Firmy, również polskie, chętnie przechowują zebrane przez siebie dokumenty w chmurze Amazona ze względu na nielimitowaną powierzchnię. Niefrasobliwość części z nich prowadzi jednak do mniej i bardziej poważnych wycieków.
Mówimy o jednej z podstawowych usług działających w ramach Amazon Web Services, czyli o możliwości przechowywania rozmaitych danych w tzw. kubełkach (z ang. bucket). Simple Storage Service, w skrócie S3, jest usługą prostą w obsłudze i tanią, a przez to popularną. Firmy używają jej do składowania backupów, logów i różnych dokumentów, w tym także zebranych od klientów. Nie zawsze jednak poprawnie je zabezpieczają. Pod koniec lipca opisaliśmy przypadek publicznego udostępnienia 46 tys. poufnych plików przez firmę eRzeczoznawcy. Dziś wracamy z innym przykładem znalezionym przez naszych Czytelników.
Wyszukiwarka otwartych kubełków znów w akcji
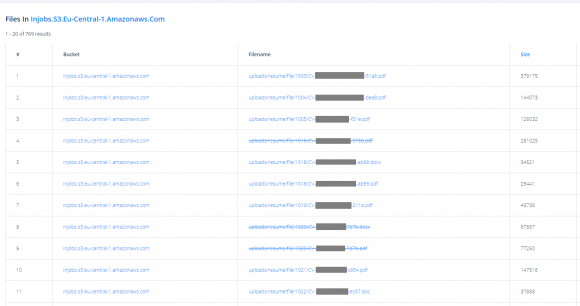
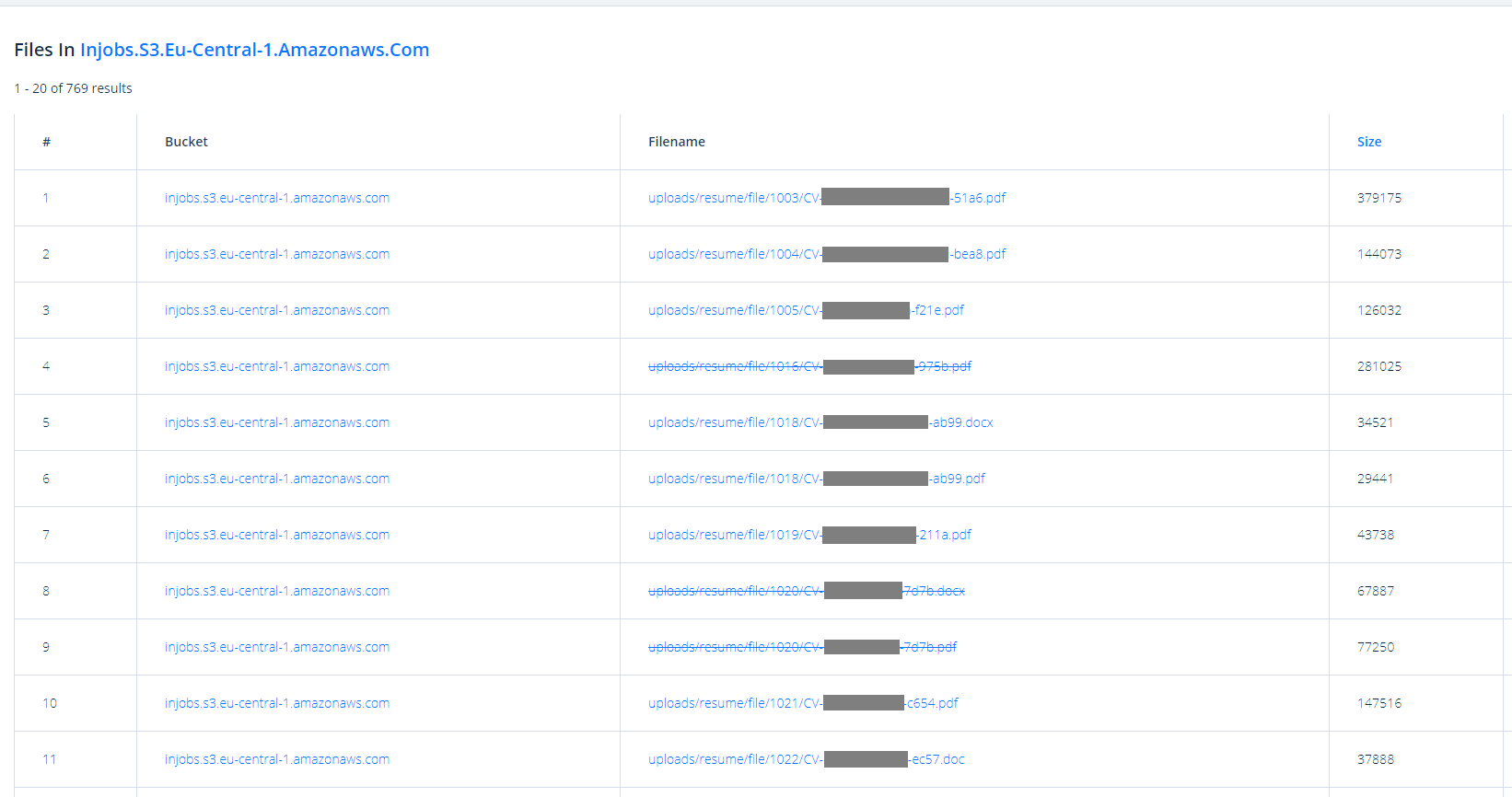
W poprzednim artykule pokazaliśmy wyszukiwarkę buckets.grayhatwarfare.com – można z jej pomocą przetrząsnąć chmurę Amazona i namierzyć publicznie dostępne kubełki. Wielu z Was postanowiło ją przetestować. Wśród zgłoszeń, które zaraz potem otrzymaliśmy, kilkakrotnie powtórzyła się nazwa firmy InJobs.pl, która prowadzi serwis z ofertami pracy w Polsce, Niemczech, Holandii, Francji i innych krajach UE. Zajrzeliśmy do kubełka, który nie bez powodu wzbudził Wasze zainteresowanie. Znaleźliśmy w nim 769 plików w formatach .pdf, .doc, .docx i .odt, zawierających zawodowe życiorysy znacznej liczby osób. Nie wszystkie dało się otworzyć, niektóre osoby dostarczyły firmie CV w paru formatach. Pewne jest jedno – żadna nie chciałaby, by jej dane stały się dostępne do pobrania dla każdego.
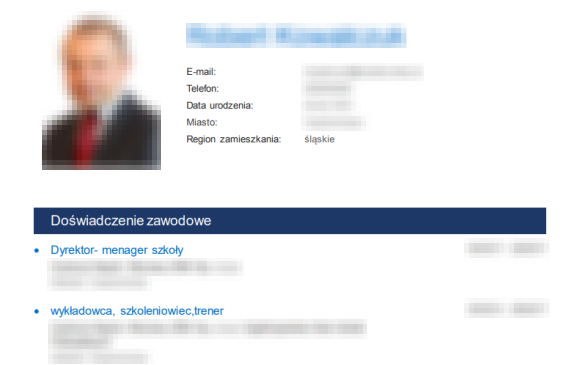
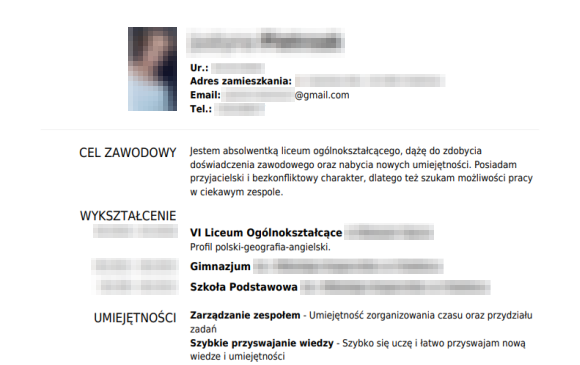
Poniżej zamieszczamy kilka przykładów wziętych na chybił trafił życiorysów, które były dostępne w kubełku należącym do firmy InJobs.
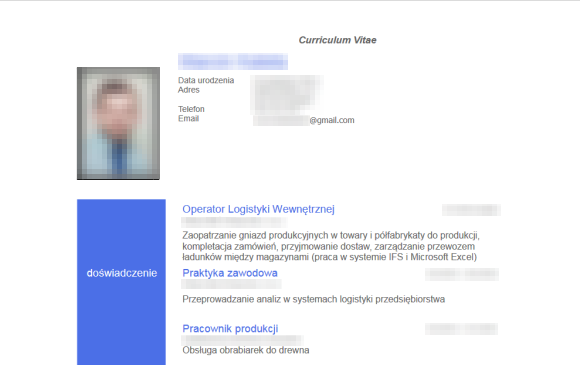
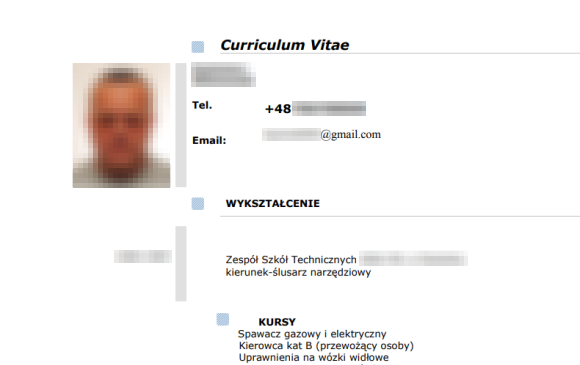
Poprawna reakcja firmy
Jak zwykle w podobnych przypadkach, nawiązaliśmy kontakt z firmą, której dotyczył problem. W piątek późnym południem wysłaliśmy powiadomienie o zaobserwowanym wycieku danych. W poniedziałek około godz. 11 otrzymaliśmy pierwszą wiadomość świadczącą o tym, że firma InJobs zapoznała się z naszym zgłoszeniem. Następnego dnia rano dostaliśmy potwierdzenie, że publicznie dostępne informacje „zostały zaszyfrowane i są przenoszone” – sprawdziliśmy, tak właśnie było.
Wysłaliśmy parę pytań, m.in. o to, czy firma zawiadomiła o tym incydencie UODO i osoby, które powierzyły jej swoje życiorysy. Ciekawiło nas także, jakie InJobs podjął kroki w celu zapobiegnięcia podobnym zdarzeniom w przeszłości. Dziś dotarła do nas następująca odpowiedź:
Zostały podjęte wszystkie niezbędne kroki przewidziane procedurami określającymi zabezpieczenie danych, jak i przekazanie odpowiednich informacji do osób i instytucji.
Po wykonaniu zabezpieczeń zleciliśmy audyt bezpieczeństwa danych dla firmy zewnętrznej.
Nasze działania skutkują ponadprzeciętnym bezpieczeństwem danych, a to miało charakter incydentalny.
Jak zapobiegać tego typu incydentom
O skomentowanie zaistniałej sytuacji i udzielenie kilku rad na przyszłość poprosiliśmy eksperta w zakresie rozwiązań chmurowych. Podjął się tego Paweł Rzepa, starszy specjalista ds. bezpieczeństwa w firmie SecuRing.
Błędy kontroli dostępu do zasobów towarzyszą usłudze AWS S3 od początku jej istnienia, czyli od 2006 r. Według mojego ostatniego badania aż 21% kubełków umożliwia publiczny dostęp do przechowywanych obiektów.
Dlaczego wciąż tak wiele kubełków oferuje publiczny dostęp?
Należy zwrócić uwagę, że wina źle skonfigurowanego dostępu do zasobów S3 zawsze leży po stronie administratora. Domyślne ustawienia tej usługi dają prywatny dostęp tylko jej twórcy. Aby nadać prawo do publicznego odczytu czy listowania zawartości kubełka, należy włączyć konkretne ustawienie, o czym jesteśmy dobitnie informowani przez dostawcę – komunikatami w samym interfejsie konsoli AWS, a także wiadomością e-mail. Poza tym nadanie publicznego dostępu do wszystkich obiektów w kubełku ma uzasadnienie tylko w jednym przypadku – gdy nasz kubełek hostuje statyczną stronę WWW. W każdym innym przypadku powinniśmy unikać tej formy dostępu.
Z drugiej jednak strony nadanie publicznego prawa odczytu do wszystkich obiektów w kubełku jest najszybszym i najłatwiejszym sposobem żeby zapewnić łatwy dostęp do danych innym komponentom, np. aplikacjom zapisującym czy innym usługom AWS. Często jest to na tyle kuszące dla administratorów, że nie zważają oni na dramatyczne konsekwencje, czyli np. możliwość wycieku poufnych danych. Należy być świadomym, że skonfigurowanie dostępu w myśl zasady najmniejszych przywilejów w skomplikowanych architekturach może być problematyczne, ponieważ istnieją przynajmniej 4 sposoby na definiowanie tych praw dla obiektów S3, tj. przez:
- Polityki IAM (Identity and Access Management policies),
- Polityki kubełka (bucket policies),
- Listy kontroli dostępu (Access Control Lists),
- Podpisane linki URL (pre-signed URLs) bądź uwierzytelnione żądania (query string authentication).
Dostępy te mogą nawzajem się wykluczać, dlatego w źle zarządzanych architekturach nietrudno o błąd.
Ponadto, jeśli doszukiwać się winy za wycieki po stronie Amazona, to można zwrócić uwagę na niepotrzebnie utworzoną grupę „Any authenticated AWS user”. Administratorzy usługi S3 w latach 2006-2017 w interfejsie konsoli AWS mieli możliwość nadania prawa dostępu do kubełka lub zawartych w nim obiektów do użytkowników grupy „Any authenticated AWS user”. Nazwa ta wprowadziła w błąd wielu administratorów, którzy zakładali, że grupa ta obejmuje tylko uwierzytelnionych użytkowników przypisanych do ich konta. Okazało się jednak, że grupa ta nadaje dostęp dowolnemu kontu AWS. W nowym interfejsie konsoli AWS (od połowy 2017 roku) już nie zobaczymy opcji przypisania dostępu użytkownikom tej grupy, jednak nadal możemy to zrobić z poziomu CLI lub zewnętrznych bibliotek do współpracy z AWS, jak np. Pythonowa biblioteka boto. A powołując się na prawo Murphy’ego – co może się wydarzyć, prędzej czy później się wydarzy.
Co robić, by nie stać się kolejną ofiarą wycieku danych?
Konfigurując usługę S3, należy zacząć od zadania sobie pytania, jakiego rodzaju dane chcemy tam przetrzymywać, pamiętając o zasadzie, żeby zakładać jeden kubełek do jednego celu, np. jeśli nasz kubełek ma przetrzymywać pliki użytkowników aplikacji, to nie dodawajmy tam już plików naszego działu HR. Następnie należy określić, kto ma mieć dostęp do tych plików i na tej podstawie zdefiniować dostęp, korzystając z adekwatnego sposobu (polityki IAM, polityki kubełka, listy kontroli dostępu, podpisane linki URL lub uwierzytelnione żądania). Warto też rozważyć szyfrowanie danych przetrzymywanych w kubełku. Amazon oferuje kilka możliwości szyfrowania:
- szyfrowanie kluczem dostarczonym przez administratora (SSE-C),
- szyfrowanie kluczami zarządzanymi przez Amazon (SSE-S3),
- szyfrowanie kluczami zarządzanymi przez administratora w usłudze AWS Key Management Service (AWS-KMS).
Ponadto swoje środowisko chmury należy regularnie audytować. Jeśli chcemy w szybki i łatwy sposób sprawdzić błędy dostępu do naszych kubełków, możemy skorzystać np. z narzędzia BucketScanner.
Jeśli przymierzacie się do korzystania z usługi S3, weźcie powyższe zalecenia pod uwagę. Jeśli natomiast, myszkując w sieci, natraficie na kolejny polski kubełek z danymi, które nie powinny być publicznie dostępne, to możecie nam to zgłosić – postaramy się, by problem został sprawnie rozwiązany.



Komentarze
Lol, fajne. Wysłałem zawiadomienie do jednej kanadyjskiej księgarni, która trzyma swoje książki niezabezpieczone na S3.
Wszyscy Polacy na jednej leżą tacy
Czy tylko ja mam wrażenie, że wszystkie firmy po incydencie unikają odpowiedzi na pytanie „czy firma zawiadomiła o tym incydencie UODO”?