Monitorowanie usług i infrastruktury niejednemu administratorowi oszczędziło stresu, nerwów a czasem także nagłej zmiany miejsca zatrudnienia. Opisujemy zatem, jak monitorować, by się nie zamartwiać.
Wśród systemów wykorzystywanych do monitorowania stanu aplikacji, usług serwerowych czy zasobów sieciowych możemy wyróżnić wiele ich rodzajów, stosując przy tym podział według typu monitorowanych zasobów lub sposobu ich działania czy wykorzystywanej technologii. W przypadku rozwiązania, które musi być dostarczane w trybie ciągłym, wdrażamy je w ramach wysokodostępnych platform, często gwarantujących SLA na poziomie 99,99% i większym. Projektując kompletne systemy, poza uruchomieniem ich w technologii wysokiej dostępności takiej jak klaster HA Active-Active, mamy oczywistą potrzebę monitorowania jej pod kątem wystąpienia potencjalnych przerw. Nawet jeżeli przełączenie nodów klastra nie będzie wiązało się ze skutkami zauważalnymi dla użytkowników systemu, to z pewnością o takiej sytuacji chcemy zostać powiadomieni bez zbędnej zwłoki.
Chcąc wdrożyć odpowiednie rozwiązanie monitorujące, wybierać możemy spośród wielu ich typów. Do najczęściej spotykanych należą:
- Agentowe, czyli wymagające instalacji dedykowanego oprogramowania lub korzystające z autorskiego protokołu. W tym modelu to zazwyczaj agent zainstalowany na monitorowanych zasobach będzie wysyłać dane kontrolne do centralnej usługi monitorującej.
- Bezagentowe, działające w oparciu o ogólnodostępne protokoły i mechanizmy testujące. Tutaj najczęściej jeden centralny serwer lub platforma monitorująca cyklicznie odpytuje wskazane systemy czy aplikacje o ich stan.
- Chmurowe – funkcjonują one w ramach wysokodostępnej infrastruktury, zazwyczaj są dedykowane do monitorowania zasobów danego dostawcy chmurowego lub systemów osiągalnych w sieci Internet.
- On-premise – czyli lokalne, uruchamiane w ramach własnych zasobów obliczeniowych, najczęściej wykorzystywane do nadzorowania pracy systemów wewnętrznych – zarówno w ramach infrastruktur IT, jak i OT/IOT.
Tematyka monitoringu zasobów sieciowych i serwerowych jest bardzo rozległa. Nie sposób w ramach krótkiego streszczenia dotknąć każdego z jej aspektów, z drugiej jednak strony o pewnych technologiach czy protokołach nie wypada wręcz nie wspomnieć.
Jednym z nich jest protokół ICMP – Internet Message Control Protocol. Zazwyczaj to z niego w pierwszej kolejności skorzystamy, o ile zostaniemy powiadomieni o problemie. ICMP to protokół bezstanowy, co w praktyce oznacza, że przesyła kontrolny pakiet danych i oczekuje na odpowiedź od systemu docelowego. Sam fakt odebrania odpowiedzi nie oznacza jeszcze, że odpytywane rozwiązanie jest dostępne. Na co dzień najczęściej korzystamy z powszechnie znanego narzędzia ,,ping” – jeśli host po drugiej stronie nie udzieli nam oczekiwanej odpowiedzi (lub pakiet ICMP Echo Reply nie dotrze do nas w oczekiwanym czasie), przystępujemy do dalszej analizy problemu.
Kolejną z technologii jest protokołów Simple Network Management Protocol, który poza samym monitorowaniem pozwala również na zarządzanie konfiguracją rozwiązań sieciowych, jakie SNMP wspiera. Może działać dwukierunkowo:
- nasz system odpytuje wskazane rozwiązanie o parametry poszczególnych jego zasobów (stan pracy wentylatorów i monitoring temperatury, wykorzystanie CPU/RAM, zajętość przestrzeni dyskowej itp.) ,
- docelowe rozwiązanie samo może powiadamiać system monitorujący o swoim stanie z wykorzystaniem tzw. trapów.
SNMP opracowano wiele lat temu i jego pierwsze wersje miały niewiele wspólnego z pojęciem bezpieczeństwa sieciowego. Dopiero jego trzecie wydanie zapewnia zadowalający poziom zabezpieczeń dla mechanizmów autoryzacji i samego przesyłania danych. Niestety nie wszystkie dostępne na rynku rozwiązania sieciowe (a w szczególności te posiadające zamknięty system operacyjny) wspierać będą SNMP. Wielu dostawców implementuje też własne rozwiązania (a nawet dedykowane protokoły) wykorzystywane do monitoringu pracy i powiadamiania o problemach, co w praktyce oznacza konieczność zakupu dodatkowych narzędzi od tego samego producenta.
O ile z wykorzystaniem samego protokołu ICMP mamy możliwość zweryfikowania, czy zdalny system jest dla nas osiągalny, to w przypadku usług działających w oparciu o protokoły wyższych warstw modelu ISO/OSI, wykorzystując go, niewiele jesteśmy w stanie ustalić. W takim wypadku z pomocą przyjdą nam narzędzia umożliwiające zestawienie połączenia na wskazany port protokołu TCP. Dość często skorzystamy z polecenia telnet, ale bynajmniej nie do zrealizowania połączenia z użyciem protokołu o tej samej nazwie. Polecenie telnet (lub równie popularne w przypadku platform Linux/Unix polecenie nc) pozwoli nam zweryfikować, czy połączenie na wskazany numer portu TCP zakończy się powodzeniem. Transmission Control Protocol wymaga ustanowienia sesji dla każdego nowego połączenia z wykorzystaniem mechanizmu o nazwie 3-way handshake. W zależności od przebiegu tego handshake’a jesteśmy w stanie wstępnie zweryfikować, z jakim problemem mamy do czynienia:
- brak odpowiedzi od hosta zdalnego na pakiet z ustawioną flagą SYN w zadanym czasie (tzw. timeout) – usługa nie odpowiada,
- host zdalny wysyła pakiet z flagą RST – aktywna odmowa połączenia – może je powodować błąd w konfiguracji usługi lub urządzenia pośredniczącego w komunikacji, może to też oznaczać zatrzymanie pracy usługi,
- nawiązywanie połączenia trwa długo, a często wręcz ponowne próby połączenia kończą się niepowodzeniem (timeout) – prawdopodobieństwo przeciążenia zasobów lub problemów w dostępności usług świadczonych przez dostawcę łącza internetowego.
Oczywiście powyższe przykłady stanowią opis najczęstszych wniosków płynących z przeprowadzanej diagnostyki. Wynik takich działań jest wykorzystywany do podjęcia decyzji co do dalszych czynności diagnostycznych.
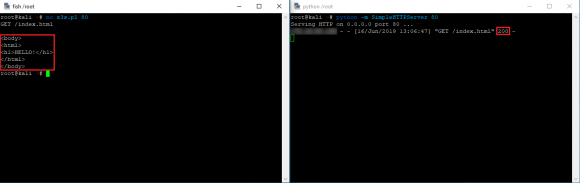
Jeżeli testowe połączenie jest realizowane poprawnie, to często możemy ustalić, czy sama usługa działająca w oparciu o protokoły poziomu aplikacyjnego udziela prawidłowych odpowiedzi. Wykonajmy zatem prosty test na dostępność web serwera oraz systemu pocztowego:
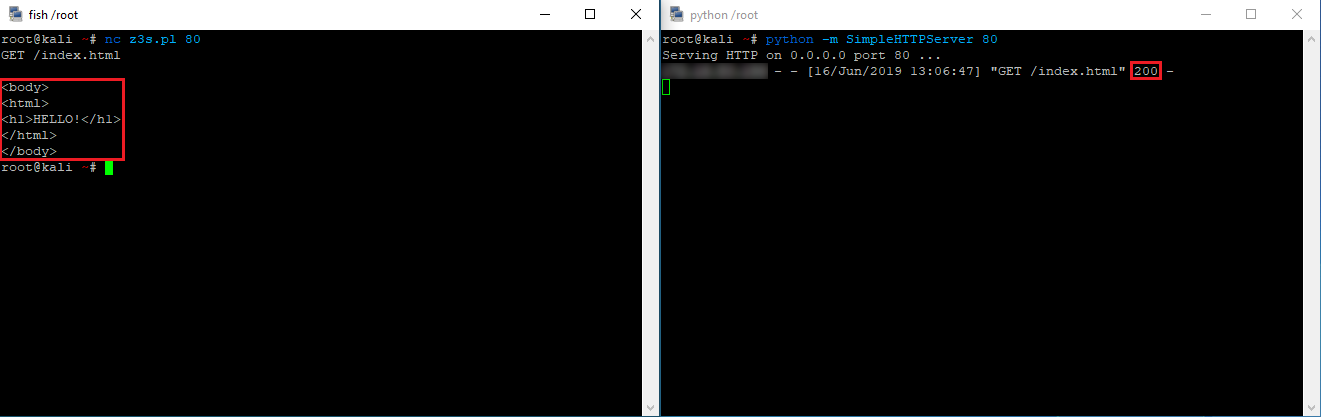

Otrzymaliśmy kolejno odpowiedzi o kodzie 200 dla HTTP oraz 220 dla protokołu SMTP. Stanowią one poprawne odpowiedzi tych usług i oznaczają ich gotowość do dalszego przeprowadzania transmisji.
Czy zatem samo odpytanie usługi w ramach protokołu TCP i poprawna odpowiedź lub wyświetlenie banera serwera oznaczają, że cały nasz system lub aplikacja funkcjonują prawidłowo? W przypadku problemów z samą usługą web serwera może on odpowiedzieć szeregiem komunikatów błędów, w tym np. kodem 500 (Internal Server Error). Jeżeli jednak posiadamy bardziej złożoną aplikację, to będzie ona pracować w oparciu o wiele dodatkowych komponentów – bazę danych, interpreter PHP czy API do systemów zewnętrznych. Jeżeli któryś z nich zawiedzie, to w praktyce nie będzie oznaczać niedostępności usługi serwera WWW. Dlatego ewentualne możliwe scenariusze awarii naszego rozwiązania muszą być odpowiednio obsługiwane.
Niektóre z aplikacji internetowych posiadają gotowe mechanizmy pozwalające zweryfikować, czy działają one prawidłowo. W jednym z wcześniejszych artykułów przedstawiliśmy scenariusz wdrożenia chmury plikowej w oparciu o rozwiązanie NextCloud. W jego ramach możliwe jest włączenie mechanizmu o nazwie ,,serverinfo”, który dzięki możliwości odpytania o diagnostyczny adres URL w postaci „https://<nextcloud-fqdn>/ocs/v2.php/apps/serverinfo/api/v1/info” zwraca w formacie JSON stan całej aplikacji wraz z parametrami serwera odpowiedzialnego za jej dostarczanie. Więcej informacji na temat tego dodatku możecie znaleźć w jego repozytorium na GitHubie.
W przypadku innych webaplikacji – takich jak np. WordPress – kwestia ich monitorowania może być już nieco bardziej skomplikowana. Do samego WordPressa dostępne są wtyczki typu ,,health check”, przy czym ich główną ideą jest przede wszystkim weryfikowanie poprawności konfiguracji, stanu aktualności aplikacji i zainstalowanych dodatków, przy jednoczesnym generowaniu graficznych raportów. Samą kwestię zwracania kodu 200 dla protokołu HTTP można rozwiązać poprzez odpytywanie modułu wp-load.php. Jeżeli nasz serwer dostarcza różne strony działające w oparciu o WordPressa w zależności od wywołanej subdomeny, to odpytanie o wskazaną zawartość zwróci kod 302 (Moved Temporarily), przez co system monitorujący może uznać naszą aplikację za niedostępną. Rozwiązaniem tego problemu może być stworzenie prostej podstrony z fragmentem kodu napisanym w PHP:
$_SERVER['HTTP_HOST'] = 'z3s.pl';
require( '../../../wp-load.php' );
echo 'OK';Docelowo taką podstronę możemy nazwać monitoring.php i umieścić w odpowiedniej ścieżce serwera, jaka będzie możliwa do odpytania przez zewnętrzny monitoring, np. http://z3s.pl/monitoring/monitoring.php.
Warto pamiętać, aby dostęp do wskazanego URL-a ograniczyć tylko do puli adresów IP z jakiej połączenia generować będzie nasze rozwiązanie monitorujące.
Aruba Cloud Monitoring
Proces konfiguracji usługi możecie zobaczyć na poniższym filmie lub przeczytać w formie tekstowej pod nim.
Aruba Cloud Monitoring to prosta w konfiguracji i obsłudze usługa pozwalająca na monitorowanie stanu naszych serwerów oraz działających na nich usług. Może być ona wdrożona zarówno dla instancji pracujących w ramach różnych data center Aruba Cloud, niemniej jednak pozwala ona też na monitorowanie zasobów zewnętrznych zlokalizowanych w centrach danych innych dostawców.
To, co jest warte uwagi, to bezpłatny plan monitoringu, który możemy aktywować w liczbie równej wartości naszych instancji Aruba Cloud Pro. W wielu scenariuszach będzie on w zupełności wystarczający, a w przypadku wysokodostępnych instancji działających w ramach planów Aruba Cloud Pro pozwoli przede wszystkim na monitorowanie poprawności pracy naszych aplikacji.
W przypadku braku dostępności skonfigurowanego zasobu Cloud Monitoring powiadomi nas niezwłocznie o tym fakcie. Do wyboru mamy dwa rodzaje powiadomień: e-mail oraz SMS. Samo powiadamianie to nie wszystko – w ramach tego rozwiązania mamy również dostęp do historycznych statystyk dostępności usługi. W zależności od konfiguracji i wykorzystywanej metody monitorowania jednorazowy brak odpowiedzi niekoniecznie będzie stanowić zdarzenie, o którym chcemy być niezwłocznie powiadomieni. Mimo wszystko taki stan chwilowej degradacji usługi (lub opóźnienia w odpowiedzi) zostanie zapisany w statystykach, co pozwoli na późniejszą analizę problemu. W przypadku niektórych z awarii ich pierwsze symptomy mogą pojawić się na długo przed całkowitym i długotrwałym zatrzymaniem pracy systemu czy aplikacji, stąd też samo ustalenie przyczyny awarii dla wielu administratorów stanowi dużo większy problem niż jej doraźne usunięcie.
Aktywacja usługi
Podobnie jak w przypadku wcześniej opisywanych scenariuszy wykorzystania usług Aruba Cloud i tym razem aktywacja sprowadza się do przejścia przez dosłownie trzy okna kreatora usługi. Po zalogowaniu do Panelu Kontrolnego Cloud wybieramy zakładkę Cloud MONITORING i klikamy na przycisk

Kolejno wybieramy plan usługi zapewniający oczekiwaną przez nas funkcjonalność:

Zaraz poniżej opcji wyboru planu nadajemy mu nazwę i ustawiamy maksymalną wartość powiadomień wysyłanych w ciągu jednej godziny:

Po kliknięciu na UTWÓRZ PLAN MONITORINGUw kolejnym oknie zatwierdzamy jego zakup:

Nasza usługa zostanie aktywowana i w dalszej kolejności będziemy mogli przejść do dodania kontrolowanego zasobu. W tym celu klikamy na przycisk UTWÓRZ KONTROLĘ.

Nadajemy nazwę dla naszej kontroli i wybieramy protokół, z wykorzystaniem jakiego usługa będzie monitorowana:
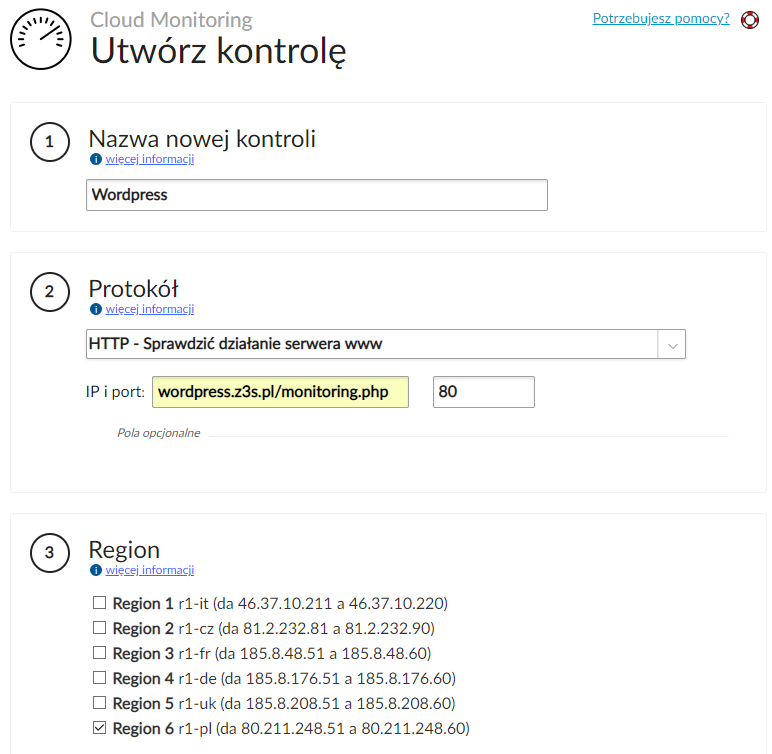
Istotny jest też wybór regionu, z jakiego monitoring będzie realizowany. Jeżeli monitorujemy instancje uruchomione w ramach Aruba Cloud, to do monitoringu warto wskazać inne regiony niż te, w których zostały uruchomione nasze zasoby. Dla każdego z regionów podana jest pula adresów IP, z jakich wykorzystaniem przeprowadzane będą testy dostępności. Warto to uwzględnić podczas konfiguracji naszej aplikacji, aby link wykorzystywany do monitorowania był osiągalny tylko z wybranej puli adresów Aruba.
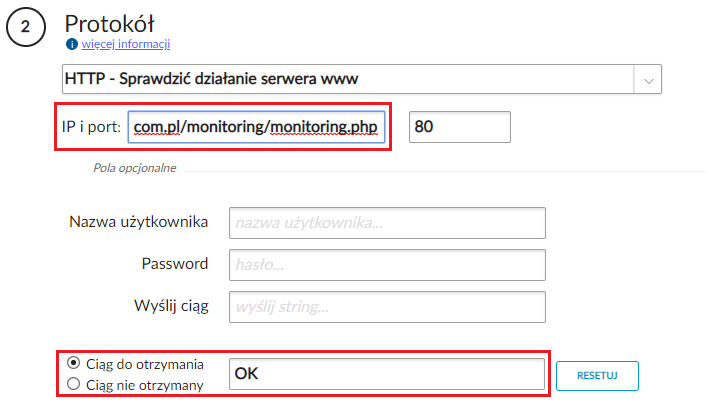
Poza samym prostym sprawdzeniem odpowiedzi od serwera, w ustawieniach opcjonalnych (widocznych po kliknięciu na napis Pola opcjonalne) możemy ustawić dodatkowe parametry monitorowania takie jak: nazwę użytkownika / hasło (jeżeli wywołanie domeny lub URL-a będzie wymagało logowania) oraz wysyłany ciąg znaków. W przypadku wysyłania odpowiedniego żądania oczekiwać będziemy właściwej odpowiedzi (np. kod 200 lub fraza zwracana na podstronie, jaką może generować nasz lokalny skrypt sprawdzający), oznaczającej poprawność działania całego systemu:
Na koniec ustawiamy parametry związane z interwałami testów, długością timeouta oraz ilością wystąpień awarii, które wywołają wysłanie powiadomienia. Oczywiście minimalnie musimy podać jeden adres e-mail, na który powiadomienia będę wysyłane:
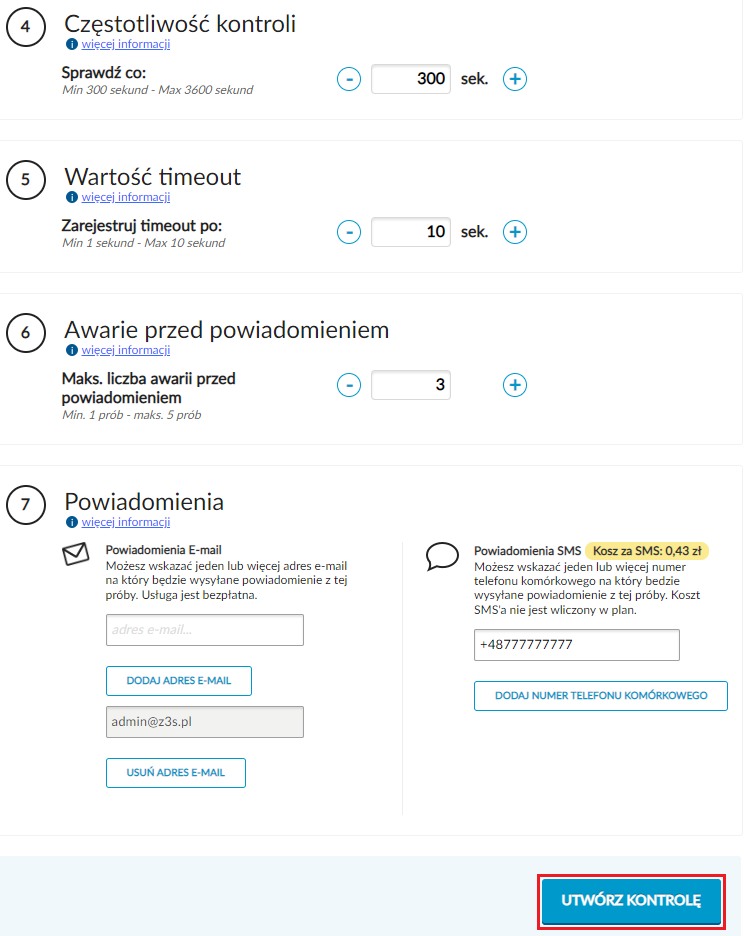
Monitoring
Każdorazowo, gdy skonfigurujemy usługę związaną z zapewnianiem wysokiej dostępności, niezbędne jest jej przetestowanie. W przypadku wykonywania backupu należy go zawsze próbnie odtworzyć, a klaster wysokiej dostępności ręcznie przełączyć. Nie inaczej jest w przypadku systemów monitorowania – jeżeli dla usługi HTTP skonfigurowaliśmy kontrolny ciąg znaków, jaki dostarcza nasza aplikacja, to taką regułę warto zweryfikować. Jeżeli żadnego testu nie przeprowadzimy, to w wyniku naszego błędu system monitoringu może odbierać ciąg danych inny niż ten, jaki założyliśmy. W związku z tym nasza reguła może być zawsze prawdziwa, przez co w sytuacji problematycznej nie otrzymamy stosownego powiadomienia.
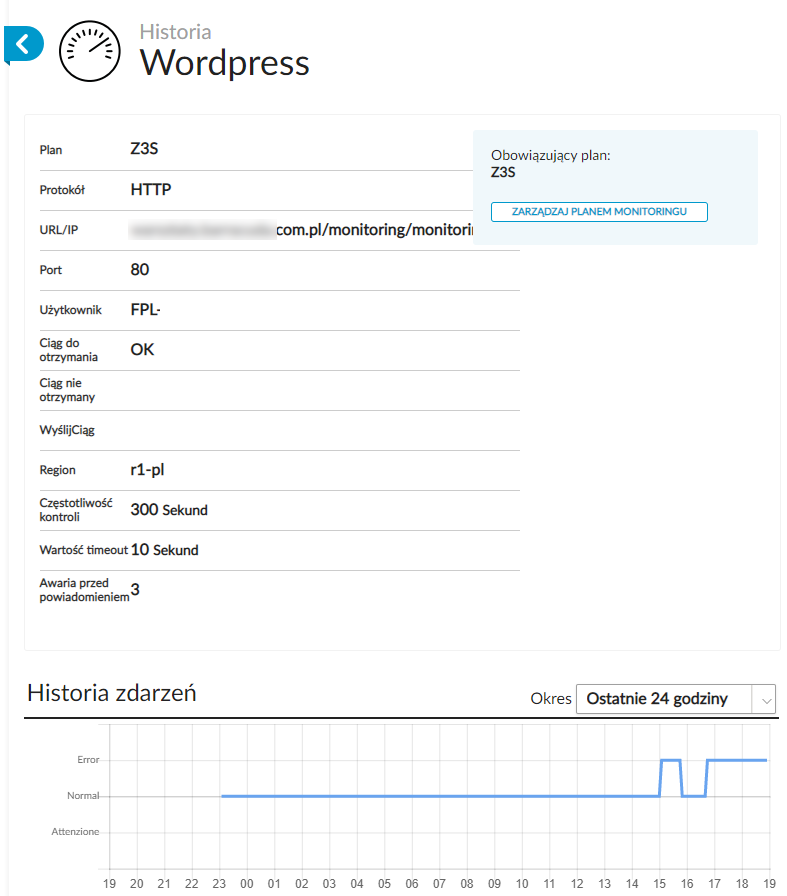
W naszym ,,testowym” przypadku oczekujemy, że odpytanie odpowiedniego URL-a (http://z3s.pl/monitoring/monitoring.php) zwróci wartość ,,OK” w treści strony:
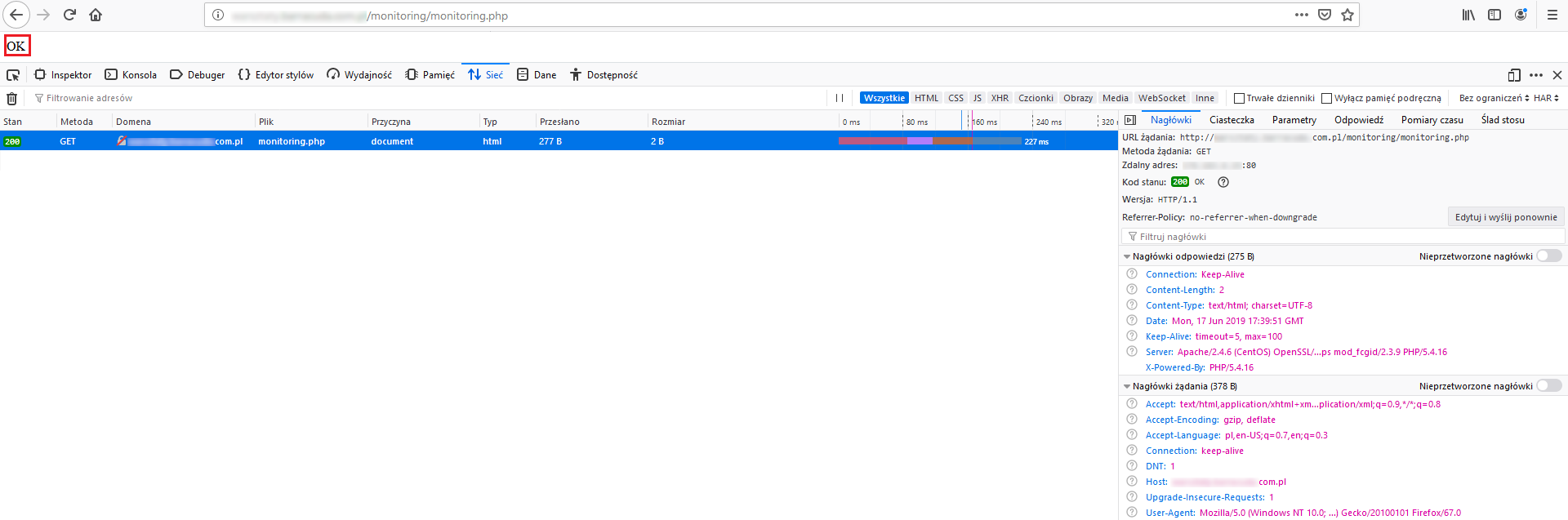
W związku z tym modyfikujemy naszą regułę, podając dla niej wartość, jaka nigdy nie będzie spełniona (np. ,,TEST”):
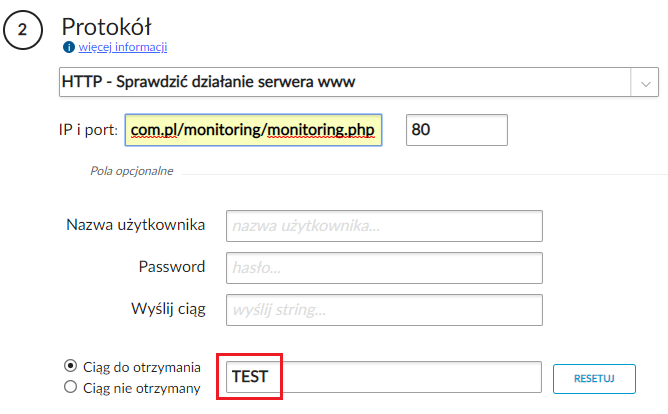
Następnie czekamy przez wcześniej skonfigurowany okres czasu, po którym powinniśmy otrzymać stosowne powiadomienie (e-mail lub SMS):
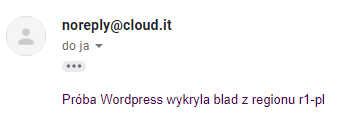
Poza otrzymywaniem powiadomień Aruba Cloud Monitoring dla każdej z kontroli zapewnia dostęp do osobnych statystyk dostępności monitorowanych usług:
Podsumowanie
Monitorowanie naszych usług czy zasobów możemy realizować na wiele różnych sposobów. Samo dobranie właściwego mechanizmu i wdrożenie go w ramach odpowiednio przygotowanej platformy stanowi nierzadko duże wyzwanie. W bardzo wielu przypadkach podstawowe mechanizmy monitorowania zasobów są zapewniane bezpłatnie przez dostawcę chmury. Nie wszystkie jednak działają w sposób automatyczny lub w domyślnej konfiguracji weryfikują tylko stan pracy samej instancji, co w kontekście funkcjonowania aplikacji może okazać się niewystarczające. Dlatego budując wysokodostępne aplikacje działające w oparciu o niezawodne i nadmiarowe platformy nadal musimy pamiętać o zapewnieniu im właściwego nadzoru.




Komentarze
W przypadku stron lepiej sprawdzac po frazie kluczowej – jesli jej nie bedzie to albo serwer webowy nie zyje albo czesto baza danych.. sam kod odpowiedzi jest bez sensu bo aktualny WordPress na stronie glownej zwraca 200 przy jednoczesnym komunikacie ze strona ma problemy techniczne.
W przypadku aplikacji web monitoring powinien się odbywać za pomocą automatycznych testów e2e. Po prostu cyklicznie sprawdzane są biznesowe przypadki użycia aplikacji np. logowanie, dostęp do strony profilu itp.
Opiszcie może jak to zrobić po swojemu bez używania Aruby. Wiem, że Wam płacą, ale odkąd ceny są takie jakie są to nie jest opłacalne tam branie czegokolwiek.