
Ten tytuł może być przez Was słusznie uznany za małe nadużycie, gdyż w zasadzie jego wytłumaczenie przypomina słynny dowcip o rowerach na Placu Czerwonym. Ani nie „rozwaliłem” niczego, ani tym bardziej „Trzecią Zaufaną Stronę”, za to „wdrożyłem rozwaloną usługę słuchania podcastów” z Klubu Bezpiecznika (o którym to Adam Sharkle trąbi już od jakiegoś czasu na lewo i prawo, a zapisy kończą się już 30 września, w najbliższy poniedziałek). Jednak ze względu na to, że wpis ten przedstawia w jakimś zakresie prace w Zaufanej od kuchni, postanowiłem go umieścić w już istniejącej serii, której poprzednią część można przeczytać, klikając tutaj.
Wprowadzenie do Mechanizmu Działania Podcastów – Tom 1
Aby w pełni zrozumieć zaistniałą sytuację, należy odpowiedzieć sobie na pytanie „Czym są podcasty?”. Jeżeli myślicie, że to po prostu w jakiś sposób osadzone pliki audio w serwisach streamingowych pokroju Spotify, to macie rację. Jednakże samo dostarczanie tych plików audio serwisom (lub też bezpośrednio użytkownikom końcowym, jak w tym wypadku) może dokonywać się np. poprzez kanały Atom lub RSS. To mocno ułatwia życie, kiedy stron do słuchania podcastów, które wymagają aktualizowania z naszej strony, mamy przynajmniej kilka. Takim podcastowym hostingiem mogą być płatne usługi typu Buzzsprout albo samodzielnie hostowane aplikacje jak Castopod.
Jeżeli podcast ma być ogólnodostępny, to oba wymienione rozwiązania sprawdzą się bardzo dobrze. Kiedy jednak dostęp do podcastów ma być przyznany tylko wybranym osobom, to Castopod jest rozwiązaniem bardziej elastycznym, chociaż nie bez wad (bo napisany w PHP 😉). W przypadku, gdy podcasty mają być elementem Klubu Bezpiecznika, wystarczy po prostu wygenerować losowe kody dostępu oraz linki Atom dla każdego klubowicza, a potem rozesłać je mailowo. Buzzsprout do tego się nie nadaje, gdyż działa na zasadzie zwykłego paywalla – przejście przez bramkę płatności jest jedyną możliwością odblokowania podcastów.
Otrzymany osobisty kanał Atom to oczywiście plik w formacie bazującym na XML-u. W Castopodzie, w przypadku ogólnodostępnego podcastu (np. Rozmowa Kontrolowana), wystarczy wykonać żądanie GET na adres URL https://podcast.zaufanatrzeciastrona.pl/@rozmowakontrolowana/feed.xml. Tam na tacy otrzymujemy tytuły odcinków, ich opisy, miniaturki, linki do plików MP3, jednym słowem – wszystko.
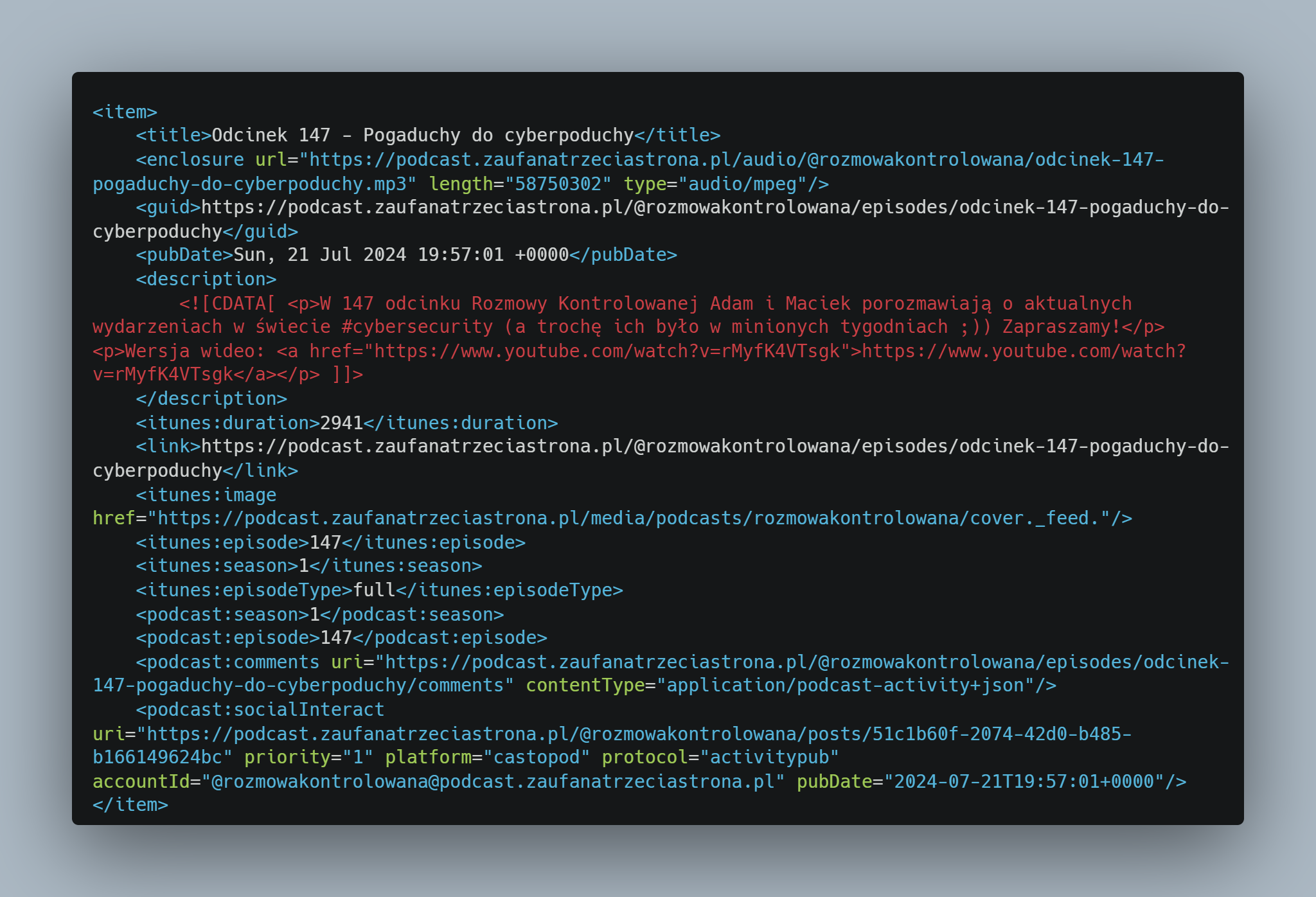
Trochę inaczej wygląda to w przypadku podcastów „premium” – trzeba dodatkowo podać osobisty token dostępu w żądaniu (tutaj przykładowo jest to POMIDOR): https://podcast.zaufanatrzeciastrona.pl/@kb/feed.xml?token=POMIDOR. W odpowiedzi dostaniemy również spis wszystkich odcinków, lecz z drobną różnicą – przy każdym pliku MP3 zostanie dopisany ten sam token z naszego żądania. Błędny token lub jego brak nie wygeneruje listy odcinków, a zwróci tylko bardzo podstawowe informacje o podcaście.
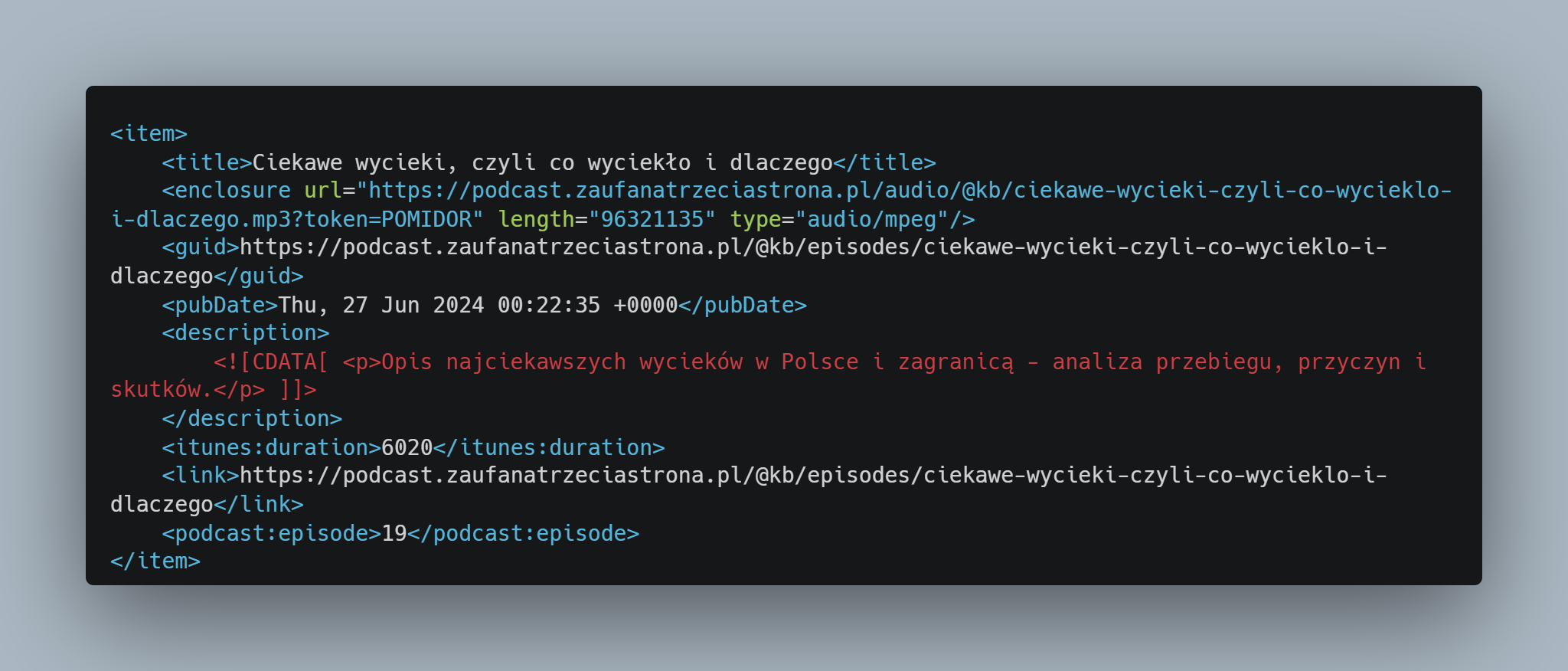
W wielkim skrócie – odpytując feed.xml z tokenem POMIDOR, powinniśmy otrzymać pliki audio z tokenami POMIDOR, a bez tokenu nie powinniśmy dostać niczego. Myślę, że to dość jasne i oczywiste.
Ludzie, ludzie, zwariowałem, podcasty rozdaję…
O dostępie do webinarów-podcastów warto było Klubowiczów jakoś poinformować, więc 29 lipca Adam Herrkle odpalił newslettera promującego nową funkcjonalność. Od razu w logach zauważyłem falę żądań o tokeny dostępowe. To super – newsletter działa, cyferki robią brrr, wszyscy zadowoleni, prawda?
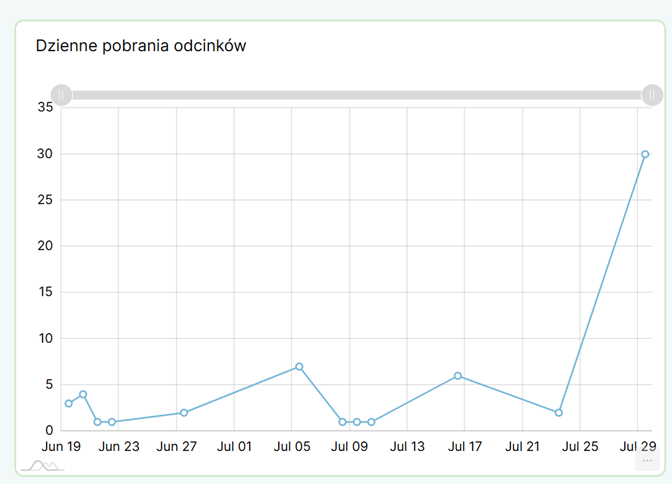
Jednakże gdy w statystykach Castopoda zajrzałem do sekcji „pobrania odcinków według odtwarzacza”, zrobiło się ciekawie.
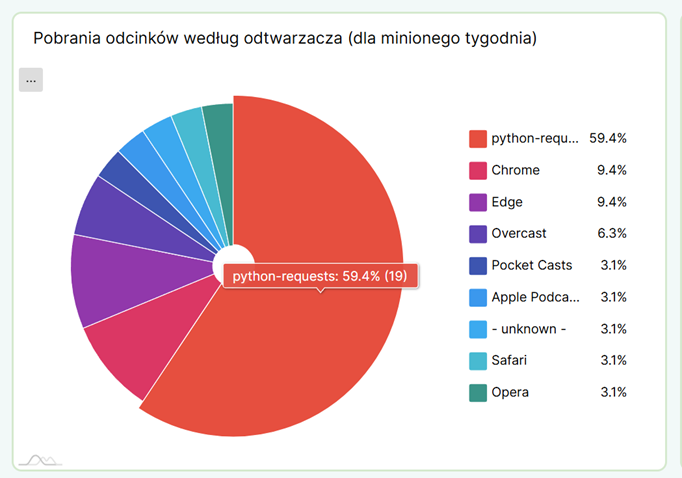
Ups, wygląda na to, że ktoś zrobił sobie nieautoryzowaną kopię zapasową Klubowych odcinków. Przynajmniej będzie od kogo się przywracać w razie awarii. Z ciekawości postanowiłem ustalić, który to z Klubowiczów dokonał tego niezwykle karygodnego czynu, którego skutki wyrządziły trudną do powetowania szkodę. To teoretycznie powinno być bardzo proste: Castopod przecież loguje każde wysłane do niego żądanie, w tym osobisty token użytkownika, a każdy token zaś przypisany jest do adresu e-mail Klubowicza. Żadna filozofia.
Dla uproszczenia przyjmijmy, że jednym z tokenów, którymi się posługiwano, był OGÓREK. Format logów Castopoda wygląda następująco:

Adres IP może wydawać się lokalny i taki też faktycznie jest. Kontener Castopoda jest wystawiony na świat poprzez inny kontener – tunel Cloudflare (cloudflared), a oba istnieją w ramach jednego stacku Dockera. Castopod w standardowej konfiguracji tego nie rozumie i loguje w kółko adres kontenera-proxy, co zaburzyło czytelność logów i utrudniło mi ich analizę. Na szczęście logów do przeglądania nie było za dużo. Jak to mówią, jest dobrze, ale nie beznadziejnie.
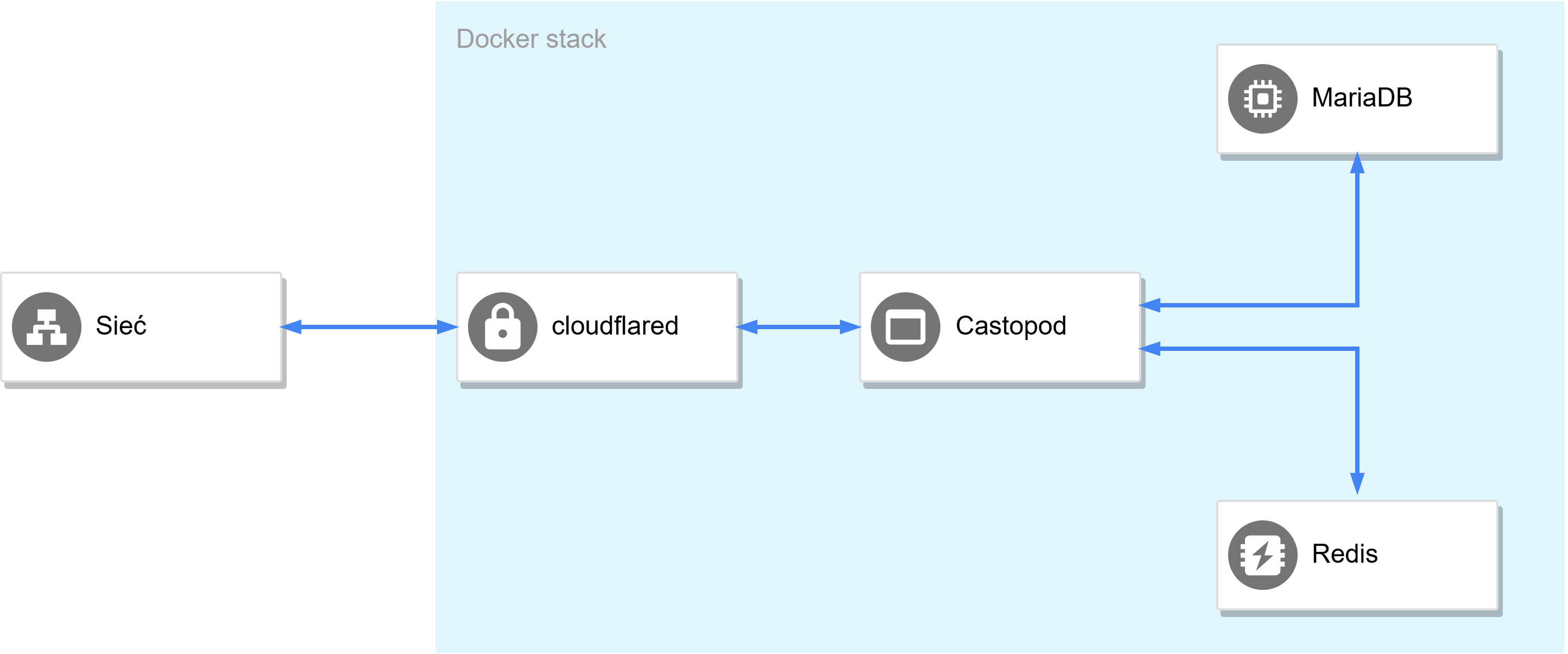
cloudflared.Wracając do analizy logów – wiemy, że z python-requests korzystała osoba, która wcześniej otrzymała token OGÓREK. Kto dostał token OGÓREK? Ponieważ Castopod przechowuje w bazie danych tokeny dostępowe zahashowane SHA256, wystarczy przepuścić OGÓREK przez funkcję i mizerię hash porównać z bazą danych.
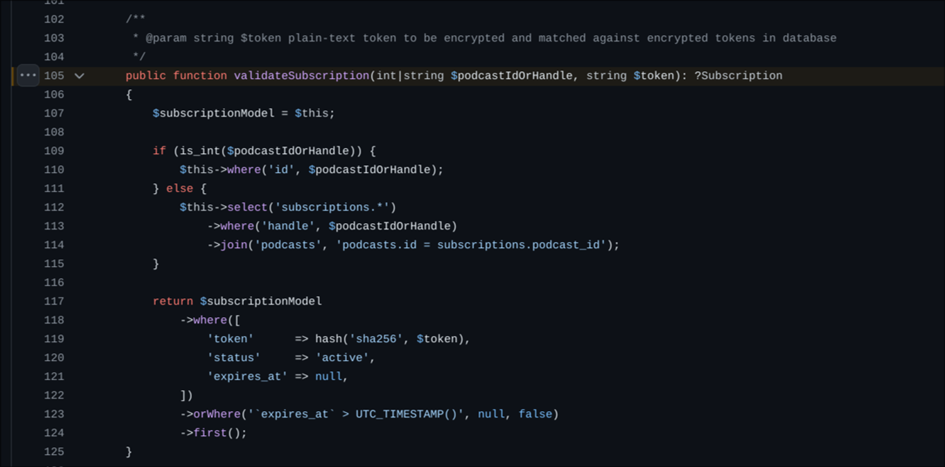
Hash więc wziąłem i porównałem. Zonk. To był mój token.
Czy przypadkiem o poranku sam sobie zescrapowałem podcasty Pythonem i tego nie zapamiętałem? Może jednak jest jakieś inne, racjonalne wytłumaczenie? W głowie zaczęły rodzić się różne scenariusze…
SQL Injection lub inna podatność 0-day w Castopodzie
W miarę przeglądania logów odkryłem, że python-requests pobierał podcasty nie tylko z mojego tokenu. Część była pobierana także z tokenu innego użytkownika, który w bazie danych był „obok mnie”. To mi zasugerowało, że może ktoś chciał mi zagrać na nosie, tylko najpierw nie trafił w ten hash, co trzeba? To jednak nie miało sensu – token jest generowany losowo i dwunastoznakowy, więc kilkadziesiąt sekund na pobranie hashy z bazy, odpalenie Hashcata i odwrócenie chociażby jednego z nich to trochę mało. Odpada.
Zawiódł system wysyłania kodów
System wysyłania kodów nie był skomplikowany – użytkownik wchodził na ustalony adres, podawał swój adres e-mail, naciskał „Wyślij” i jeżeli adres znajdował się w Klubowej bazie, to wysyłany był tam kod dostępu. Ten system sprawdził się już wielokrotnie i nigdy nie zawiódł. Awaria też nie tłumaczyłaby tego, że jeden użytkownik posługiwał się kilkoma różnymi tokenami. Ponadto zweryfikowałem w logach poczty, że każdy z użytkowników dostał tylko jednego maila. To nie to.
Fizyka czarnej dziury albo czary (cache Cloudflare)
W pewnym momencie zacząłem się zastanawiać, czy to nie cache Cloudflare coś miesza. Sprawdziłem ustawienia – były prawidłowe (Caching Level – Standard). Każde zapytanie z różnymi parametrami w URL-u traktowane było osobno i takowo cachowane. Patrząc po nagłówkach potwierdziłem, że Cloudflare nie cachuje zapytań do feedów. To nie jego wina.

feed.xml. Cloudflare mądrze wykrywa i wyłącza na takich endpointach cachowanieLogujcie i czytajcie logi
Jeżeli nie wiadomo, co robić, to trzeba czytać logi, jeżeli oczywiście się je posiada, a w takich momentach są naprawdę na wagę złota. Jest to praca żmudna i raczej nieprzyjemna, ale za pomocą byle notatnika można próbować odtworzyć zdarzenie z perspektywy włamywacza Klubowicza. Ponieważ Castopod błędnie logował adres IP requestów, trzeba było pivotować między logami różnych usług (głównie Cloudflare) za pomocą useragenta, parametrów HTTP czy też nawet dokładnych czasów żądań. Powoli poskładałem logi w całość i ostatecznie udało się odtworzyć całą historię.
- 7:30 UTC – wysyłka e-maili dla członków Klubu Bezpiecznika z informacją o dostępnych webinarach jako podcastach.
- 07:44:59 – pierwsze masowe requesty z UA
python-requests/2.32.3oraz tokenem POMARAŃCZA.
Token POMARAŃCZA to oczywiście przykład kolejnego tokenu. Odszukałem więc w logach wszystkie wpisy, które dotyczyły tokenu POMARAŃCZA.
- 07:32:51 – token POMARAŃCZA przypisany użytkownikowi w bazie danych i wysłany mailowo.
- 07:33:18 – Intel Mac OS X wykonuje żądanie GET
/@kb/feed.xml?token=POMARAŃCZA.
W tym miejscu warto nadmienić, że z tego samego useragenta pojawiały się raz żądania z lokalnego ISP, a raz z NordVPN. Moim zdaniem trochę bez sensu jest używać VPN-a, skoro tokeny są związane z adresami e-mail – zmiana IP w tym wypadku nic nie daje. A skoro o VPN-ach mowa, to tylko ZaufanyTrzeciVPN – tutaj link do promocji na -40% (oferta ważna do wyczerpania zapasów magaynowych).
- 07:37:15 – token POMARAŃCZA użyty po raz pierwszy z useragentem wskazującym na Pythonową bibliotekę
feedparser, gdzie IP wskazuje na sieć Hetznera. Nadal odpytujefeed.xml. - 07:41:08 – token POMARAŃCZA użyty z useragentem przedstawiającym się jako MindMac – Macowym klientem do przeróżnych LLM-ów i innych AI-cudów. Czyżby odpalenie promptu „Hejka czat pkp, pobierz mi wszystko z tego xmla z linka”?
- 07:44:59 – pierwsze masowe requesty do plików MP3 podcastu @kb z
python-requestsz tokenem POMARAŃCZA. - 07:45:55 – z Maca pobrano kolejną listę odcinków podcastu dla Klubowiczów –
/@studio/feed.xmlz tokenem POMARAŃCZA. - 07:46:15 – z UA
python-requestsmasowo pobierano pliki MP3 z @studio z jeszcze innego, cudzego tokenu. - 07:46:40 – z Maca pobrano listę
/@archiwum/feed.xmlz tokenem POMARAŃCZA. - 07:47:10 – z UA
python-requestsmasowo pobierano pliki MP3 z @archiwum z tokenu OGÓREK, przypisanego do mojego adresu e-mail.
Trochę ponad wenta między zapytaniami o kanały Atom podcastów a pobraniami odcinków raczej nie wskazuje na włamanie, chociaż tyle wystarcza, aby dostać się do półfinału mistrzostw w piłce ręcznej. Dość łatwo jest zauważyć pewną prawidłowość – ktoś na Macu pobiera listę odcinków, a potem hurtem zaciąga z niej empetrójki. Do pobrania listy używa jednego tokena, do odcinków – różnych. Jak? Dlaczego? Skąd?
Postanowiłem wykonać te same kroki, jakie wykonał Klubowicz. Odpytałem więc po prostu feed.xml któregoś z podcastów, żeby sprawdzić, co się stanie. Tym razem moją uwagę przykuły nie nagłówki odpowiedzi (tak jak wtedy, kiedy sprawdzałem wariant „cache Cloudflare”), a po prostu sama odpowiedź serwera. Myślę, że zrzut ekranu ze sprawozdania na gorąco na temat incydentu tłumaczy wszystko.
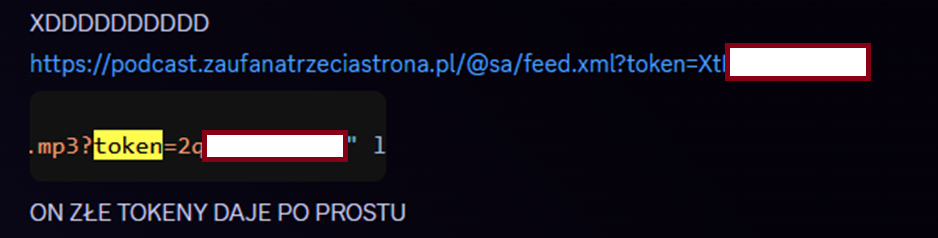
Tak. Pytając Castopoda o podcasty premium z własnym tokenem, dostawało się w odpowiedzi pliki audio z tokenem zupełnie innym. Co ciekawe, serwer odpowiadał jednym i tym samym tokenem, niezależnie od żądania. Dlaczego? Nie było to wtedy jeszcze jasne, ale przynajmniej udało się namierzyć winowajcę. Nie było żadnego włamu, można odsapnąć.
A gdyby się tak pobawić bardziej tym tokenem? Co się stanie, jeżeli wpiszę byle co?

Niedobrze. Oprócz tego, że tokeny w żądaniu i odpowiedzi nie zgadzały się ze sobą, to jeszcze wystarczyło podać dowolny ciąg, aby uzyskać dostęp do zablokowanych podcastów. Czyżby kolejny błąd w kodzie Castopoda? Czy inne instancje Castopoda cierpiały na podobną przypadłość? Niezależny ekspert Adam Hermes kilka przetestował i wszystkie zdawały się reagować prawidłowo…
Może źle coś wdrożyłem? Może nie zaznaczyłem jakiejś magicznej opcji? W końcu to PHP, tu wszystko robi się inaczej… Wiedziałem za to, że sam już nie dam rady, więc postanowiłem napisać do jednego z maintainerów Castopoda.
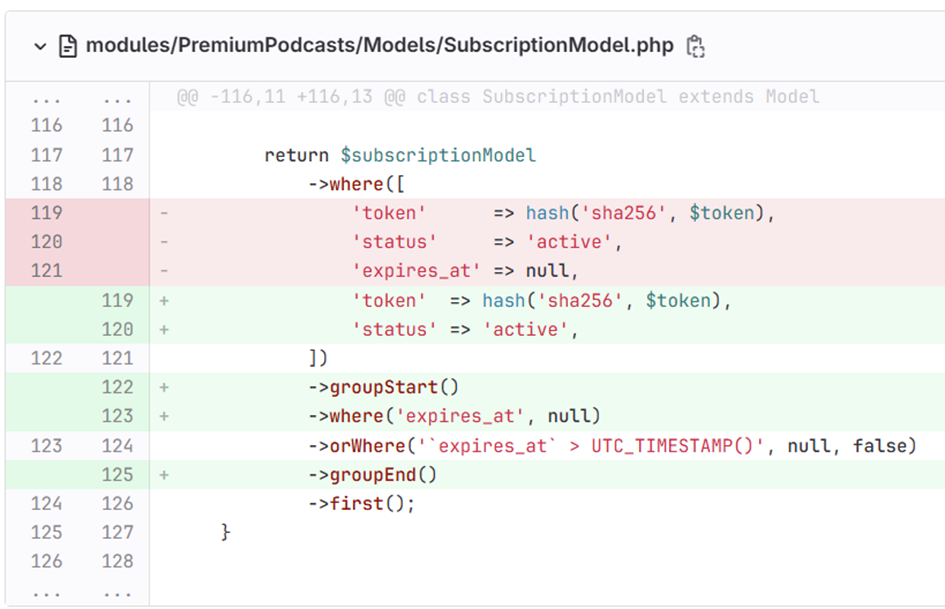
Jak się okazało – tak, odkryłem dwa osobne błędy w Castopodzie. Jeden z nich znajdował się w tym miejscu, na które uwagę zwrócił wcześniej mój kolega @unx (oklaski!). Po moim zgłoszeniu szybko została wydana aktualizacja poprawiająca sprawdzanie ważności tokenów.
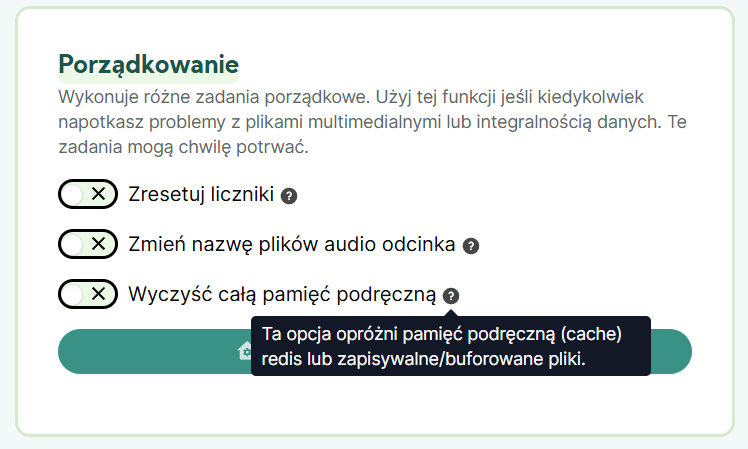
Połowa sukcesu w garści, a co z mieszaniem tokenów? Castopod posiada swój własny system cache, do którego opcjonalnie można podpiąć Redisa. Co się stanie, gdy go wyczyszczę?
Naprawiło to mieszanie tokenów, ale tylko jednorazowo. Przy wykonywaniu po kolei zapytań z różnych tokenów, serwer zawsze zwracał zapamiętany „początkowy” token. Uzupełniłem więc swoje zgłoszenie błędu i już po niecałej godzinie wydano kolejną aktualizację rozwiązującą ostatni problem.
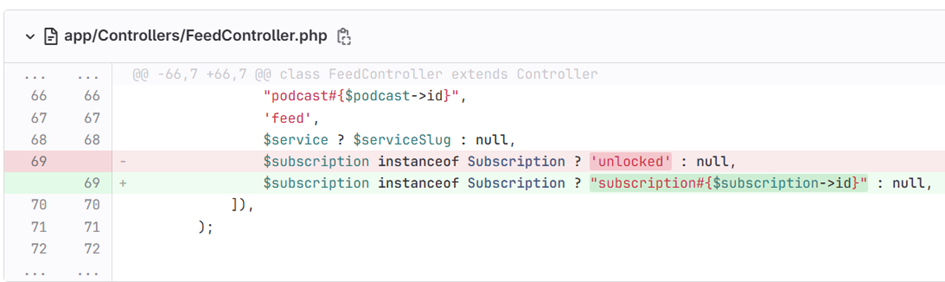
feed.xml bez względu na to, z jakimi parametrami o niego pytanoPo wprowadzeniu obu tych aktualizacji na produkcję wszystko wróciło do pożądanego stanu. Szkoda tylko, że dopiero nasza produkcja musiała przetestować dokładniej funkcję „podcastów premium”. Na uwagę zasługuje fakt, że znalezione błędy występowały w kodzie przynajmniej rok i nikt nie zauważył, że coś tu jest nie tak…
Błędy oczywiście się zdarzają, a podcasty dla wybranych to raczej dość niszowa funkcjonalność. Byłem zbyt mocno przyzwyczajony do tego, że aplikacje z Internetu po prostu działają i nie trzeba ich pentestować ani fuzzować przed wdrożeniem (o ile można nazwać tak proste zabawy z podmianą tokenów w żądaniach). Dodatkowo repozytorium projektu ma ponad 600 gwiazdek na GitHubie, więc na pewno ktoś to sprawdził, przetestował i zatwierdził, prawda?

Koniec końców, na pochwałę zasługuje błyskawiczna reakcja maintainera Castopoda na moje zgłoszenia. Gratulacje także dla @unx za poprawne wytypowanie przyczyny jednego z problemów, a także za pełnienie roli Kaczki Debugaczki.
Z wniosków: pamiętajcie o logach – logujcie wszystko, co się rusza, a jak się nie rusza, to też logujcie, bo nie zaszkodzi. Fajnie, gdyby te logi raportowały również poprawne adresy IP. Oczywiście do logów warto także zaglądać, gdyż nieczytane i nieoskryptowane alertami nic nie wnoszą.
A to, że tych błędów na innych instancjach Castopoda nie było… No cóż, widocznie właściciele ich nie aktualizowali i nie zdążyli jeszcze pobrać podatnych wersji.

PS. Tekst ten powstał tylko dlatego, że inny Klubowicz postanowił pożyczyć wszystkie odcinki podcastów. Same webinary jako podcasty powstały zaś dlatego, bo jeden z Klubowiczów zrobił szum w logach, próbując zrobić podcasty z webinarów na własną rękę. Do wniosków można więc dopisać „warto rozmawiać z klientami”. A content robi się sam!



Komentarze
błąd został wykryty ponieważ osoba wykonująca kopie nawet nie próbowała tego ukryć
gdyby nie specyficzny UAS nie byłoby tak łatwo
oczywiście można próbować nałożyć jakiś rate limiter, ale może to zaszkodzić jeśli klient będzie chętnie buforować wszystko, na co wskażemy
Ładnie. Jak aplikacja zwraca 500, to każdy znajdzie błąd. Gorzej, kiedy działa tak dobrze, że aż za dobrze.
Hehe, już myślałem, że poszliście w ślady Piotra z Nordem :)
Swoją drogą, to brakowało mi guzika „pobierz” przy każdym podcaście. Łatwiej mi słuchać w drodze do roboty mp3 wrzucone na pena lub CD, niż odpalać w aplikacji. Ale to nie byłem ja.
Teoretycznie wystarczy skorzystać z losowej aplikacji, która ogarnia importowanie podcastów lub innego „Podcast Downloadera” i wklepać link do „Kanału RSS Podcastu” (który w zasadzie nie jest RSSem, tylko Atomem…) spod guzika na tej stronce https://podcast.zaufanatrzeciastrona.pl/@rozmowakontrolowana/episodes. :)