastosowań mogących mieć krytyczne znaczenie dla bezpieczeństwa użytkowników. W wolnym czasie jestem entuzjastą bezpieczeństwa danych. Szczególnie interesujące są dla mnie sprzętowe aspekty implementacji obwodów elektrycznych i produkcji krzemu. Metody i narzędzia używane do tych zadań nie są aż tak dostępne i dokładnie przetestowane jak oprogramowanie, dlatego też stanowią interesującą dziedzinę do badań i eksperymentów.
Blog: adamkostrzewa.github.io
Twitter: twitter.com/systemWbudowany




Komentarze
Wedle wszelkiej dostępnej dla mnie literatury, operand jest rodzaju męskiego.
Bzdura ! Operand była kobietą
I Curie-Skłodowska też?
a bo mnie zmyliły
Świetny artykuł! Dzięki!
Więcej tego typu artykułów. Tak trzymać!
Dla zainteresowanych podrzucam link do prelekcji wygłoszonej przez C. Domasa na konferencji Black Hat:
https://www.youtube.com/watch?v=KrksBdWcZgQ
Fuzzowanie fuzzowaniem, ale co z korelacją czasową? Niektóre nieudokumentowane op-cody mogą mieć jakieś dodatkowe „właściwości” w przypadku konkretnego stanu procesora. Można by sobie wyobrazić taki meltdown czy spectre „na sterydach” wzmocniony jakimś opcodem spoza specyfikacji.
Nieudokumentowane opcody Z80 (pamięta ktoś jeszcze) były podstawową ochroną (do czasu) przed disasemblacją. Były obecne z uwagi na układową a nie mikroprogramową architekturę Z80 jako pozostałość po optymalizacji. (chodzi o zminimalizowanie bramek/tranzystorów potrzebnych do realizacji funkcji). Wyższoś takiej architektury to taka (jest oczywiście też wadą) że nie da sie jej niczym zmienić bo 'zaszyta’ jest w masce litograficznej wykorzystywanej do produkcji struktur krzemowych. Żadna zmiana mikrokodu nie jest możliwa a zmiana działania układu kombinacyjnego wymagałaby jakiegoś „przepalenia” wewnętrznych połączeń – przed czym pewnie tez dałoby się sprzętowo zabezpieczyć. Reasumując krzem który liczy funkcje kryptograficzne powinien być „układowy” a nie „mikroprogramowany”