W poprzednim wpisie przedstawiłem analizę techniczną modeli ataków na infrastrukturę teleinformatyczną przy użyciu trojanów sprzętowych. W tym artykule, stanowiącym kontynuację poprzedniego, postaram się odpowiedzieć na pytania, komentarze i uwagi czytelników.
Co to są trojany sprzętowe i do czego służą?
Pytanie, którego autorzy często są oskarżani o bycie dyletantami, jest uzasadnione, gdyż odpowiedź na nie nie jest tak oczywista, jak by się mogło wydawać. Trojan sprzętowy to celowo przygotowana i ukryta przed użytkownikiem funkcja układu elektronicznego (np. scalonego czy tzw. chipu), która może dodawać, usuwać lub modyfikować istniejącą funkcjonalność sprzętu i w związku z tym zmniejszyć jego niezawodność lub stworzyć potencjalne zagrożenie.
Trojan sprzętowy (hardware’owy) działa bardzo podobnie do trojana w oprogramowaniu. Użytkownik kupuje interesujący go komponent, na przykład klawiaturę lub myszkę z interfejsem USB (patrz Rysunek 1), która oprócz pobierania informacji o wciskanych klawiszach posiada jeszcze układ zdolny do generowania takich sygnałów. Oczywiście ten „walor” produktu jest pomijany w dokumentacji. Następnie układ ten jest w stanie odtworzyć zapisane w pamięci flash makra i generować polecenia wyzwalane zewnętrznymi sygnałami sterującymi.

Rysunek 1. Trojan sprzętowy w myszce (a) i klawiaturze (b), źródło: JP Dunning “.ronin” BlackHat Asia 2014
Chciałbym zwrócić uwagę na dwa aspekty z definicji, które powodują, że identyfikacja trojana sprzętowego nie jest taka prosta:
- “celowo przygotowana i ukryta przed użytkownikiem” – zgodnie z tym twierdzeniem, jeśli producent informuje nas o tym, że jego układ jest trojanem, a my wyrażamy na to zgodę, to jest to w zasadzie legalne (oczywiście są jeszcze aspekty prawne ochrony prywatności i zbierania danych, ale to problem równoległy). To powoduje, że np. Intel Management Engine ma technicznie możliwości trojana (zamknięty kod, dostęp do komponentów, raportowanie do serwerów producenta etc.), ale mimo kontrowersji jest legalny. O Intel Management Engine postaram się jeszcze napisać w najbliższej przyszłości. Druga kategoria to układy, w których producent twierdzi, że mimo posiadanych znamion trojana są błędami projektowymi, czyli nie spełniają aspektu “celowości” z definicji. Jest to wygodne tłumaczenie, bo odwraca zasadę znaną większości programistów “to nie bug, to feature” i robi z niej “to nie feature, to bug”. Udowodnienie producentowi celowości działania w takich przypadkach jest niezwykle trudne i wymaga tak naprawdę dokumentów oraz zeznań pracowników. Na przykład, jak sprawdzić, czy Intel wiedział o podatnościach Spectre i Meltdown od lat i celowo nie łatał procesorów? A nawet jeżeli wiedział, a pomimo to nie łatał podatności, to robił to ze względów ściśle ekonomicznym i nigdy nie wykorzystał tej podatności w celu włamania się na komputery. Spekulacje można by mnożyć, a o twarde dowody jest bardzo trudno.
- “dodawać, usuwać lub modyfikować istniejącą funkcjonalność” – trojan sprzętowy nie musi “dodawać” nowej funkcjonalności do układu. Wystarczy, że zachowuje się jak zwykły błąd projektowy, o którym wiedzą tylko wybrane osoby. Błędy zazwyczaj modyfikują działanie układu bądź uniemożliwiają dostęp do jakichś funkcji. Jeszcze raz przytoczę przykład podatności Spectre i Meltdown w procesorach Intela. Gdyby o ich istnieniu wiedział zarząd i wykorzystywał do wykradania danych, to byłby to trojan. Jednak błędy się zdarzają. Dodatkowo od razu dostajemy odpowiedź na pytanie, jak drogi jest trojan sprzętowy. Najtańszy trojan jest tak tani jak błąd projektowy w układzie scalonym wpływającym na bezpieczeństwo systemu.
Jakie są różnice między trojanami sprzętowymi i klasycznymi w oprogramowaniu (system operacyjny, firmware)?
Podobieństwa pomiędzy trojanami sprzętowymi i softwarowymi wynikają głównie z celów ich działania: infiltracji i eksfiltracji. Infiltracja polega na wprowadzaniu zmian w infrastrukturze, które zakłócają poprawną pracę systemu, np. modyfikację danych, modyfikację funkcjonalności czy bardziej wyrafinowane działania, takie jak celowe osłabienie algorytmów kryptograficznych przez zmianę klucza na znany. Eksfiltracja polega na wysłaniu do atakującego informacji z systemu, np. danych (projektowych, pracowników, logów etc), kluczy kryptograficznych, danych potwierdzających tożsamość, wartości startowych generatorów liczb pseudolosowych czy wreszcie kodu aplikacji bądź dokumentacji projektów.
Na czym polegają zatem różnice? Implementacja trojanów sprzętowych to zadanie wymagające przede wszystkim zdolności produkcyjnych w zakresie wytwarzania układów scalonych, tzn. odpowiednio przeszkolonego personelu i narzędzi, a więc generujące wysokie koszty. Warto o tym pamiętać, gdyż są instytucje (a nawet kraje) nieposiadające takich możliwości – zobaczcie np. listę firm produkujących układy scalone na krzemie z Wikipedii. Produkcja sprzętu jest procesem wielostopniowym, w którym biorą udział oprócz podmiotów z branży elektronicznej również te z branży chemicznej czy nawet mechanicznej (systemy wbudowane w maszynach do pracy w wysokich temperaturach czy wibracjach). Dodatkowo wymaga dużych nakładów finansowych, np. pomieszczenia o wysokim stopniu czystości (tzw. cleanroom) w laboratoriach do produkcji krzemu, mikroskopy, lasery do cięcia wafli krzemowych etc. Z praktyki, np. systemów wbudowanych, powszechnie wiadomo, że wiele funkcji można wykonać za pomocą dedykowanego układu elektronicznego (ang. application-specific integrated circuit, AISIC) bądź software’owo za pomocą programowalnego kontrolera. Różnica polega na koszcie i elastyczności rozwiązania. W przeciwieństwie do oprogramowania, w większości wypadków zmiany wprowadzonej funkcjonalności sprzętowej w procesie post-produkcyjnym (tzn. po wprowadzeniu produktu na rynek) są praktycznie niemożliwe. W przypadku błędnej pracy układu na krzemie producent może próbować firmware’em ograniczać jego skutki, np. microcode, jednak pełna wymiana bramek czy tranzystorów jest niemożliwa. To wymusza długą fazę testową, dodatkowo zwiększając i tak już wysokie koszty produkcji. Trojany sprzętowe są więc niezwykle kosztowne dla podmiotów nieposiadających odpowiedniej infrastruktury. Można je wręcz nazwać “opcją atomową” bezpieczeństwa teleinformatycznego.
Trojany sprzętowe mają jednak niepodważalne zalety. Ich wykrycie i analiza działania jest zdecydowanie trudniejsza niż w przypadku oprogramowania. Inżynieria wsteczna układów scalonych wymaga mikroskopów laboratoriów chemicznych oraz bardzo wysokich nakładów finansowych. Trojanów sprzętowych często nie da się blokować software’owo, tzn. atakujący nie musi obawiać się nowej poprawki czy wersji systemu łatającej podatność. Dodatkowo cykl życia układów elektronicznych jest zdecydowanie dłuższy niż oprogramowania. Często jednym z podstawowych wymagań klientów jest kompatybilność wsteczna pozwalająca na wykorzystanie tego samego produktu przez wiele lat, np. w terminalach na lotniskach, w bankomatach czy systemach wbudowanych. 15-letnia jednostka licząca zamontowana w samochodzie czy ośmioletni laptop nie jest czymś wyjątkowym. Pozwala to atakującemu na rozciągnięciu całego ataku w czasie i przeprowadzanie bardzo skomplikowanych ataków.
Czy trojany sprzętowe to teoria spiskowa?
Techniczna możliwość wprowadzenia trojana sprzętowego to fakt naukowy potwierdzony wynikami badań i publicznie prezentowanymi prototypami. Od ponad 20 lat temat jest obiektem badań naukowych i przemysłowych na całym świecie. Liczba publikacji rośnie lawinowo z roku na rok, np. w 2017 Google Scholar stwierdza 2500 nowych publikacji po hasłem “hardware trojan”, patrz grafika poniżej (zachęcam do samodzielnego szukania i weryfikacji).
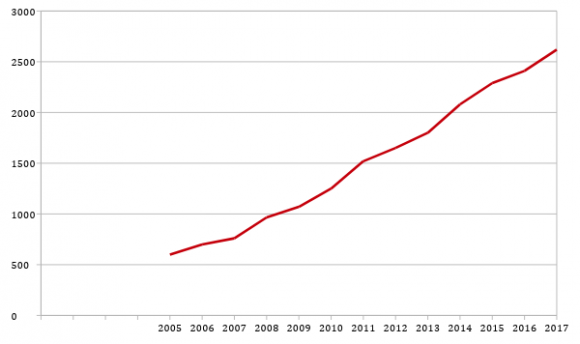
Rysunek 2. Liczba publikacji ze słowem kluczowym “hardware trojans” w ujęciu rocznym, źródło: Google Scholar
Tematem zajmują się renomowane uczelnie na świecie, np. Uni Bochum, Columbia University, University of Maryland. Książki i artykuły wydaje np. Elsevier, Springer czy ACM i IEEE. Tematem zajmują się też znane koncerny, np. Infineon. Pojawiły się nawet upublicznione raporty ministerstw obrony, w tym Departamentu Obrony USA. Na konferencjach prezentowane są demonstracje na żywo i dokładne analizy, jak choćby Building Trojan Hardware at Home na Black Hat 2014. Co więcej, prasa donosi o kolejnych skandalach – tytuły „Panel kongresu US uznaje Huawei i ZTE za zagrożenie dla bezpieczeństwa narodowego” z dziennika New York Times czy „Huawei szpieg z Chin” niemieckiej telewizji publicznej Arte najlepiej oddają sytuację.
Zresztą dowód na wykonalność trojanów sprzętowych można wyprowadzić nawet z definicji – zawsze produkt może mieć ukrytą przed użytkownikiem, a celowo zaprojektowaną funkcję ograniczającą bezpieczeństwo.
Spekulacje o teorii spisku najczęściej podbudowane są brakiem jednoznacznego dowodu ich użycia w postaci skandalu na przykład takiego, jak ten ze spalinami w silnikach Volkswagena, gdzie zarząd przyznał się publicznie do manipulacji, a układ można wyszczególnić i zaprezentować. Pytanie jednak, czy taki skandal będzie kiedykolwiek miał miejsce w przypadku elektroniki użytkowej? Wymówka o braku celowości działania – czyli trojan poprzez błąd projektowy – jest na tyle wygodna, że z łatwością można ją zastosować do większości przypadków. Jednak nakłady na badania i publikacje z zakresu trojanów sprzętowych systematycznie się zwiększają (patrz wyniki z Google Scholar). Również pewne firmy, np. Huawei, są wykluczane z przetargów na infrastrukturę krytyczną w wielu państwach. To sprawia że w przypadku trojanów sprzętowych przemysł i nauka a nawet polityka i media wydają się być zgodne co do faktów i realności zagrożenia. Każdy ma prawo do własnych opinii, więc wnioski pozostawiam Wam samym.
Czy da się w warunkach domowych zaprojektować i przetestować trojana sprzętowego?
Tak. Najprostszy sposób to prototyp FPGA albo emulator. Dla zainteresowanych artykuł z konferencji PWNING 2017 – “CPU BACKDOOR – CZYLI PO CO WYWAŻAĆ OTWARTE DRZWI?”, w którym dokładnie opisuję ten temat.
Produkcja procesora kosztuje od milionów do miliardów dolarów! Czy wprowadzenie trojana sprzętowego się w ogóle opłaca?
Tutaj mamy przykład kolejnego mitu. Twierdzenie “produkcja procesora kosztuje od milionów do miliardów dolarów” jest czystą spekulacją. To trochę tak, jakby powiedzieć, że napisanie “gry komputerowej” kosztuje miliony dolarów. Od razu pojawiają się wątpliwości i pytania, bez których takie twierdzenie nie ma sensu, np. gra na tablet/smartfona, webową, indie czy multiplatformowy wysokobudżetowy produkt (XBOX, PS, PC)? Jaki silnik, jakie środowisko pracy, jakie biblioteki? Ile płacimy za licencje? Ile płacimy za dystrybucję (Steam, GoG czy producent np. UBI, Microsoft)?
Te same pytania można zadać w przypadku układu scalonego z docelowym wdrożeniem na krzemie. Zaprojektowanie procesora od podstaw to proces drogi, ale dużą część kosztów generują licencje na narzędzia, rozwiązania patentowe etc. Bez nich koszt produkcji, tak jak w przypadku oprogramowania, byłby o wiele niższy. Po drugie, procesor Intela czy AMD to efekt kilkudziesięciu lat pracy i badań – tak jak jądro Windowsa czy Linuxa. Napisanie podobnego produktu od zera jest dla większości podmiotów i organizacji nieopłacalne. Jednak drobne poprawki i modyfikacje nie są już tak drogie np. patche, biblioteki etc . Podobnie w przypadku trojanów sprzętowych, tworzenie produktu od zera tylko po to, by wprowadzić w nim trojana, wydaje się być nieopłacalne. Jednak mały patch do już istniejącego produktu, niezałatany błąd pozostawiony w układzie, nie są już tak drogie. Koszty dodatkowo spadają w sytuacji, w której mamy sprawny i doświadczony zespół projektantów, którzy z produktem pracują na co dzień.
Czy modyfikacje masek do trawienia krzemu to czysta spekulacja ze względu na koszt i poziom skomplikowania?
Nie. Najlepiej dowodzi tego raport departamentu obrony USA poświęcony temu zagadnieniu – HIGH PERFORMANCE MICROCHIP SUPPLY. Dla zainteresowanych tematem zachęcam do zapoznania się z treścią i sięgnięcia do źródeł, np. Stealthy Dopant-Level Hardware Trojans: Extended Version. Jest to jednak bardzo skomplikowany wariant ataku, a więc i bardzo drogi – dostępny tylko dla kilku instytucji i organizacji na świecie.
Czy trojana sprzętowego da się wykryć?
Tak. Jest to jednak bardziej czasochłonne i kosztowne niż w przypadku oprogramowania.
Proces detekcji trojanów sprzętowych jest drogi i skomplikowany. Pierwszą barierą są kwestie techniczne. Narzędzia do rewersu i analizy oprogramowania są stosunkowo łatwo dostępne, a niezbędne prace można przeprowadzić na zwykłej stacji roboczej. Zazwyczaj wymaga disassemblera wspieranego przez narzędzia do wstecznej analizy kodu, np. IDAPro czy radare. W przypadku chipów krzemowych jest to proces zdecydowanie bardziej skomplikowany. Po pierwsze krzem sprzedawany jest w szczelnych plastikowych (epoksydowych) obudowach, które trzeba usunąć, by móc fizycznie zobaczyć układ. Proste metody mechaniczne, np. szlifowanie, mogą uszkodzić chip. Nawet mała rysa w przypadku technologii wykonania poniżej 90nm może zdecydowanie utrudnić, bądź wręcz uniemożliwić analizę wsteczną. W profesjonalnych laboratoriach stosuje się zatem silnie żrące kwasy rozpuszczające wszystko oprócz krzemu (warto zauważyć, że chip powinien być wciąż sprawny, by móc obserwować jego pracę w czasie rzeczywistym – inaczej sprawdzenie zawartości pamięci, rejestrów i wykonania równoległego jest niemożliwe). Ich użycie wymaga jednak odpowiedniej infrastruktury, np. odpowiednie nawiewy, narzędzia (pipety, odczynniki), a co ważniejsze odpowiednio przeszkolonego i doświadczonego personelu. Fizyczny dostęp do powierzchni układu to dopiero pierwszy krok. W następnym, do wykonania analizy, niezbędne są silne mikroskopy. Już sama wielkość układu, np. 27 nm, jest barierą nie do przeskoczenia dla wielu hobbystów ze względu na wymagane powiększenie i jakość obrazu. Dodatkowo wiele układów produkowanych jest w technologii 3D, tzw. wielowarstwowej. W tym wypadku trzeba przekroić bądź wypalić warstwę, by zobaczyć ukryte fragmenty, do czego niezbędne są precyzyjne lasery.
Następną kwestią utrudniającą inżynierię wsteczną jest współbieżność pracy większości obwodów, tzn. elementy procesora, takie jak stopnie potoku czy rejestry, pracują równolegle ze sobą w czasie. Z teorii programowania wiadomo, że debug aplikacji wielowątkowej jest czasochłonny i kosztowny. Proces ten wymaga nie tylko znajomości wartości sygnałów stymulujących pracę układu, ale także ich przebiegu w czasie i współzależności. Te same problemy w sposób bezpośredni odnoszą się do obwodów elektronicznych. Dodatkowo w przypadku prostych układów metoda, np. jednostki 8081, metoda testowania wszystkich możliwych zestawów wejść – analogowych, cyfrowych, jak i programowalnych (ISA), choć pracochłonna, jest jednak możliwa. W przypadku nowoczesnych jednostek, np. procesorów Intela, jest już bardzo trudna.
Dodatkowo na końcowy kształt układu elektronicznego mają też wpływ czynniki ekonomiczne, takie jak cena pamięci czy podzespołów, które dynamicznie zmieniają się w czasie. Jak wiadomo z rewersu starszych generacji procesorów, budowa wielu elementów układu nie musi być oczywista i prosta do zrozumienia z przyczyn czysto praktycznych. Dobrym przykładem są procesory z lat 70. i 80., które ze względu na wykonanie za pomocą starych procesów technologicznych (8000–1500 nm) są częstym obiektem analizy wstecznej dokonywanej przez amatorów i profesjonalistów. W procesorze Z80 jednostka arytmetyczna według specyfikacji jest 8-bitowa, jednak jej wykonanie odbywa się za pomocą czterech rejestrów w dwustopniowym potoku, patrz Rysunek 3. Pozwoliło to projektantom zaoszczędzić cenne miejsce na chipie, a użytkownik / programista nie odczuwa różnicy, gdyż wykonanie programu jest zdefiniowanie przez wydajność innych fragmentów układu i dlatego stopnie potoku są transparentne. Kolejnym problemem jest kompatybilność wsteczna, która często wymusza istnienie artefaktów projektowych, tzn. elementów, które są umieszczane na chipie ze względu na starsze programy, a nie obecny stan techniki. Dobrym przykładem jest proces bootowania (startu) architektury x86, który jest skomplikowany i trudny do zrozumienia dla wielu użytkowników.

Rysunek 3. Zdjęcie struktury układu Z80, źródło: Wikipedia, oznaczenia autora
Na koniec pozostają jeszcze błędy projektowe. Dodatkowo rewers i sprawdzenie układu, oprócz tego, że jest czasochłonne i kosztowne, często wiąże się z jego fizycznym zniszczeniem. To powoduje, że testy przeprowadza się na małym procencie układów i wiąże z ryzykiem przepuszczenia “trefnych” egzemplarzy.
Czy można przeprowadzić ”fuzzing” układu scalonego?
Tak. “Fuzzing” sprzętu elektronicznego to proces analogiczny do jego odpowiednika znanego z oprogramowania. Jednak jest to dość trudne zadanie, dla zainteresowanych polecam prezentację Breaking the x86 Instruction Set z konferencji Black Hat 2017 (o fuzzingu procesorów Intela).
A może sceptycyzm w stosunku do trojanów sprzętowych jest wyższy w związku z brakiem krajowego przemysłu półprzewodnikowego?
Tę ciekawą tezę od jednego z czytelników pozostawiam do przemyśleń na koniec. Czy nie jest tak, że jeśli sami pracujemy jako np. programiści, to jesteśmy mniej podatni na marketing innych firm produkujących oprogramowanie? Zapewnienia “w naszym oprogramowaniu nie ma błędów” bądź “nasze oprogramowanie jest w 100% bezpieczne, łatki i aktualizacje będą sporadyczne” wywołują sarkastyczny uśmiech, gdy te same twierdzenia w stosunku do sprzętu traktujemy poważnie. W tym kontekście nawet ograniczona produkcja krajowa znacznie ułatwia kontrolę kupowanych produktów.
Poprzedni artykuł na ten temat: Trojany sprzętowe – realistyczny scenariusz ataku poprzez ingerencję w układ scalony
Adam Kostrzewa: Od ośmiu lat zajmuję się badaniami naukowymi i doradztwem przemysłowym w zakresie elektroniki motoryzacyjnej, a w szczególności systemów wbudowanych pracujących w czasie rzeczywistym do zastosowań mogących mieć krytyczne znaczenie dla bezpieczeństwa użytkowników. W wolnym czasie jestem entuzjastą bezpieczeństwa danych. Szczególnie interesujące są dla mnie sprzętowe aspekty implementacji obwodów elektrycznych i produkcji krzemu. Metody i narzędzia używane do tych zadań nie są aż tak dostępne i dokładnie przetestowane jak oprogramowanie, dlatego też stanowią interesującą dziedzinę do badań i eksperymentów.
Blog: adamkostrzewa.github.io
Twitter: twitter.com/systemWbudowany


{kind=link}
Komentarze
„Tematem zajmują się renomowane uczelnie na świecie…”
Dziwi mnie w tym zestawieniu brak uczelni izraelskich i chińskich.
Szczególnie państwo Izrael jest żywo zainteresowane każdą technologią mogącą mieć zastosowanie obronne/militarne. Myślę że Izraelczycy pracują nad sprzętowymi trojanami, ale się tym nie chwalą.
A jaki jest sens tworzenie białego wywiadu wymierzonego w siebie?
Sens może i by był kontrolowanej opozycji, ale tu wchodzi w grę nauka i ludzie inteligentni. Tu demokracja nie działa… Albo coś działa, albo nie. Efekt jest widoczny natychmiastowo.
No to jak widzę, sugerujesz, że demokracja to chaotyczny stan. Jak sugerujesz w swoim wpisie, w demokracji jak coś nie działa, to i tak tego nie widać. W sumie to masz rację. Bo gdyby w CPU wbudowano mechanizm logiczny oparty na głosowaniu parlamentarnym, to komputer nadawałby się jedynie jako przycisk do papieru :-)
Wydaje mi sie, ze jest tu kilka niescislosci (chociaz artykul przeczytalem na szybko):
– Testowanie wszystkich wejsc/wyjsc w przypadku jakiegokolwiek procesora mlodszego niz 30-40 lat jest praktycznie nie mozliwe, poniewaz procesor ma stan (rejestry, + ukryte stany). Calkowity test wiec musial by obejmowac wszystkie wejscia x wszystkie stany w jakich procesor moze sie znajdowac.
– Jak chodzi o grzebanie w maskach, to zakladam ze chodzi tu o exploity wstawione w fabryce (tsmc na przyklad) – w takim wypadku jedynym sensownym rozwiazaniem bylo by chyba porownanie maski ktora wychodzi od producenta chip’u z tym co przyszlo z fabryki. Nie sadze zeby ktokolwiek to robil ;)
– Jak chodzi o backdoory wprowadzane przez producenta procesora, to duzo prosciej wrzucic je w RTL albo nawet do zrodel (hdl) jako „niepozorny blad”. Oczywiscie zalozeniem jest ze producent procesora nie wrzuca tego celowo, tylko ma wewnatrz „agentow” ktorym na takowym zalezy (lub jakas grupe interesow).
Co do pierwszego, to raczej nie tylko stany, ale sposoby uzyskania stanu. Robiłem taki rewers dość prostego sterownika, przynajmniej wiedziałem co chcę uzyskać, więc zakodowałem do tego GA. 3 dni tłukł bitami po wejściu szeregowym by znaleźć 2 paramteryzowane stany w jakim może być urządzenie i jak je zmieniać.