

W nowym odcinku z cyklu “Jak bezpiecznie przenieść się do chmury” omówimy sytuację, której nie życzymy ani dostawcom usług chmurowych, ani ich klientom – ale na którą warto się przygotować.
Artykuł jest częścią zaplanowanego na cały rok cyklu artykułów oraz webinarów sponsorowanych przez firmę Aruba Cloud – dostawcę usług chmurowych z centrum przetwarzania w Polsce. Przed nami jeszcze sześć artykułów i kilka webinarów, a w poprzednich artykułach i webinarach opisałem:
-
- architekturę modelu cloud computingu wg NIST SP 800-145,
- ryzyka natury organizacyjno-prawnej i zarządzania zgodnością na przykładzie pojęcia GRC – Governance, Risk management and Compliance,
- standardy bezpieczeństwa jakie powinna spełniać usługa chmurowa i jak możemy sprawdzić, czy te standardy faktycznie spełnia,
- zarządzanie tożsamością w chmurze i standardy SAML, OpenID, OAuth,
- wdrożenie i zarządzanie uprawnieniami w chmurze.
Wprowadzenie – wyprawa w chmury
Przedstawiając zagadnienie ciągłości działania lubię posługiwać się przykładem Roberta Falcon Scotta i Roalda Amundsena w wyścigu o zdobycie bieguna południowego. Ponad 100 lat temu tych dwóch śmiałków rywalizowało ze sobą w ekstremalnym środowisku. Różniło ich podejście do osiągania celu i przetrwania w trudnych warunkach. Amundsen opierał się na sprawdzonych już wcześniej rozwiązaniach, dobrym rozpoznaniu terenu i panujących warunków oraz symulowaniu sytuacji kryzysowych, w których mógł się znaleźć. Starannie dobierał ludzi, sprzęt, środki lokomocji, miejsca lądowania i magazynów z zapasami, ubrania oraz narzędzia. Scott lubił wprowadzać innowacyjne jak na owe czasu rozwiązania. Na wyprawę na biegun zabrał ze sobą 19 koników mandżurskich, trzy pary niesprawdzonych w warunkach polarnych sań motorowych oraz psy pociągowe stanowiące „backup”. Trzy różne środki lokomocji miały zapewnić sukces wyprawie, jednakże jedne z sań motorowych utopiły się podczas wyładunku, kilka koni padło już na początku wyprawy, a część z nich zdryfowało na krze i zostało zjedzonych przez orki. Najlepiej spisywały się psy, które zawiodły podczas poprzedniej wyprawy. Dla nich z kolei zabrakło żywności, gdyż Scott na początku wyprawy potraktował je jako wariant awaryjny. Amundsen pomimo, że dotarł do brzegów Antarktydy 11 dni później, zdobył biegun południowy ponad miesiąc wcześniej od Scotta. Uzyskał to dzięki lepszemu planowaniu, dostosowaniu się do panujących warunków i przygotowaniu na zdarzenia losowe. Scott pomimo wielkiego rozmachu i zorganizowania największej z dotychczasowych ekspedycji na biegun liczącej 65 osób (z czego 17 uczestników wyprawy) nie ukończył podróży, zamarzając w drodze powrotnej wraz z towarzyszami.
W każdym przedsięwzięciu ważne jest dobre planowanie ścieżki osiągnięcia celu jak przygotowanie się na sytuacje kryzysowe. Korzystając z usług w modelu cloud computing dobrze jest opierać się na sprawdzonych rozwiązaniach, ale należy również oczekiwać nieoczekiwanego, ponieważ nawet największym graczom przytrafiają się spektakularne wpadki.
Wpadki dostawców chmurowych
Na dobry początek przypomnijmy kilka większych incydentów:
- Netflix – nie dla wszystkich wigilia Bożego Narodzenia w 2012 była szczęśliwa. AWS w wyniku aktualizacji zafundował swoim klientom (m.in. Netfliksowi) prezent w postaci przerwy w dostawie usług.
- Cloudflare świadczy usługi w modelu Software as a Service mające zabezpieczać swoich klientów przed atakami typu DDoS. Jednak w 2013 w wyniku aktualizacji spowodował wyłączenie 785 000 stron internetowych.
- Office 365 i Azure – „Microsoft powinien zmienić nazwę swej usługi na Office 360, bo tyle dni w roku jest dostępna”. Dowcip ten powstał po awarii usługi pocztowej w chmurze, która miała miejsce w 2014 roku i spowodowała niedostępność poczty korporacyjnej w wielu firmach na całym świecie. Tego samego roku Microsoft doświadczył awarii systemu Azure, która spowodowała niedostępność usług na 11 godzin. Podobnie jak w przypadku AWS i Cloudflare przyczyną była aktualizacja.
- Atak DDos na firmę DYN zarządzającą usługami DNS wielu popularnych internetowych serwisów. Atak skutkował problemami z dostępem do takich serwisów jak Twitter, Etsy, Github, SoundCloud, Spotify, Heroku, Pagerduty czy Shopify. Brak dywersyfikacji usług DNS wskazuje, że tego rodzaju problemy warto przewidzieć z odpowiednim wyprzedzeniem i zaplanować konfigurację swoich usług. Jak opisywaliśmy, najlepiej z atakiem poradziły sobie serwisy z branży porno.
Ciągłość jest kluczowym komponentem dostępności – jednego z głównych, obok poufności i integralności, filarów bezpieczeństwa informacji. Europejska Agencja ds. Bezpieczeństwa Sieci i Informacji ENISA definiuje dostępność jako oczekiwany procent czasu w zdefiniowanym przedziale czasowym (np. miesiąc lub rok), w którym usługa realizuje żądane operacje.
Na stronie International Working Group on Cloud Computing Resiliency można sprawdzić informacje oraz raporty odnośnie awarii i przestojów usług chmurowych publikowane do roku 2014. Z opracowanego grupę raportu „Downtime statistics of current cloud solutions” obejmującego doniesienia prasowe o awariach w latach 2007-2013, można się dowiedzieć ile one trwały, ile kosztowały oraz jakie były ich przyczyny.
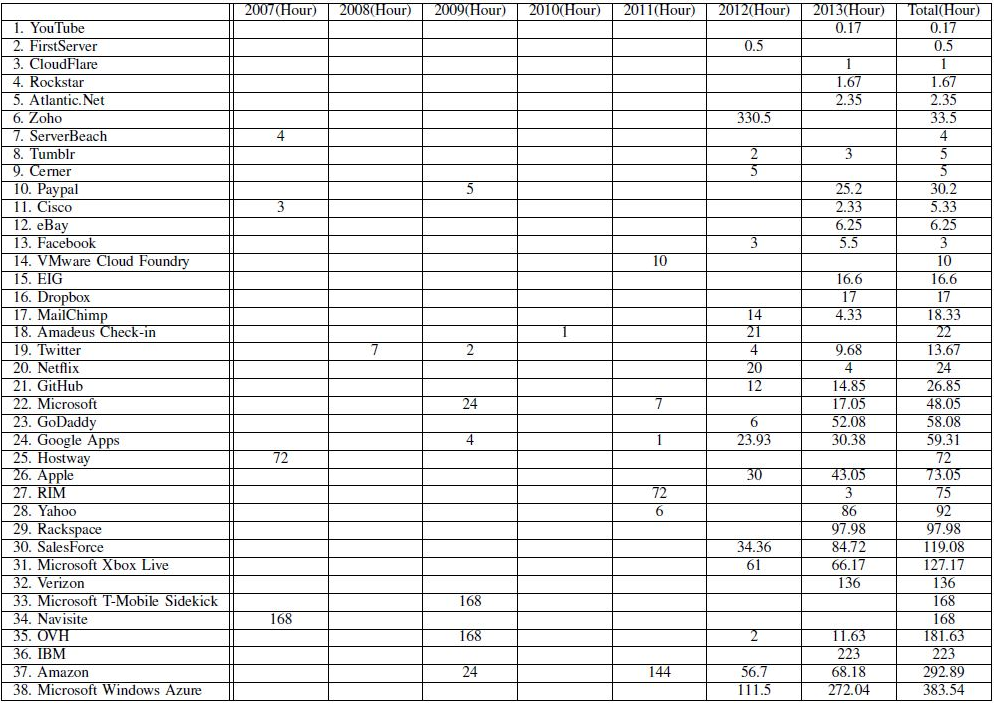
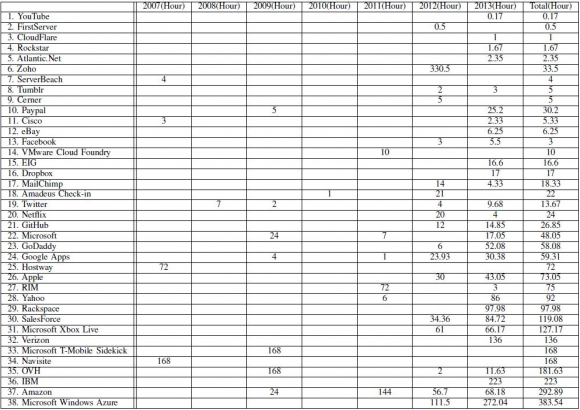
Tabela nr 1: Skumulowany czas (w godzinach) przestoju w latach 2007-2013. Suma wszystkich przestojów wyniosła 2218 godzin.
W tabeli nr 1 prezentowane są czasy przestojów poszczególnych dostawców w kolejnych latach. Nie jest sprecyzowane ile trwały pojedyncze awarie, ale można zauważyć, że poważni gracze mają kłopoty z dostępnością i jest to tendencja wzrostowa. Należy też pamiętać, że statystyki opierają się na publikacjach prasowych i nie uwzględniają przestojów dla mniejszych grup odbiorców.
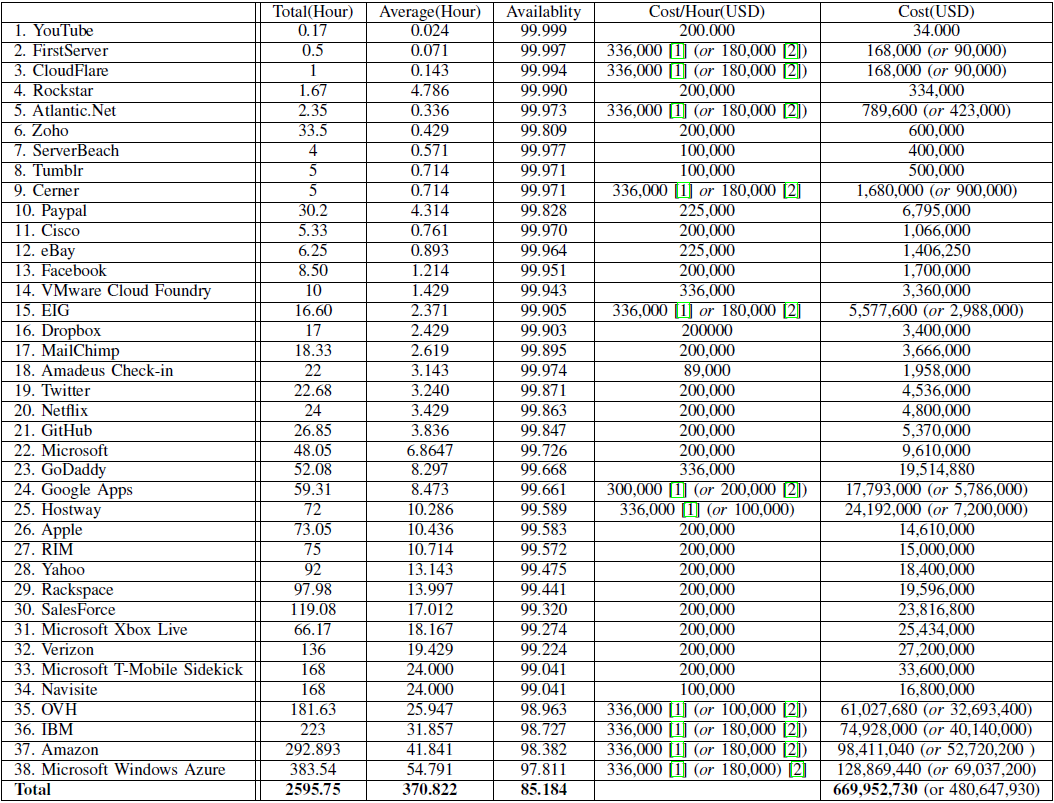
Tabela nr 2: Całkowity i średni czas przestojów oraz ich skutek w aspekcie ekonomicznym.
Tabela nr 2 dodatkowo prezentuje średni czas przestoju oraz konsekwencje finansowe awarii. Poniżej w tabeli prezentowane są dane dotyczące dostępności usług w latach 2012-2013. Wynika z nich, że najgorzej pod tym względem wypadali najbardziej rozpoznawalni dostawcy.
Jak widać na przykładach wpadek dostawców chmurowych, przerwa w dostawie usług może być spowodowana wieloma różnorodnymi czynnikami. Od celowych, losowych po wynikające z błędów ludzkich. Lista możliwych przyczyn może być bardzo długa i zależy od specyfiki oraz lokalizacji dostarczanych usług. Decydując się na korzystanie z usług chmurowych musimy przeprowadzić analizę, której wynik da nam podstawy do opracowania (lub aktualizacji) planów zachowania ciągłości i odzyskiwania po awarii oraz do określenia oczekiwań i warunków, jakie powinien spełnić dostawca. Pamiętajmy, że to jakiej jakości otrzymamy usługę będzie miało wpływ na nasze wyniki ekonomiczne, reputację oraz zaufanie naszych klientów i pracowników. Jednym z powszechnie znanych sposobów na wykonanie takiej analizy jest BIA – Business Impact Analysis, czyli ocena wpływu na biznes w połączeniu z oceną ryzyka (RA). W uproszczeniu składa się ona z kilku podstawowych etapów:
- Zidentyfikowaniu kluczowych usług i przetwarzanych za ich pomocą danych.
- Identyfikacji związanych z nimi zagrożeń oraz konsekwencji ich niedostępności (finansowe, reputacyjne, prawne).
- Określenie maksymalnego tolerowanego czasu trwania zakłócenia (Maximum tolerable period of disruption – MTPD), RTO (recovery time objective) – czyli czasu w jakim należy przywrócić procesy po wystąpieniu awarii; oraz RPO (recovery point objective) – czyli akceptowalnego poziomu utraty danych wyrażonego w czasie.
- Zdefiniowania rozwiązań pozwalających na uzyskanie wcześniej określonych parametrów.
Na podstawie zebranych danych możemy przygotować lub zaktualizować strategię i plan ciągłości działania dla usług, które będą dostarczane w modelu chmury. Przy tego typu usługach musimy rozważyć „tradycyjne” zagrożenia mogące spowodować niedostępność usług przekazywanych na zewnątrz organizacji takich jak:
- bankructwo dostawcy,
- jakość usług niezgodna z warunkami SLA,
- uzależnienie od dostawcy (vendor lock in),
- zaprzestanie świadczenia, rozwoju lub wsparcia usługi,
- wygaśnięcie umowy,
- zmiana warunków umowy na niekorzystne,
- katastrofy naturalne.
Dodatkowo należy uwzględnić te specyficzne dla architektury modelu cloud computing. Jednym z takich zagrożeń jest fakt, że wiele usług oferowanych w modelu cloud computing stanowi tak naprawdę łańcuch usług chmurowych, w szczególności w modelu Software as a Service. Przykładem takiego rozwiązania są usługi SAP w modelu SaaS i PaaS postawione na infrastrukturze świadczonej w formie usługi przez Google.
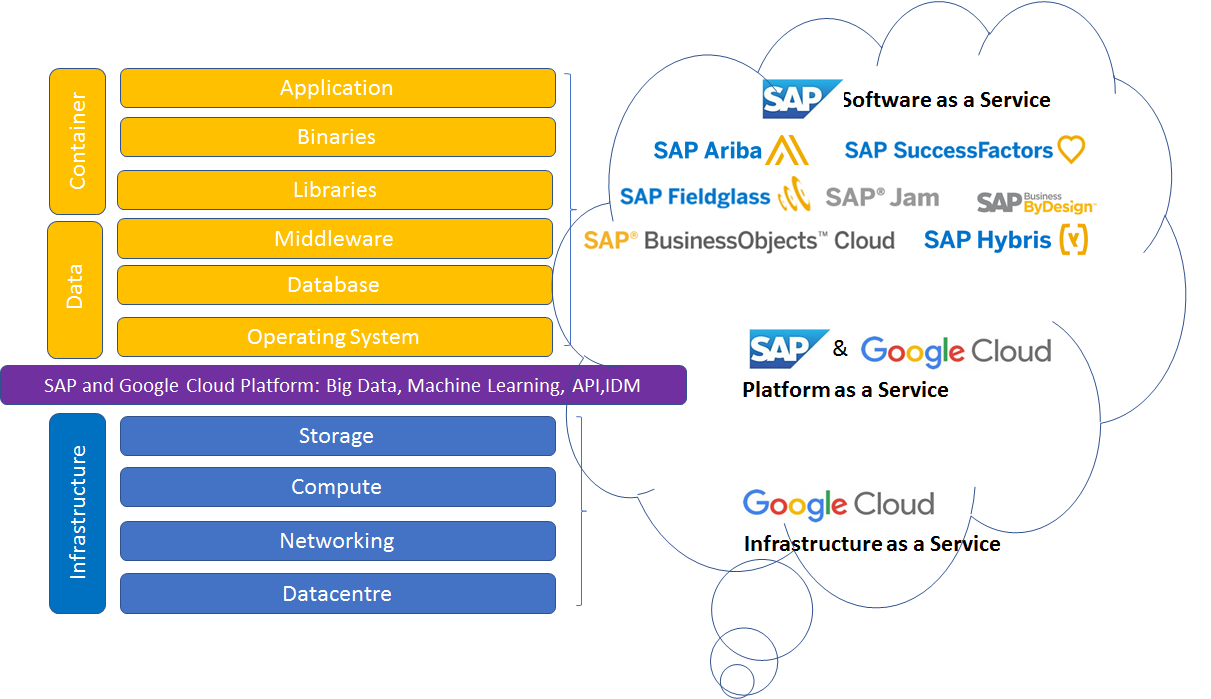
Przy określaniu procedur reakcji na incydenty i szacowaniu możliwości spełnienia warunków SLA trzeba zidentyfikować wszystkich graczy uczestniczących w łańcuchu dostaw i rozważyć sytuację, w której jakieś ogniwo przestanie świadczyć lub wspierać usługę.
Po zidentyfikowaniu czynników mogących mieć wpływ na zakłócenie ciągłości działania możemy rozpocząć szacowanie ewentualnych skutków zmaterializowania się zagrożeń. Konsekwencje możemy rozpatrywać pod różnymi aspektami mającymi kluczowe znaczenie dla prowadzonej przez nas działalności. Mogą one być rozpatrywane pod kątem strat finansowych, wizerunkowych, konsekwencji prawnych, a nawet w odniesieniu do zagrożenia zdrowia i życia (np. systemy bezpieczeństwa bądź medyczne). Jednymi z najbardziej dotkliwych kwestii jest utrata bądź niedostępność danych, które mogą być zarówno przyczyną jak i następstwem zakłócenia działania i wpływać na wszystkie w/w konsekwencje. Z tego powodu bierze się ten aspekt pod uwagę przy definiowaniu poziomów MTPD, RTO i RPO. Po określeniu parametrów można projektować rozwiązania umożliwiające ich spełnienie oraz dodatkowo te, które będą odpowiedzią na zidentyfikowane zagrożenia i podatności. Przedstawię kilka przykładów takich zabezpieczeń, zarówno technicznych jak i organizacyjnych koncentrując się na tych mających zastosowanie dla usług przekazywanych na zewnątrz organizacji, w tym w szczególności chmurowych.
Umowa o gwarantowanym poziomie świadczenia usług
Czyli po staropolsku SLA (Service Level Agreement). Podstawa do ustalenia pomiędzy stronami wszelkich warunków i parametrów świadczenia usług, które powinny być definiowane w sposób jasny i mierzalny (aby były weryfikowalne). Precyzyjne określenie kluczowych parametrów poziomu usługi jest kluczowe zarówno dla zapewnienia ciągłego działania aplikacji jak i dla określenia trybu postępowania w przypadku wystąpienia problemów – bez szukania wtedy winnych za daną sytuację.
Technologiczne parametry SLA dotyczą warstw usług związanych z aplikacją i infrastrukturą. W przypadku modelu IaaS określają parametry infrastruktury (np. dostępność usługi, pojemność przestrzeni dyskowej, przepustowość łączy, limity transferu, dostępność sieci) . W przypadku modelu SaaS mogą dochodzić parametry SLA dotyczące umów utrzymaniowych.
Dostępność systemu
Jak już wspomniałem wcześniej dostępność to zdolność systemu do poprawnego wypełniania powierzonego mu zadania w okresie czasu. Kabaret Tey występujący w czasach głębokiego PRL-u, w programie „Na tyłach sklepu” miał skecz o zepsutym traktorze, w którym kierownik sklepu przekonywał, że nie traktor się zepsuł tylko koło się zepsuło i nie zepsuło tylko trzy są dobre. Żeby uniknąć takich sytuacji warto doprecyzować czego dokładnie dotyczy definicja dostępności. Czy w modelu IaaS całej infrastruktury czy poszczególnych jej komponentów? A może możliwych do wykonania operacji na wirtualnych instancjach? Czy w modelu SaaS mierzona jest niedostępność całej aplikacji czy też niedostępność poszczególnych jej funkcji, kluczowych dla klienta, też będzie uwzględniona? A może należy wziąć pod uwagę również czas odpowiedzi na żądanie?
Warto zdać sobie sprawę z jak długą niedostępnością systemu w ciągu miesiąca może wiązać się zgoda na określony poziom procentowy.
| Dostępność | Czas niedostępności w ciągu miesiąca |
| 95% | 36 godzin (2160 minut) |
| 99% | 7 godzin (432 minuty) |
| 99,50% | 3,5 godziny (216 minut) |
| 99,90% | 43 minuty i 12 sekund |
| 99,99% | 4 minuty i 19 sekund |
| 100,00% | 25 sekund |
Przy określaniu wymogów dotyczących dostępności warto wziąć pod uwagę, czy poza godzinami i dniami roboczymi też należy stosować te same wartości. Dzięki takiemu rozróżnieniu możemy uzyskać bardziej efektywne kosztowo rozwiązanie.
Jednym z parametrów stosowanym przez dostawców jest wspomniane już wcześniej RTO (Recovery Time Objective) jako dopuszczalny czas, w którym usługi mają zostać przywrócone, który może być mierzony wobec MRT (Mean Recovery Time) – średni czas potrzebny na przywrócenie usług. W stosowaniu RTO bardzo ważne jest zrozumienie, jakiej usługi ono dotyczy. W modelu IaaS dostawca prawdopodobnie zastosuje je raczej do poszczególnych komponentów niż do całej infrastruktury.
Monitorowanie, raportowanie i czas reakcji
Niektóre usługi wymagają natychmiastowego ich przywrócenia. Dla przykładu serwis finansowy w modelu SaaS posiada niezależny system kolejkowania, który w przypadku przestoju umożliwia przechowywanie nieprzetworzonych transakcji przez średnio 2 minuty. Odbiorca będzie wymagał, aby czas przywrócenia usługi (RTO) był zdefiniowany jako mniejszy niż minuta. Oczekuje, że otrzyma miesięczny raport prezentujący MRT dla tej usługi. Z zapewnieniem tak określonej dostępności wiąże się ustalenie sposobu monitorowania usługi i raportowania jakości usługi. Jakie mogą być kryteria i metody zastosowane do monitorowania dostępności usług:
- oparte na informacjach i zgłoszeniach od użytkowników zgłaszanych przez formularze internetowe lub biuro obsługi klienta,
- dostawca monitoruje i analizuje logi i dostarcza tych informacji klientowi różnymi kanałami komunikacji np. serwis www, raporty, emaile, smsy,
- część dostawców oferuje narzędzia w ramach swojego portfolio np. Amazon – Cloudwatch, Azure – Service Health, Activity Log, Application Insights czy Aruba z usługą Cloud Monitoring,
- dostępnych jest też wiele zewnętrznych narzędzi (w modelu SaaS) monitorujących usługi w chmurze np. New Relic czy Manage Engine Cloud Monitoring.
Zgłaszanie błędów i incydentów
W ramach SLA koniecznie powinna być opisana procedura zgłaszania błędów i incydentów wraz z ustaleniem czasów reakcji i przywrócenia usług oraz progów alarmowych, aby nie było wątpliwości, które zgłoszenia kwalifikują się do obsługi. Ważne jest gromadzenie historii zgłoszeń w celu weryfikacji zdefiniowanych parametrów. Dobrą praktyką jest stosowanie systemu ticketowego, który umożliwia klientowi raportowanie danych.
Przepustowość łączy i limity transferu
Warto zwrócić uwagę na gwarantowaną przez dostawcę przepustowość łącza i koszty dodatkowego transferu oraz na to, co stanie się po jego przekroczeniu. Nawet jeśli nasza usługa ma dostępność na poziomie 99,9% a w połowie miesiąca skończy się nam limit transferu i pasmo zostanie przycięte, istnieje ryzyko, że nasza usługa nie będzie działała satysfakcjonująco dla naszych klientów.
Kary umowne
Niedostępność usług chmurowych może prowadzić do strat biznesowych, prawnych czy reputacyjnych Warto dzielić się tym ryzykiem z dostawcą i o ile to możliwe określić w umowie wysokość kar.
Strategia wyjścia
Plan wyjścia jest przygotowywany na wypadek pogorszenia lub braku możliwości świadczenia usługi przez dostawcę na uzgodnionym przez nas poziomie i warunkach. Warunki zakończenia mariażu z dostawcą powinny być negocjowane przed popisaniem umowy, kiedy pozycja klienta jest silna. Najlepiej, jeśli zapewni się wsparcie dostawcy w procesie przeniesienia usług do własnego centrum danych lub innego dostawcy. Plan wyjścia powinien zawierać szczegółowe kroki oraz zdefiniowane mierniki, które będzie można monitorować w celu weryfikacji wywiązywania się dostawcy z obowiązków. Najważniejszym aspektem jest zabezpieczenie danych osobowych klientów – w szczególności w modelu SaaS. Podstawowym celem jest zapewnienie przenaszalności danych. Taki obowiązek nakłada na administratorów danych i przetwarzających Rozporządzenie o ochronie danych osobowych poprzez prawo do przenoszenia danych (opisane w webinarium dotyczącym RODO w chmurze).
Zapasowe środowiska i kopie danych
W wyniku analizy możemy dojść do wniosku, że w celu osiągnięcia oczekiwanego poziomu dostępności usług potrzebne jest utworzenie zapasowych środowisk. W takim przypadku musimy być świadomi podziału odpowiedzialności pomiędzy klienta a dostawcę ze względu na rodzaj świadczonej usługi. Szczegółowo wyjaśniam to podczas webinara poświęconemu zarządzaniu ryzykiem w chmurze. Jeśli korzystamy z usług w modelu Infrastructure as a service to sami musimy zadbać o redundancję zainstalowanych przez nas komponentów. W celu uniknięcia sytuacji, gdy awaria jednego komponentu (serwer wirtualny, hypervisor, centrum danych) powoduje przestój całego środowiska musimy sprawdzić, jakie mechanizmy w tym zakresie oferuje dostawca. Pytania, które warto zadać to:
- czy nasza usługa została uruchomiona w środowisku redundantnym,
- czy sprzęt został podłączony za pomocą dwóch niezależnych zasilaczy do dwóch źródeł zasilania,
- czy posiada dyski, które mogą być wymieniane w trybie hot-swap (bez przestoju serwera),
- czy posiada niezależne połączenia do sieci Internet za pomocą dwóch niezależnych interfejsów,
- czy w przypadku awarii jednego węzła zapewnia przełączenie na zapasowy,
- czy oferowane jest to w ramach umowy, czy jest to dodatkowa usługa,
- czy dostawca posiada centra danych w różnych lokalizacjach geograficznych,
- czy jest możliwe tworzenie chmur hybrydowych umożliwiających tworzenie własnych rozwiązań w tym zakresie,
- jak zapewniana jest dostępność sieci internetowej,
- czy techniki wysokiej dostępności dotyczą też osprzętu sieciowego takiego jak routery, switche i okablowanie którego nie dzierżawimy wprost – a które wpływa na jakość naszej usługi.
Wielu dostawców oferuje usługi zapewniające ciągłość działania i odzyskiwanie po katastrofie. Obejmują one również wykonywanie i odtwarzanie kopii zapasowych oraz ich testowanie. Należy zweryfikować, jakie metody tworzenia kopii zapasowych są stosowane, jakie systemy obejmują, gdzie są przechowywane i w jakim formacie. Czas przywracania kopii zapasowych często jest określany przez wspomniane już Recovery Point Objective (jak często kopia ma być wykonywana) i Recovery Time Objective (ile może trwać odtwarzanie). Oba powinny być rozpatrywane łącznie. Jeśli dopuszczalne RPO jest za wysokie (np. dostawca wykonuje kopie raz w tygodniu), to mimo, że RTO jest zdefiniowane tak, że odtwarzanie jest bardzo szybkie, to okaże się, że straciliśmy wszystkie operacje z całego tygodnia. Jeśli chcemy zminimalizować RTO oraz jednocześnie maksymalnie zminimalizować RPO powinniśmy wymagać tworzenia kopii w trybie ciągłym (hot-swap).
Podsumowanie
Przed decyzją o migracji usług do chmury warto zrobić rozpoznanie terenu, zidentyfikować jak najwięcej złych scenariuszy zdarzeń, które mogą nam się przytrafić, sprawdzić jakie rozwiązania oferuje dostawca oraz przygotować odpowiedni plan działań. Warto sobie przygotować też plan wyjścia, aby bezpiecznie wrócić do miejsca, z którego wyruszyliśmy. Życzymy Wam samych udanych podróży.
Dla zachowania pełnej przejrzystości: za opublikowanie tego artykułu pobieramy wynagrodzenie.



Komentarze
Troche stare te dane ;)
Ale artykul fajny, dzieki!
Nie tylko stare.
W tabeli 1:
-Zocho w 2012 roku było wyłączone przez 330,5 godziny, co daje sumę 33,5 h.
-Facebook 3 (2012) + 5,5 (2013) daje razem 3 godziny.
-Twitter 7 (2008) + 2 (2009) + 4 (2012) + 9,68 (2013) daje razem 13,67.
Byłbym wdzięczny za wskazanie w jakim systemie liczbowym podane są te wartości, bo jak próbuję przeliczać w dziesiętnym, to mi wychodzą inne wyniki.
To pytanie do autorów tych zestawień. Dopiero przy zwróceniu uwagi zauważyłem te błędy.
W pierwszej tabelce pozycja nr 6 w 2012 roku ma 330,5 godzin awarii i łącznie 33,5 godzin awarii – zakładam, że w zamiast 330,5 powinno być 33,5?
wygląda na to, że jedno zero autorom raportów się wkradło :)
SLA 100% to 0 sekund w miesiącu.
26 sekund na miesiąc to 99.999 czyli 'five nines’
Warto by podkreślić, kiedy mówisz o rozwiązaniach hybrydowych i serwerach 'bare-metal’.
Większość dostawców nie odpowie Ci na pytania o ilość zasilaczy czy dyski hot-swap, jeśli to chmura.
W rozwiązaniach chmurowych, zasób który widzimy jako dyski nie musi być i zazwyczaj nie jest umieszczony fizycznie w serwerze który obsługuje twoją maszynę wirtualną.
Piszesz że: „Jeśli korzystamy z usług w modelu Infrastructure as a service to sami musimy zadbać o redundancję zainstalowanych przez nas komponentów” to komponentem jest zasób wirtualny, a więc odpowiednio zaprojektowana aplikacja i skonfigurowane środowisko, a nie dbanie o zasoby fizyczne.
Zabezpieczeniem jest wtedy korzystanie z regionów/zon/cell i rozkładanie poszczególnych usług w taki sposób by zminimalizować ryzyko przy awarii jednego z komponentów, i tu już kłania się architektura rozwiązania.
W większości przypadków bezpośrednie przeniesienie rozwiązań „on premise”, bądź z dzierżawionej infrastruktury do chmury to proszenie się o katastrofę.
Trzeba zrozumieć jak korzystać z zasobów udostępnionych przez dostawcę, jak zabezpieczać swoje zasoby i dostęp do nich, za pomocą usług oferowanych przez daną chmurę.
Zgadza się z tym czasem. Mój błąd.
Jeśli chodzi o pytania do dostawców to też muszę przyznac Ci rację. Większość dostawców nie odpowie na większość pytań. To jednak da nam też jakaś odpowiedź.
Co do dalszych komentarzy. To jest właśnie meritum tego co chcę przekazać w całym cyklu artykułów czyli po czyjej stronie leży odpowiedzialność za zabezpieczenie poszczególnych komponentów architektury w odniesieniu do rodzaju usługi (IaaS, Paas czy SaaS). Od tego rozpoczął się cały cykl (patrz pierwszy artykuł i webinar). Dzięki za uwagi.