Błogosławieństwem technologii miała być oszczędność czasu. Trudno jednak o niej pamiętać, gdy poświęca się długie godziny na stawianie i konfigurowanie serwerów. A gdyby zrobić to wszystko automatycznie?
W dotychczasowej serii artykułów Aruba Cloud prezentowaliśmy różne scenariusze wykorzystania zasobów w chmurze, odnosząc się przede wszystkim do aspektów ich praktycznego wykorzystania. Każda z publikacji zawierała instrukcję, której celem było przeprowadzenie czytelnika przez szereg czynności konfiguracyjnych zmierzających do uzyskania efektu końcowego w postaci działającego rozwiązania. Dziś natomiast nie będzie żadnego ,,kompletnego tutoriala”, ponieważ zamierzamy dostarczyć wam gotową infrastrukturę w postaci kodu.
„Cyfrowy Ninja”
Ile razy w swojej codziennej pracy robiliście to samo: dwuklik, dalej, dalej, zainstaluj… a następnie niecierpliwe oczekiwanie, aż przysłowiowy ,,pasek postępu” dotrze do końca? Ile jest komend i poleceń z basha, które nie tyle znacie, co pamiętają je już wasze palce? Ręczne powtarzanie tych samych zadań setki razy dziennie to jedna z najnudniejszych, uciążliwych i – na szczęście – odchodzących do lamusa praktyk.
W tym roku mija już 10 lat od wydarzenia, podczas którego po raz pierwszy publicznie została zaprezentowana metodyka DevOps. Samo sformułowanie jest powszechnie znane w branży IT, a wpisanie tej frazy w rodzimych wyszukiwarkach ofert pracy generuje kilkaset wyników. Metodyka DevOps służy przede wszystkim szybszemu dostarczeniu oprogramowania przy znaczącym ograniczeniu liczby błędów powstałych podczas jego tworzenia.
Automatyzacja – czy może jednak instrumentacja?
Terraform to rozwiązanie open source służące do orkiestracji zasobów uruchamianych zarówno w ramach infrastruktur lokalnych, jaki i chmurowych. Projekt jest bardzo dynamicznie rozwijany, a dzięki bardzo aktywnej społeczności zapewnia na tę chwilę wsparcie dla ponad setki dostawców API (providers). Ponadto współdziała on z wieloma różnymi narzędziami służącymi do tzw. ,,wyposażania” (provisioners). Terraform pozwala na realizację bardzo złożonych zadań, same platformy chmurowe to przecież nie tylko instancje systemów operacyjnych, ale też niezliczona ilość dodatkowych elementów – zasoby storage, komponenty sieciowe czy systemy zarządzania tożsamością (IAM). Stąd właśnie coraz częściej spotykamy się z pojęciem orkiestracji (instrumentacji). Sama automatyzacja to nie wszystko – jako proces musi być odpowiednio zaplanowana, realizowana w kontekście wymagań biznesowych oraz monitorowana przez cały cykl życia dostarczanej aplikacji.
Korzystanie z Terraforma polega na opisaniu naszej infrastruktury w plikach o rozszerzeniu .tf przy wykorzystaniu języka HCL (HashiCorp Configuration Language). Składnia bazuje na tej znanej z JSON, przy czym autorzy narzędzia (firma HashiCorp) wprowadzili do HCL parę usprawnień (m.in. możliwość umieszczania komentarzy). W samym kodzie wykorzystywanych jest kilka elementów służących do budowania całego środowiska. Najistotniejsze z nich i wykorzystywane w naszym przykładzie to:
data – pozwala na odczytywanie dostępnych parametrów pobieranych przez API, takich jak np. nazwy istniejących instancji,
variable – zmienna wykorzystywana do przechowywania wartości, np. nazwa lub adresacja nowo tworzonej sieci, nazwa hosta, login itd. Aby odwołać się do wartości zmiennej, nazwę parametru należy poprzedzić przedrostkiem var,
resource – czyli zasoby, jakie zostaną stworzone przez Terraforma.
Po opisaniu całej infrastruktury i stworzeniu wszystkich plików, zanim przystąpimy do uruchomienia wdrożenia, warto zweryfikować, czy wszystkie pliki są poprawne i nie zawierają błędów. W tym celu możemy uruchomić polecenie terraform validate. Polecenie wywołujemy zawsze z głównego katalogu zawierającego pliki naszego środowiska. O ile nie popełniliśmy żadnego błędu, powinniśmy zobaczyć komunikat o treści: ,,Success! The configuration is valid”. Poza walidacją w Terraformie jest jeszcze kilka istotnych poleceń:
terraform init – służy do inicjalizacji, czyli dokonuje wstępnej analizy naszego środowiska i w razie potrzeby przeprowadza automatyczne pobranie wymaganych modułów, jakie zostaną zapisane w subkatalogu o nazwie .terraform,
terrafform plan – wyświetla opis tworzonej infrastruktury dla jej aktualnego stanu. Dzięki automatycznie utworzonemu plikowi terraform.tfstate stan infrastruktury jest cały czas monitorowany. Dlatego kolejne wywołania wdrożeń zamiast budować wszystko od nowa po prostu zaktualizują tylko te zmiany, jakie dodaliśmy w kolejnej rewizji kodu. Na koniec każdego wywołania tej komendy Terraform poinformuje nas o liczbie wprowadzanych zmian:

terraform apply – realizuje wdrożenie / aktualizację środowiska zgodnie z wcześniej utworzonym planem,
terraform destroy – usuwa wszystkie zasoby zgodnie z sobie znanym stanem środowiska. Dlatego pod żadnym pozorem nie należy ręcznie edytować czy kasować pliku terraform.tfstate, w przeciwnym razie Terraform może wygenerować błędy lub nie być w stanie przeprowadzić żadnej modyfikacji na środowisku.
Sam Terraform pozwala na wykonanie dowolnych poleceń czy skryptów powłoki, niemniej jednak dzieje się to każdorazowo podczas wykonywania operacji związanych z wdrożeniem czy aktualizacją infrastruktury. Dzięki tzw. ,,provisionerom” mamy możliwość wykonywania zestawu dodatkowych operacji już po utworzeniu naszych zasobów. Jednym z najpopularniejszych narzędzi do zarządzana infrastrukturą jest Ansible. Rozwiązanie to jest całkowicie bezagentowe – w przypadku platformy CentOS działa w oparciu o protokół SSH i biblioteki Pythona. Do realizacji wdrożeń konfiguracji będziemy korzystać z tzw. playbooków. To specjalne pliki utworzone w formacie YAML– zawieramy w nich dyrektywy służące do przeprowadzania procesów konfiguracyjnych na wskazanych hostach.
Demonstrację na żywym systemie znajdziecie na poniższym filmie, a pod nim zamieściliśmy instrukcje krok po kroku.
Aruba Private Cloud
Firma Aruba dla najbardziej wymagających klientów przygotowała rozwiązanie w postaci usługi dedykowanej chmury prywatnej. To rozwiązanie bez kompromisów, zapewniające rezerwację zasobów obliczeniowych czy przestrzeni dyskowej na ściśle określonym poziomie. Usługa Private Cloud działa w oparciu o stabilne i sprawdzone rozwiązania firmy VMware, jakimi są vCloudDirector czy NSX. Zamówienie takiej usługi to tak naprawdę utworzenie tzw. wirtualnego data center wydzielonego z fizycznych zasobów Aruba Cloud. Sama aktywacja usługi, gdy już posiadamy konto Aruba Cloud, sprowadza się do przeprowadzenia kilku prostych czynności:
1. Po zalogowaniu do Panelu Administracyjnego przechodzimy do zakładki Cloud PRIVATE i rozpoczynamy proces konfiguracji usługi poprzez kliknięcie na przycisk


2. W formularzu podajemy parametry nowej chmury prywatnej, które są zgodnie z naszymi wymaganiami. Dla naszego środowiska wybieramy poniższą konfigurację:

3. Po kliknięciu na ,,Kontynuuj” przechodzimy do kolejnego okna kreatora, w którym definiujemy parametry zasobów sieciowych:
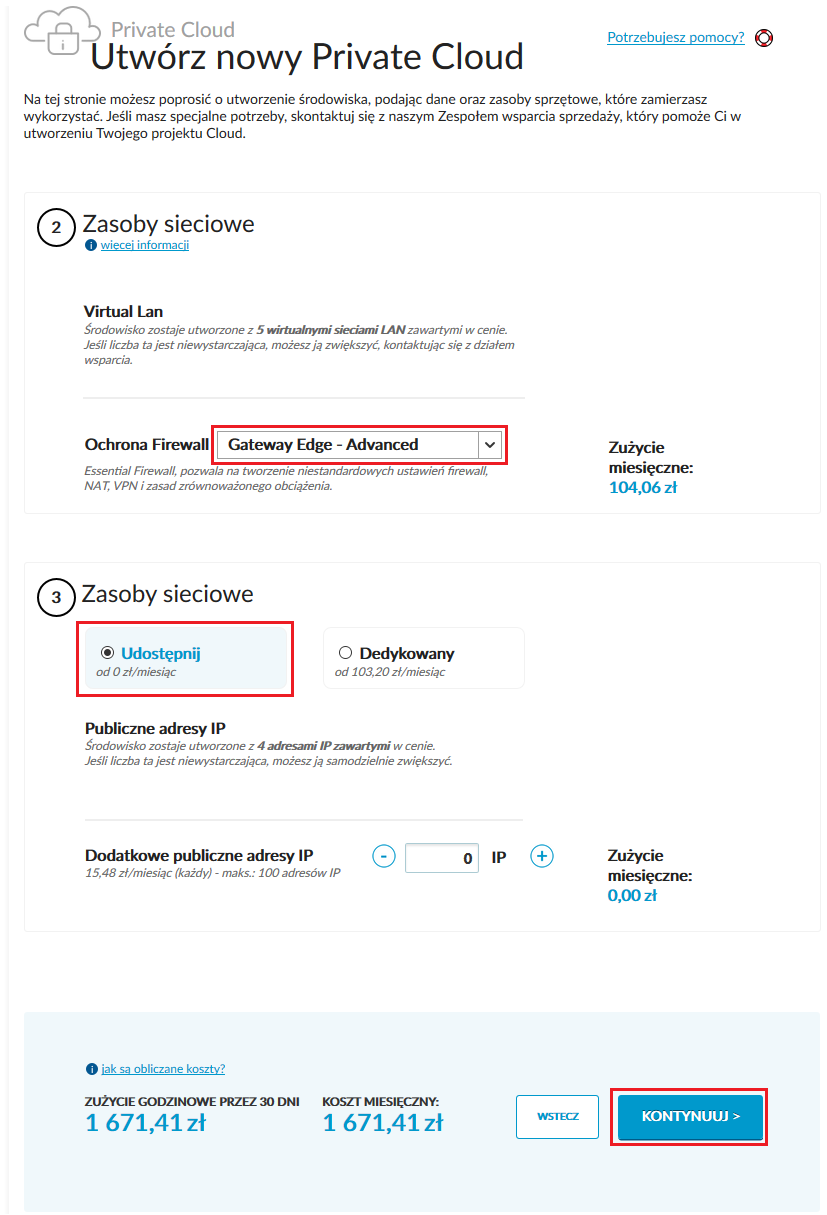
4. W ramach usługi Cloud Private mamy możliwość skorzystać z zewnętrznych technologii do backupu i obsługi mechanizmów disaster recovery. Wybór obu rozwiązań jest opcjonalny, stąd też ten krok konfiguracji możemy pominąć. Ostatnim oknem kreatora jest to, w którym definiujemy parametry takie jak: nazwa usługi, dane logowania do panelu VMware vCloud Director czy też dane kontaktowe do administratora zasobu Cloud Private:
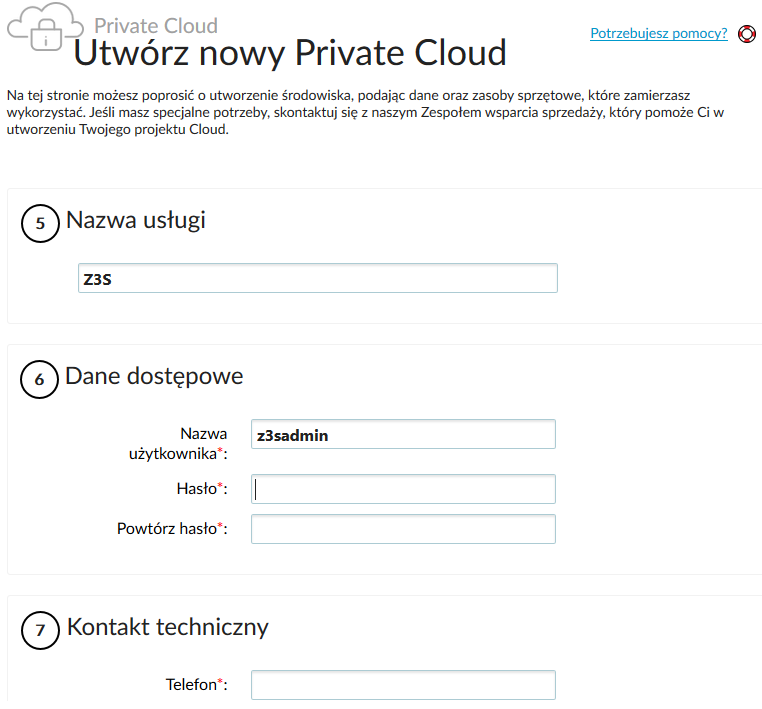
5. Po zapisaniu wszystkich danych kreatora zostajemy przeniesieni do strony podsumowania. Warto jeszcze raz dokładnie sprawdzić wszystkie parametry, ponieważ Cloud Private działa w modelu rozliczenia miesięcznego – po zakończeniu procesu wdrożenia nasze konto zostanie obciążone kwotą za całą usługę:
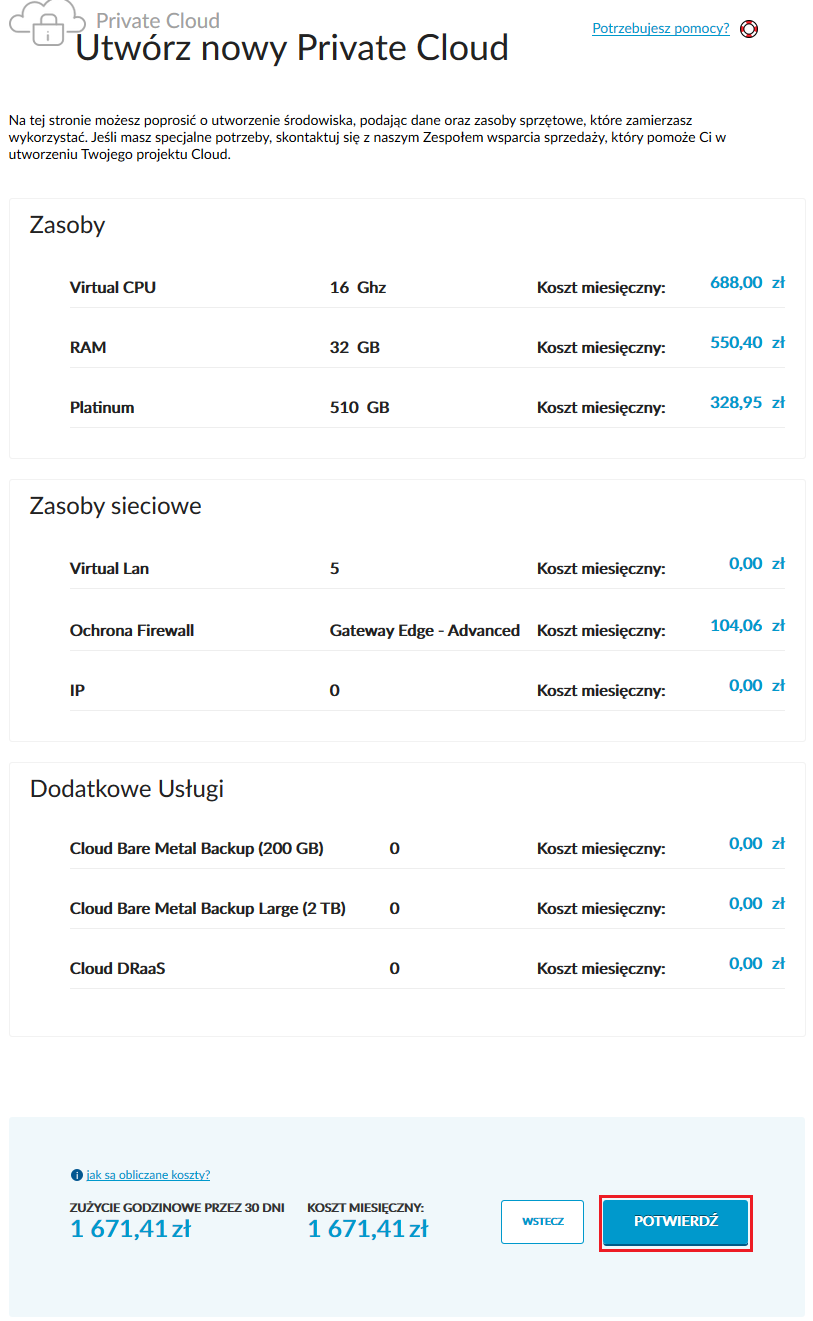
Wydzielenie naszej infrastruktury i uruchomienie prywatnej chmury może potrwać do 24 godzin. Stan tworzenia zasobów możemy monitorować bezpośrednio z panelu administracyjnego:
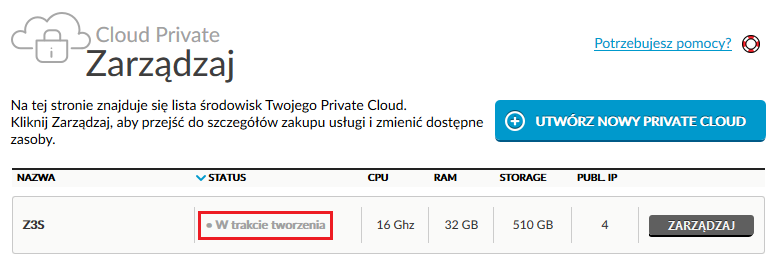
Oczywiście jak tylko zasoby będą już dostępne, otrzymamy stosowne powiadomienie na naszą skrzynkę pocztową.
Terraform – formujemy pierwsze zasoby
Samego Terraforma możemy bardzo łatwo zainstalować poprzez pobranie gotowego pliku binarnego ze strony producenta: https://www.terraform.io/downloads.html
Terraform działa na praktycznie dowolnej platformie – również w architekturze ARM. Aktualnie wspierane systemy to między innymi Linux, Windows, macOS, Free/OpenBSD oraz Solaris. Na potrzeby naszego artykułu wykorzystujemy system Debian 9.9. Samo pierwsze uruchomienie Terraforma może wyglądać w poniższy sposób:
wget https://releases.hashicorp.com/terraform/0.12.1/terraform_0.12.1_linux_amd64.zip sudo apt update && sudo apt upgrade sudo apt install unzip unzip terraform_0.12.1_linux_amd64.zip ./terraform sudo mv terraform /usr/bin/ terraform -v
Gdy samo narzędzie jest gotowe do pracy, kolejnym etapem jest stworzenie opisu naszego środowiska w postaci kodu. Na początek zdefiniujmy jego podstawowe parametry:
- serwer CentOS utworzony z gotowego obrazu w konfiguracji: 4xvCPU i 4GB RAM,
- serwer ma działać w ramach sieci wewnętrznej i adresacji prywatnej,
- na zewnątrz pod jednym publicznym adresem IP osiągalne będą usługi takie jak http/https,
- zarządzanie serwerem ma być możliwe przez SSH dostępne na publicznym adresie IP,
- na maszynach wirtualnych zaraz po ich wdrożeniu mają być automatycznie przeprowadzone następujące czynności: instalacja i konfiguracja LAMP stack (apache + php + mariadb) oraz wdrożenie gotowej witryny opartej o WordPressa.
Powyższy opis możemy potraktować jako prosty przykład wymagań klienta oczekującego od nas przygotowania odpowiedniego środowiska pod konkretną aplikację.
Aruba Cloud Private daje nam możliwość załadowania własnego obrazu maszyny wirtualnej w formacie OVF. W związku z tym, że takie własne obrazy będą zmniejszały zakupioną przestrzeń dyskową, skorzystamy z gotowych szablonów OVF dostarczanych przez Aruba. Nazwy wszystkich obrazów możemy zweryfikować z poziomu vCloudDirectora:
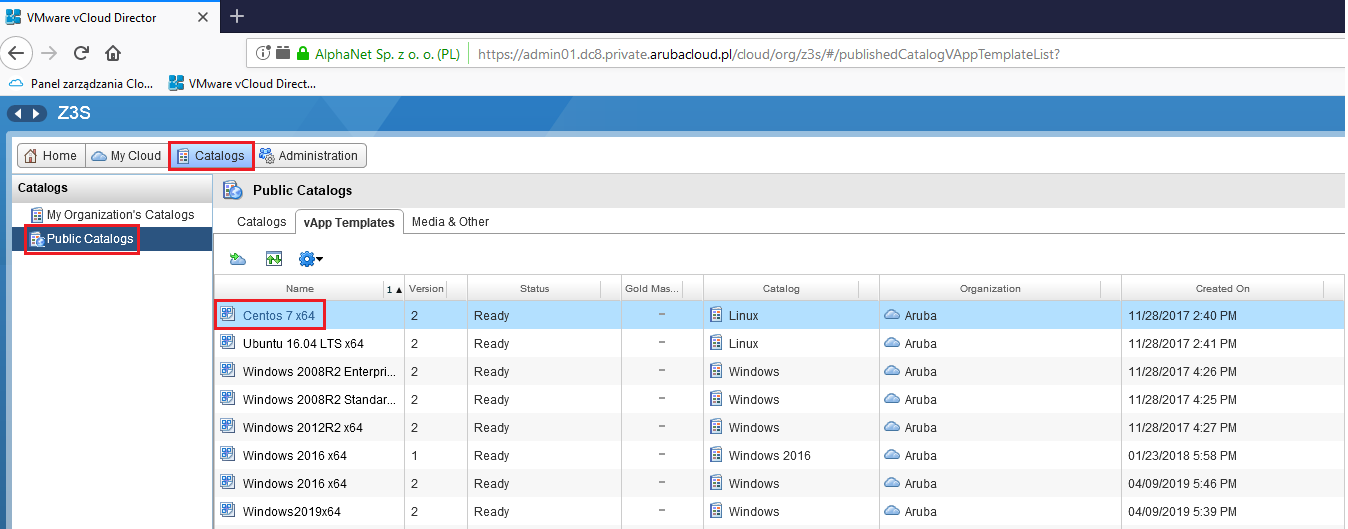
Każdy plik .tf zawierający kod może opisywać konkretny fragment infrastruktury, taki jak konfiguracja aplikacji (vApp), definicje sieci (Network) czy reguły firewalla (Firewall). Na początku zaczynamy od zdefiniowania wartości naszych zmiennych – będą to parametry podłączenia Terraforma do API vCloud Directora. W tym celu, korzystając z dowolnego edytora, tworzymy plik o nazwie terraform.tfvars. Plik ten będzie zawierał następujące definicje:
vcd_user = "z3sadmin" # login vCloud Director
vcd_pass = "tajne_haslo_admina" # haslo vCloud Director
vcd_org = "Z3S" # nazwa organizacji vCloud Director
vcd_vdc = "vdc1-Z3S" # nazwa Virtual Data Center
vcd_url = "https://admin01.dc8.private.arubacloud.pl/api" # URL do API vCloud Director
vcd_edge = "gw1-Z3S" # nazwa bramy brzegowej NSX
vcd_catalog = "Linux" # nazwa katalogu obrazow systemow
vcd_template = "Centos 7 x64" # nazwa szablonu obrazu systemuPoszczególne wartości dla zmiennych związane z danymi logowania zostały wcześniej zdefiniowane na etapie konfiguracji usługi. URL API jest tożsamy z adresem do logowani do panelu, jaki możemy podejrzeć w panelu zarządzaniu usługą:

Samo API jest dostępne przez inną ścieżkę, dlatego kasujemy wszystko za rozszerzeniem .pl i po ukośniku dopisujemy frazę ,,api”, co w przypadku naszego środowiska utworzy nam następujący URL: https://admin01.dc8.private.arubacloud.pl/api
Plik zmiennych mamy już gotowy – możemy przejść do utworzenia pliku konfiguracyjnego Config.tf . Służy on do skonfigurowania połączenia w oparciu o zmienne i ich wartości, jakie zostały zdefiniowane wcześniej w pliku terraform.tfvars. Zawartość naszej konfiguracji wygląda w następujący sposób:
# vCD - Provider Variables
variable "vcd_user" {
description = "vCD User"
}
variable "vcd_pass" {
description = "vCD Password"
}
variable "vcd_org" {
description = "vCD Organization"
}
variable "vcd_url" {
description = "vCD URL"
}
variable "vcd_vdc" {
description = "vCD VDC"
}
variable "vcd_max_retry_timeout" {
description = "Retry Timeout"
default = "240"
}
# vCD - Provider Configuration
provider "vcd" {
user = "${var.vcd_user}"
password = "${var.vcd_pass}"
org = "${var.vcd_org}"
url = "${var.vcd_url}"
vdc = "${var.vcd_vdc}"
max_retry_timeout = "${var.vcd_max_retry_timeout}"
}Mając oba pliki możemy od razu sprawdzić, czy wszystkie definicje zostały przez nas wprowadzone poprawnie. W tym celu będąc w ścieżce, w której znajdują się oba pliki, wystarczy wydać polecenie:
terraform initWynik jego działania powinien przedstawiać się w następujący sposób:
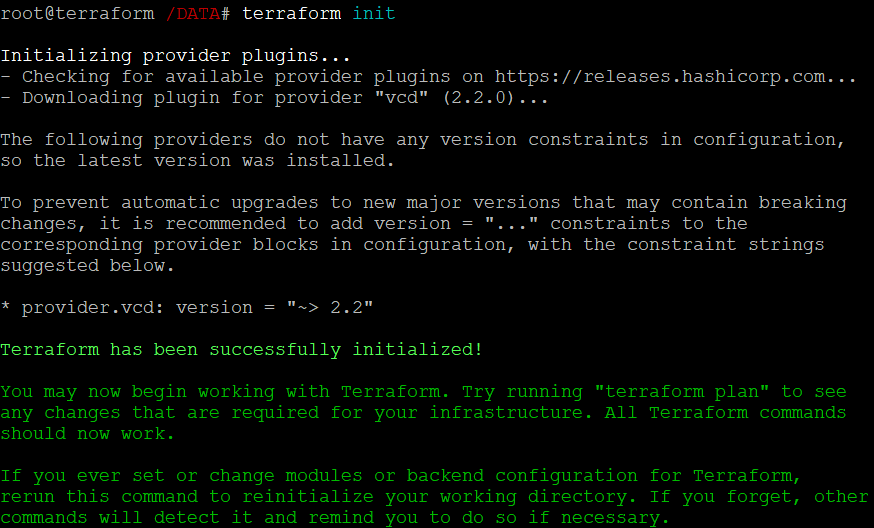
Jak widać powyżej Terraform sam w sposób automatyczny pobrał plugin wymagany do połączenia z providerem (vcd).
Gdy już sam Terraform został wstępnie przygotowany do pracy, możemy zacząć opisywać naszą infrastrukturę. W pierwszej kolejności utworzymy plik Network.tf, który będzie definiował parametry sieci wewnętrznej, w ramach której pracować będzie nasz serwer:
# vCD - Network Variables
variable "vcd_edge" {
description = "vCD Advanced Edge Gateway"
}
# vCD - Network Resource Definition
resource "vcd_network_routed" "net" {
org = "${var.vcd_org}"
vdc = "${var.vcd_vdc}"
name = "internal"
edge_gateway = "${var.vcd_edge}"
gateway = "10.10.10.254"
netmask = "255.255.255.0"
dns1 = "1.1.1.1"
dns2 = "8.8.4.4"
static_ip_pool {
start_address = "10.10.10.10"
end_address = "10.10.10.30"
}
dhcp_pool {
start_address = "10.10.10.200"
end_address = "10.10.10.210"
}
}Korzystamy tutaj z sieci typu 'routed’, dzięki czemu z wykorzystaniem reguł obsługiwanych przez bramę domyślną będziemy mogli na adres prywatny serwera realizować przekierowania wybranych portów z adresu publicznego. Sama definicja sieci jest dość przejrzysta i jak widać powyżej, zwiera w sobie: jej nazwę, maskę oraz adres bramy, definicje serwerów dns i konfigurację usługi dhcp.
Kolejno – mając już opis sieci – możemy utworzyć stosowne reguły, definiując je w pliku o nazwie Firewall.tf. Za samą obsługę polityk firewalla będzie odpowiedzialny nasz ,,Edge Gateway”:
#vCD- Firewall Ressource Definition
resource "vcd_snat" "outbound" {
vdc = "${var.vcd_vdc}"
edge_gateway = "${var.vcd_edge}"
external_ip = "80.211.247.25"
internal_ip = "10.10.10.0/24"
}
resource "vcd_firewall_rules" "fw" {
edge_gateway = "${var.vcd_edge}"
default_action = "drop"
rule {
description = "allow-http"
policy = "allow"
protocol = "tcp"
destination_port = "80"
destination_ip = "any"
source_port = "any"
source_ip = "10.10.10.0/24"
}
rule {
description = "allow-https"
policy = "allow"
protocol = "tcp"
destination_port = "443"
destination_ip = "any"
source_port = "any"
source_ip = "10.10.10.0/24"
}
rule {
description = "allow-ntp"
policy = "allow"
protocol = "udp"
destination_port = "123"
destination_ip = "any"
source_port = "any"
source_ip = "10.10.10.0/24"
}
rule {
description = "allow-dns"
policy = "allow"
protocol = "udp"
destination_port = "53"
destination_ip = "any"
source_port = "any"
source_ip = "10.10.10.0/24"
}
rule {
description = "allow-icmp"
policy = "allow"
protocol = "icmp"
destination_port = "any"
destination_ip = "any"
source_port = "any"
source_ip = "10.10.10.0/24"
}
rule {
description = "allow-ssh-public-web01"
policy = "allow"
protocol = "tcp"
destination_port = "40122"
destination_ip = "80.211.247.25"
source_port = "any"
source_ip = "any"
}
rule {
description = "allow-http-web01"
policy = "allow"
protocol = "tcp"
destination_port = "80"
destination_ip = "80.211.247.25"
source_port = "any"
source_ip = "any"
}
rule {
description = "allow-http-web01"
policy = "allow"
protocol = "tcp"
destination_port = "80"
destination_ip = "10.10.10.10"
source_port = "any"
source_ip = "any"
}
}
resource "vcd_dnat" "ssh-web01" {
vdc = "${var.vcd_vdc}"
edge_gateway = "${var.vcd_edge}"
external_ip = "80.211.247.25"
protocol = "tcp"
port = "40122"
internal_ip = "10.10.10.10"
translated_port = "22"
}
resource "vcd_dnat" "http-web01" {
vdc = "${var.vcd_vdc}"
edge_gateway = "${var.vcd_edge}"
external_ip = "80.211.247.25"
protocol = "tcp"
port = "80"
internal_ip = "10.10.10.10"
translated_port = "80"
}To, na co należy zwrócić uwagę zarówno w pliku Network.tf, jak i Firewall.tf, to odwołania do zmiennej ,,vcd_edge”, pod którą kryje się nazwa naszego ,,Edge Gateway”. Wartość zmiennej została zdefiniowana w pliku terraform.tfvars:
vcd_edge = "gw1-Z3S" # nazwa bramy brzegowej NSXNazwę ,,Edge Gateway” możemy odnaleźć po zalogowaniu się do vCloudDirectora i przejściu do zakładki ,,Administration”. Klikamy w niej na nazwę naszego wirtualnego data center:
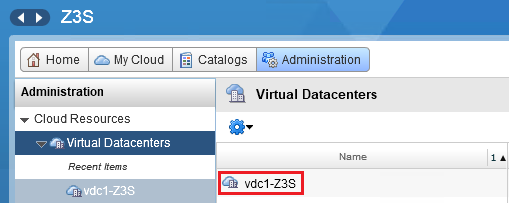
I następnie przechodząc do sekcji ,,Edge Gateways”:

Do ukończenia opisu środowiska w Terraform został nam już tylko jeden plik – ten najważniejszy, opisujący samą ,,wirtualną aplikację” – vApp.tf. Odpowiada on założeniom poczynionym na samym początku i wygląda w następujący sposób:
data "template_file" "init" {
template = "${file("${path.cwd}/setup.sh")}"
}
variable "vcd_catalog" {
description = "vCD Catalog Name"
}
variable "vcd_template" {
description = "vCD Template Name"
}
resource "vcd_vapp" "web" {
name = "klasterweb"
depends_on = ["vcd_network_routed.net"]
power_on = true
vdc = "${var.vcd_vdc}"
}
resource "vcd_vapp_vm" "web01" {
vapp_name = "${vcd_vapp.web.name}"
name = "web01"
catalog_name = "${var.vcd_catalog}"
template_name = "${var.vcd_template}"
memory = 4096
cpus = 4
cpu_cores = 4
network {
type = "org"
name = "${vcd_network_routed.net.name}"
ip = "10.10.10.10"
ip_allocation_mode = "MANUAL"
is_primary = true
}
initscript = "${data.template_file.init.rendered}"
depends_on = ["vcd_vapp.web"]
provisioner "local-exec" {
command = "ansible-playbook webserver.yml --vault-password-file vault_pass
"
}
}W początkowych wierszach vAPP.tf zdefiniowana została ścieżka do skryptu, jaki zostanie automatycznie uruchomiony wewnątrz maszyny podczas jej wdrożenia:
#!/bin/bash
localectl set-keymap us
mkdir -p ~/.ssh
echo 'ssh-rsa klucz_rsa root@localhost' > ~/.ssh/authorized_keys
exit 0Zasadniczo taki skrypt może dokonywać jakiejś wstępnej prekonfiguracji systemu. Nie jest to oczywiście konieczne, ponieważ wszystko możemy zrealizować na późniejszym etapie przy pomocy narzędzia, jakim jest Ansible.
Konfigurowanie i utrzymywanie środowiska przy pomocy Ansible
Od strony zasobów systemów operacyjnych i konfiguracji sieci nasza infrastruktura jest już w pełni opisana. Jedną z ciekawszych funkcji Terraforma jest możliwość budowania grafów, co pozwala na zwizualizowanie zależności pomiędzy poszczególnymi elementami umieszczonymi w kodzie infrastruktury. Poniższy graf przedstawiający naszą infrastrukturę został wykonany przy wykorzystaniu zewnętrznego narzędzia blast-radius (https://github.com/28mm/blast-radius):

Wszystkie nasze zasoby zostały utworzone i uruchomione – teraz należy przejść do kolejnego etapu, w którym dalsze działania zostaną przeprowadzone ,,od wewnątrz” naszej wirtualnej instancji. Do tego właśnie potrzebujemy wspomnianego wcześniej ,,provisionera”.
Ansible, podobnie jak Terraforma, również instalujemy na zewnętrznym systemie – w naszym przypadku będzie to ten sam lokalny serwer z systemem Debian. Instalacja sprowadza się do zainstalowania Pythona oraz narzędzia ,,pip”, a następnie instalacji samego Ansible:
sudo apt -y install python python-pip && pip install ansible && pip install cryptography ansible –version
Gdy już narzędzie jest gotowe do pracy, możemy zacząć przygotowywać pierwszego playbooka.
Przyjrzyjmy się jeszcze zawartości naszego katalogu roboczego, który zawiera zarówno kod opisujący infrastrukturę, jak i konfiguracje Ansible wraz z playbookiem:
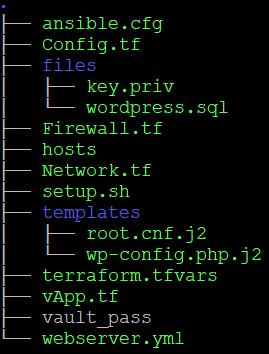
ansible.cfg to plik zawierający wszystkie domyślne ustawienia środowiska, w tym definicję pliku zasobów (inventory):
[defaults]
inventory=hosts
host_key_checking = False
remote_user = root
private_key_file = files/key.privSam plik zasobów o nazwie hosts przedstawia się w następujący sposób:
[webservers]
web01 ansible_host=80.211.247.25 ansible_port=40122webserver.yml to playbook Ansible, w którym zostały kolejno opisane wszystkie czynności konfiguracyjne:
- name: Deploy Webserver with httpd, php, mariadb and install WordPress
hosts: webservers
gather_facts: no
vars:
mysql_root_password: !vault |
$ANSIBLE_VAULT;1.1;AES256
38323231653633383839373137313637346666316536393966613836333436353231616532343363
3832323838343039356631316235396662663365303130340a373766666166396234653833323965
62633362323133323237613037646334396339643134343036386466643532386537353138316333
6563633731616431640a646531373162303364313035366233356234613933373439623930633164
61373231653438323064366334336666623764363365373732636334636632376339
wordpress_password: !vault |
$ANSIBLE_VAULT;1.1;AES256
62353237326335373961306163353262613830336435323739643630643338303435613561383431
6465633434306362663536313332363961666330623130650a663832363330393264363437303135
31613332646239666561396465306331653135353833366163313664386536616334313931306139
3465623865353163630a636135613833333864636436393636663339393439623962616334353932
3161
become: True
tasks:
- name: Wait max 300 seconds for SSH service, connect and check for contain "OpenSSH"
wait_for:
port: "{{ ansible_port }}"
host: '{{ (ansible_ssh_host|default(ansible_host))|default(inventory_hostname) }}'
search_regex: OpenSSH
delay: 5
connect_timeout: 300
connection: local
- name: install httpd + php
yum: name={{ item }} state=present
with_items:
- httpd
- php
- php-mysql
- name: Download WordPress
unarchive:
src=https://pl.wordpress.org/latest-pl_PL.tar.gz
dest=/var/www/html
remote_src=yes
- name: Install MariaDB Database
yum: name=mariadb-server state=present
- name: Install the Python MySQL libs
yum: pkg=MySQL-python state=latest
- name: Start and enable mariadb
service: name=mariadb state=started enabled=true
- name: Set root user password
mysql_user:
name: root
password: "{{ mysql_root_password }}"
check_implicit_admin: true
- name: Create .my.cnf
template:
src: "root.cnf.j2"
dest: "/root/.my.cnf"
owner: root
group: root
mode: 0600
- name: Removes anonymous users
mysql_user:
name: ''
host: localhost
state: absent
- name: Crate wordpress user
mysql_user:
name: wordpress
password: "{{ wordpress_password }}"
priv: 'wordpress.*:ALL,GRANT'
- name: Create a wordpress database
mysql_db: name=wordpress state=present login_user=wordpress login_password="{{ wordpress_password }}"
- name: Copy wordpress conf file
template:
src: wp-config.php.j2
dest: /var/www/html/wordpress/wp-config.php
mode: 0600
owner: apache
- name: Copy database dump file
copy:
src: files/wordpress.sql
dest: /tmp
- name: Restore database
mysql_db:
name: wordpress
state: import
target: /tmp/wordpress.sql
- name: start httpd
service: name=httpd state=started enabled=yes
- name: restart mariadb
service: name=mariadb state=restarted
Stosowanie haseł w jawnej postaci nigdy nie jest dobrym pomysłem – nawet w przypadku środowiska testowego. W przypadku Ansible dzięki tzw. Vaults możemy w bezpieczny sposób przechowywać wszystkie sensytywne dane w zaszyfrowanych wartościach lub odrębnych plikach: https://docs.ansible.com/ansible/latest/user_guide/vault.html
W naszym przykładzie mamy dwie zmienne, dla których wartości zostały zaszyfrowane z wykorzystaniem algorytmu AES256:
vars:
mysql_root_password: !vault |
$ANSIBLE_VAULT;1.1;AES256
38323231653633383839373137313637346666316536393966613836333436353231616532343363
3832323838343039356631316235396662663365303130340a373766666166396234653833323965
62633362323133323237613037646334396339643134343036386466643532386537353138316333
6563633731616431640a646531373162303364313035366233356234613933373439623930633164
61373231653438323064366334336666623764363365373732636334636632376339
wordpress_password: !vault |
$ANSIBLE_VAULT;1.1;AES256
62353237326335373961306163353262613830336435323739643630643338303435613561383431
6465633434306362663536313332363961666330623130650a663832363330393264363437303135
31613332646239666561396465306331653135353833366163313664386536616334313931306139
3465623865353163630a636135613833333864636436393636663339393439623962616334353932
3161Sam klucz szyfrujący to znane tylko nam hasło – może być ono przekazywane jako parametry przy uruchamianiu playbooka (interaktywnie) lub ładowane z pliku, który je zawiera (za co odpowiada parametr ,,–vault-password-file”). Samo utworzenie pliku haseł oraz zaszyfrowania wartości zmiennych wygląda w następujący sposób:
echo 'secretpassword' > vault_pass
chmod 400 vault_pass
ansible-vault encrypt_string --vault-password-file vault_pass 'rootpasswordveryhardlevel' --name 'mysql_root_password'
ansible-vault encrypt_string --vault-password-file vault_pass 'wordpress' --name 'wordpress_password'Wynik powyżej wykonanych poleceń powinien być zbliżony do poniższego:

Oczywiście w takim wypadku najistotniejszą kwestią jest właściwe zabezpieczenie pliku zawierającego hasła (vault_pass).
Na podstawie zawartości powyższego playbooka Ansible przeprowadzi następujące akcje:
- Oczekuje maksymalnie 300 sekund na uruchomienie usługi OpenSSH na naszym serwerze.
- Instaluje usługę httpd oraz biblioteki php.
- Pobiera i rozpakowuje archiwum z najnowszą wersją WordPressa (polskojęzyczną).
- Instaluje bazę danych MariaDB.
- Instaluje biblioteki Python MySQL.
- Uruchamia i włącza usługę MariaDB.
- Ustawia hasło użytkownika root dla usługi MariaDB.
- Tworzy plik konfiguracyjny /root/.my.cnf.
- Usuwa z konfiguracji MariaDB użytkowników anonimowych.
- Tworzy użytkownika o nazwie wordpress i nadaje mu uprawnienia do bazy o nazwie wordpress.
- Tworzy bazę danych o nazwie wordpress.
- Kopiuje gotowy plik konfiguracyjny wp-config.php.j2 do ścieżki /var/www/html/wordpress/wp-config.php.
- Kopiuje plik zrzutu bazy danych do katalogu /tmp.
- Odtwarza bazę danych z pliku zrzutu.
- Uruchamia i włącza usługę httpd.
- Restartuje usługę MariaDB.
Aby powyższe działania mogły być zrealizowane, Ansible musi mieć możliwość połączenia z serwerem docelowym przez protokół SSH. Całą operację provisioningu wykonujemy jednym poleceniem:
ansible-playbook webserver.ymlW naszym przykładzie nie musimy tego robić- powyższe polecenie zostanie wywołane w ramach wdrożenia realizowanego przez Terraforma – w vApp.tf odpowiedzialna jest za to następująca część kodu:
provisioner "local-exec" {
command = "ansible-playbook webserver.yml --vault-password-file vault_pass
"
}Polecenie [terraform apply] musi być w takim wypadku wykonane z głównego katalogu – z tej samej ścieżki zadziała też Ansible i będzie oczekiwał widoczności wszystkich wymaganych plików w tej samej lokalizacji. To tyle, jeżeli chodzi o naszą testową infrastrukturę. Na koniec wydajemy zestaw poniższych poleceń i oczekujemy na efekt końcowy ich działania:
terraform init
terraform plan -out deployment
terraform apply "deployment"Jak widać na poniższym zrzucie, cały proces zajął około dwóch i pół minuty:
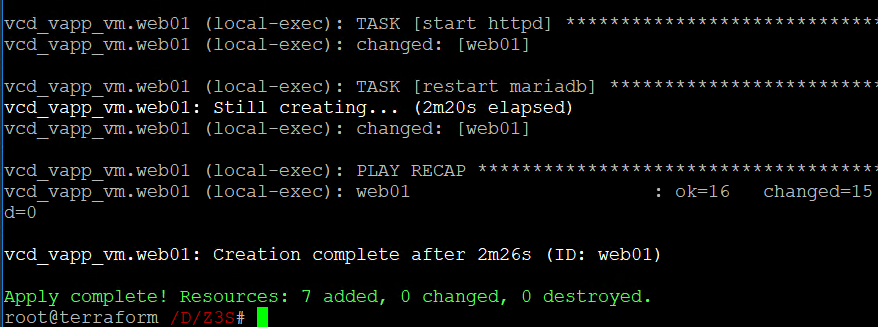
Wszystkie pliki wykorzystane w naszym przykładzie możecie pobrać z wykorzystaniem poniższego linku (hasło: z3s):
https://zaufanatrzeciastrona.pl/wp-content/uploads/2019/06/z3s-archiwum.zip
W zaprezentowanym przykładowym środowisku zależało nam przede wszystkim na jego prostocie – w końcu dla niektórych z Was będzie to pierwsza styczność z tym narzędziem. Uproszczenia jednak nie są dobre tam, gdzie środowisko nie będzie tym w pełni testowym. Minimalnie zalecamy zmodyfikowanie zaprezentowanych plików przez dodanie do konfiguracji własnej pary kluczy SSH.
Możecie również rozważyć wdrożenie konfiguracji tunelu IPSec, w ramach to którego Ansible będzie komunikował się z instancjami maszyn wdrożonymi przez Terraforma: https://www.terraform.io/docs/providers/vcd/r/edgegateway_vpn.html
Na zakończenie podajemy Wam bezpośrednie linki do dokumentacji produktów – poza samymi opisami poszczególnych modułów zawiera ona też instrukcje dla początkujących typu ,,getting started”:



Komentarze
tf state powinno byc trzymane w bazie (np DynamoDB). Wtedy mozliwa bedzie praca wielu osob na raz a sam plik nie bedzie wazny.
Niestety to ta sama aruba. Siedzi u mnie w FW od dawna. Spam snowshoe.
Czy ta aruba ma cos wspolnego z aruba.it? Zablokowalem wczoraj cala klase 80.211.0.0/16 za spam.
Tak, ale trzymanie w bazie to nie jedyna mozliwosc. Moze byc jako remote state trzymany w backend w dowolnej chmurze.
Dobry artykuł.
Kapitalny artykuł!
Środowisko tworzone w ten sposób jest łatwiejsze do zrozumienia, a co za tym idzie zabezpieczenia.
Detekcja czy odpowiedź na incydenty też zupełnie inna bajka.
Trudniej też popełnić błędy, które popełnilibyśmy ręcznie (oczywiście tutaj będą się one propagowały, ale łatwiej zweryfikować, że i nich ma, skanować, etc).
Można łatwo dorzucić narzędzia takie jak audisp-json (i wiedzieć, że są wszędzie), wymusić centralne logowanie, etc.
Łatwiej wymienić hasła w trakcie incydentu.
Dwa komentarze
– wszystko co poufne, trzymamy w katalogu „vars” i szyfrujemy przez ansible-vault, w kodzie odwołując się tylko do nazwy zmiennej, do tego szablony i jest naprawdę ładnie
– jeśli polityka, umiejętności i czas pozwalają, warto trzymać sekrety w KSM (lub czymś podobnym) – i wtedy w repo nie ma zbyt wiele wartościowych informacji