Jeśli braliście udział w jakimś konkursie, to raczej nie oczekiwaliście, że Wasze prywatne dane staną się ogólnie dostępne. Czasem wystarczy jednak mały błąd, by było inaczej, a wpadki zdarzają się nawet największym firmom.
Jeden z Czytelników przesłał nam link do pliku JSON z nadmiarową ilością danych, na który natrafił przypadkiem w sieci. Otóż firma BSH Sprzęt Gospodarstwa Domowego Sp. z o.o. – będąca licencjonowanym sprzedawcą produktów marki Siemens – zorganizowała konkurs „Kocham TO”, w którym można było wygrać podróż swoich marzeń. Zgłoszenia należało wysyłać za pośrednictwem strony www.kocham-to.pl, a jej wykonawcą okazała się firma Insignia Sp. z o.o.
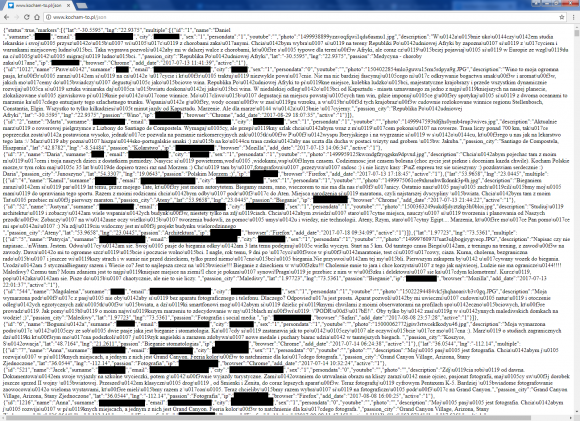
Konkurs zdążył się już zakończyć i wszystko byłoby dobrze, gdyby nie prywatne dane uczestników, z którymi jeszcze kilka dni temu każdy bez wysiłku mógł się zapoznać:
Plik JSON znaleziony przez Czytelnika
Wystarczyło skorzystać z narzędzi dla programistów wbudowanych w przeglądarkę albo otworzyć plik bezpośrednio, jak na powyższym zrzucie ekranu – czytelność nie najlepsza, ale z czymś takim poradzi sobie nawet laik (link można odgadnąć, zaglądając do źródła strony).
Rozmawialiśmy na ten temat z naszymi ekspertami. JSON to jeden z najpopularniejszych formatów wymiany danych w środowisku internetowym. Lekki, bo tekstowy. Łatwy do opanowania, bo korzysta ze składni JavaScriptu. W omawianym przypadku posłużył do wygenerowania mapy na stronie głównej – kliknięcie w widoczne na niej markery pozwala zobaczyć zgłoszenia poszczególnych uczestników konkursu.
Mapa wygenerowana przy użyciu JSON-a
Normalną praktyką jest pokazywanie minimum danych, by nie można było zidentyfikować osób biorących udział w konkursie ani nie dało się z nimi skontaktować. Tutaj programiści zawalili sprawę, bo liczyli na tzw. głębokie ukrycie (choć według niektórych naszych komentatorów znalezienie problematycznego pliku było na tyle łatwe, że nie można w tym przypadku mówić o głębokim ukryciu). Zetknęliście się kiedykolwiek z takim terminem?
Został ukuty w 2010 r., gdy pewien internauta, korzystając z Google’a, przez przypadek znalazł bazę danych dłużników PKO BP. Jak na dobrego obywatela przystało, poinformował o tym bank, a ten… oskarżył go o złamanie zabezpieczeń i próbę szantażu, argumentując, że plik zawierający poufne dane znajdował się w głębokim ukryciu. Niefortunne określenie doczekało się własnego hasła w Wikipedii i funkcjonuje do dziś jako synonim podobnych „zabezpieczeń”.
Wykonawcy konkursowej strony najwyraźniej nie przewidzieli, że ktoś może zerknąć na jej kod i zapytania, które ona wykonuje. Ich niefrasobliwość spowodowała, że potencjalni atakujący zyskali dostęp do danych osobowych uczestników konkursu, takich jak nazwisko (które miało pozostać niejawne), miasto zamieszkania, adres IP (który w pewnych przypadkach GIODO uznaje za dane osobowe) oraz e-mail. Zastanówmy się, jak można je wykorzystać.
Możliwy scenariusz ataku
Najprościej byłoby założyć konto e-mail w domenie przypominającej konkursową (albo od razu podszyć się pod firmę Siemens) i rozesłać do uczestników informację, że wygrali i muszą w związku z tym podać więcej danych. Można spróbować wyłudzić w ten sposób np. skan dowodu osobistego czy poprosić o PIT (istnieje bowiem możliwość zaciągnięcia w banku kredytu na PIT – przedsięwzięcie karkołomne, ale wykonalne). W tym drugim przypadku atakujący może się dodatkowo pokazać jako osoba godna zaufania, ostrzegając „proszę nie przesyłać skanu dowodu, bo to niebezpieczne” – wiadomo, z3s też przed tym ostrzega.
Jak podkreślają nasi eksperci, wszystko zależy od wyobraźni atakującego i jego umiejętności. Gdyby konkurs jeszcze trwał, można byłoby się też pokusić o wysłanie zgłoszenia z kodem XSS (sprawdzenie, czy da się w kontekście atakowanej aplikacji wykonać nieautoryzowany kod). Jak już pisaliśmy, dane z JSON-a są wstrzykiwane na stronę główną. Nie wiadomo, czy programiści pamiętali o filtracji – teraz już tego nie sprawdzimy.
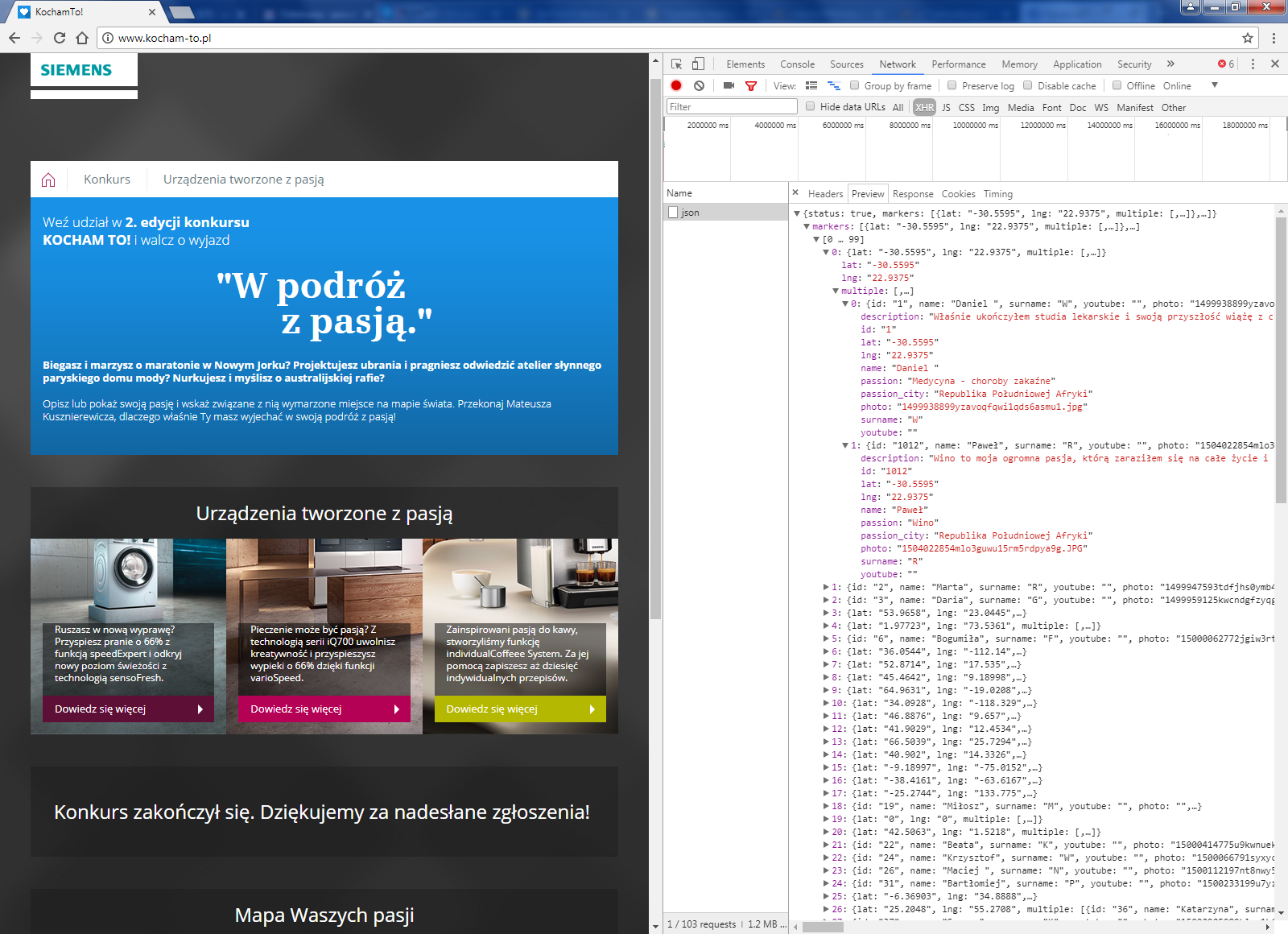
Problematyczny plik po wprowadzeniu poprawek
Błąd został naprawiony
Jak możecie zobaczyć na powyższym zrzucie ekranu (tym razem skorzystaliśmy z narzędzi deweloperskich w Google Chrome, co od razu poprawiło czytelność JSON-a), problematyczne dane z pliku zniknęły. Na wysłaną przez nas informację o błędzie odpowiedział Tomasz Michalak, wiceprezes zarządu firmy Insignia:
Zgłoszenie od Zaufanej Trzeciej Strony otrzymaliśmy o godzinie 16:56. Natychmiast przystąpiliśmy do analizy zgłoszenia i już w ciągu 30 minut błąd został poprawiony. W drodze analizy ustaliliśmy, że problem wynikał z innego niż oczekiwane zachowania generatora JSON na środowisku produkcyjnym, przez co zawierał on nadmiarowe dane.
W tej sytuacji chcemy wyraźnie podkreślić, że plik /json był plikiem, który od początku miał być i był dostępny publicznie. Jego zadaniem było wyświetlenie na mapie świata zgłoszeń konkursowych. Błąd systemowy spowodował natomiast wygenerowanie większej ilości informacji niż zakładane.
Chcemy podkreślić, że krótki formularz kontaktowy jako zgłoszenie do konkursu nie zawierał żadnych danych, które mogłyby narazić w jakikolwiek sposób konta mailowe, społecznościowe czy jakiekolwiek inne należące do uczestników konkursu. Nie nastąpiło żadne włamanie do infrastruktury serwisu. Chcielibyśmy dodać, że kwestie bezpieczeństwa informatycznego oraz ochrony danych osobowych są w naszej firmie niezwykle ważne i zgłoszenie traktujemy niezwykle poważnie. Wyciągniemy z niego wnioski dla jeszcze lepszego zabezpieczenia naszych wewnętrznych procesów.
Za szybką reakcję na nasze zgłoszenie warto firmę pochwalić. Scenariusz wykorzystania dostępnych wcześniej danych już omówiliśmy. Przede wszystkim istniała możliwość zdobycia z ich pomocą dodatkowych informacji, które mogły otworzyć drogę do dalszych ataków. Sygnałów, że ktoś się tymi danymi posłużył, nie otrzymaliśmy, ale pewności, że tak się nie stało, niestety brak.


Komentarze
Jak zawsze – dobry artykuł :) – pozdrawiam Z3S.
Ciekawy przypadek i pouczająca historia. Pytanie czy ktoś się czegoś nauczy i w swoich środowiskach sprawdził „nadmiarowe pliki”.
Co do głębokiego ukrycia to termin wydaje się być szczególnym przypadkiem szerszego zjawiska „Security through obscurity” którego historia jest długa i bolesna (w sensie kosztowna) dla wielu organizacji i użytkowników. Daleko nie trzeba szukać, jeden z popularniejszych błędów aplikacji webowych wyświetlających dokumenty za pomocą parametru w URL, który jest generowany przewidywalnym algorytmem i pozwala na „enumerację” klucza i pobranie kolejnych dokumentów bez autoryzacji… stare koncepcje – nowe odsłony. I tak bez końca.
Nienawidzę terminu „głębokie ukrycie”. Nie ma on swojego odpowiednika w żadnym innym języku i jest bełkotem wymyślonym przez PKO BP. Najlepiej by było o tym określeniu zapomnieć i mówić po prostu o luce w bezpieczeństwie.
Fachowo to sie nazywa zargon :)
Ja tam nie widze problemu z tlumaczeniem. Porpostu w obcym jezyku opisujesz to jako luka bezpieczenstwa, tudziez jako debilna luka bezpieczenstwa :P
Ja w kwestii formalnej: otóż to NIE jest głębokie ukrycie. Z głębokim ukryciem mamy do czynienia wówczas, gdy lokalizacja z założenia nie jest jawna i wskutek INNEGO błędu została upubliczniona (bo przecież długi losowy adres nie różni się znacząco od hasła – jest to jakiś chroniony secret). Tymczasem tutaj wskazany zasób był wprost i „by design” używany w zasobie publicznym, więc z założenia był jawny.
Poza tym głębokie ukrycie, choć to zabezpieczenie klasy „klucz jest schowany w czwartej doniczce”, to jednak formalnie jest zabezpieczeniem i nie należy go brać w cudzysłowy. Do ochrony wielu rzeczy jest równie wystarczające, jak tekturowe drzwi znane z filmów (i marketów).
Głębokie ukrycie jest ścieżką dostępu, która nie została upubliczniona. Umieszczenie zasobu pod taką ścieżką nie jest zabezpieczeniem ani formalnym, ani technicznym.
Zabezpieczeniem technicznym byłoby ograniczenie możliwości eksplorowania tej ścieżki poprzez np. zastosowanie uwierzytelniania.
Zabezpieczeniem formalnym byłoby związanie wszystkich osób mogących mieć dostęp do tej ścieżki, prawnie wiążącym zakazem jej eksplorowania. Coś na zasadzie regulaminu dostępu do systemu firmowego: „zakazane jest otwieranie zakładki 'Lista płac’. Naruszenie tego zakazu zostanie uznane za ciężkie naruszenie obowiązków pracownicaych”.
Czy taki formalny zakaz, oprócz umożliwienia wyciągnięcia konsekwencji wobec określonej osoby, rzeczywiście zapobiegłby uzyskaniu dostępu do tego zasobu – to jest inna sprawa.
@kaper
„Głębokie ukrycie jest ścieżką dostępu, która nie została upubliczniona. Umieszczenie zasobu pod taką ścieżką nie jest zabezpieczeniem ani formalnym, ani technicznym.”
Czyli *tp://kaper:[email protected]/plik
nie jest zabezpieczeniem ani formalnym, ani technicznym? No to właśnie zrobiłeś „głębokim ukryciem niebędącym żadnym zabezpieczeniem” wszystkie zasoby FTP (często nawet listowalne!) czy HTTP auth.
„Zabezpieczeniem technicznym byłoby ograniczenie możliwości eksplorowania tej ścieżki poprzez np. zastosowanie uwierzytelniania.”
Albo autoryzacji – autoryzujesz tego, kto zna hasło. To, czy hasło jest z przodu ścieżki, czy pośrodku, nie ma znaczenia – znasz secret, jesteś autoryzowany.
@darek
„Nie ma podziału na to jak bardzo skomplikowany jest dostęp do zasobu.”
To od którego momentu ISTNIEJE zabezpieczenie? Weźmy taki HTTP auth: czy basic jest zabezpieczeniem? Czy dopiero digest? A może żadne z nich nie jest zabezpieczeniem?
„Bo każdy zasób w głębokim ukryciu jest zasobem publicznym.”
To weź ściągnij moje PIT-y, trzymam je gdzieś na publicznym serwerze WWW. Nawet bez HTTPS.
„Nie ma znaczenia czy trzeba było sprawdzić npwyniki wyszukiwania Google czy zapytania http do serwera.
[…]
Do ich uzyskania należało sprawdzić wszystkie wywołania do serwera www, zlokalizować odpowiedni zasób i wyświetlić go z linka”
A, w porządku – po prostu nie rozumiesz, co napisałem. To przeczytaj raz jeszcze, a później ponownie i tak do skutku.
„Czyli *tp://kaper:[email protected]/plik nie jest zabezpieczeniem ani formalnym, ani technicznym? No to właśnie zrobiłeś „głębokim ukryciem niebędącym żadnym zabezpieczeniem” wszystkie zasoby FTP (często nawet listowalne!) czy HTTP auth.”
Taka kolej rzeczy – postęp technologiczny powoduje że to, co kiedyś było zabezpieczeniem, staje się tylko ukryciem, i to, z upływem czasu, coraz płytszym. Mury miejskie, skuteczne przeciw kuszom, po wynalezieniu artylerii trzeba było wymienić na fortyfikacje ziemne, a te okazały się bezużyteczne wobec lotnictwa.
HTTP auth wystawione na nieograniczone odgadywanie hasła – naprawdę dziś uważasz to za zabezpieczenie techniczne? Moim zdaniem to jest co najwyżej zabezpieczenie formalne, działające dzięki art. 267 § 2 k.k. przy uznaniu, że intencją założenia hasła było ograniczenie dostępu tylko do osób uprawnionych, która to intencja zostałaby wyrażona odpowiednim komunikatem wysłanym np. po pierwszej nieudanej autoryzacji.
Uzupełnienie.
Kolega Gotar w sumie słusznie zauważył, że jeśli URL we wszystkich wariantach uznajemy za ścieżkę dostępu, to jest możliwe, że ta ścieżka będzie zawierać również dane uwierzytelniające, i wtedy „odkrywanie” tego co jest „głęboko ukryte” będzie wiązało się z przełamaniem zabezpieczeń (słabych zabezpieczeń – ale to nie zmienia postaci rzeczy).
Zatem poprawiam swoją definicję „głębokiego ukrycia”: jest to nieupubliczniona ścieżka, której eksploracja umożliwia dostęp do zasobu bez konieczności uwierzytelnienia.
Nie do końca. Nie ma podziału na to jak bardzo skomplikowany jest dostęp do zasobu. Bo każdy zasób w głębokim ukryciu jest zasobem publicznym. Nie ma znaczenia czy trzeba było sprawdzić npwyniki wyszukiwania Google czy zapytania http do serwera.
Dane nie były dostępne bezpośrednio. Nie widzieliśmy ich na stronie.
Do ich uzyskania należało sprawdzić wszystkie wywołania do serwera www, zlokalizować odpowiedni zasób i wyświetlić go z linka.