Czy Foreshadow jest groźniejszy niż poprzednie luki Intela? Czy jest się czego bać? W tekście przedstawiamy zasady działania zagrożenia oraz opisujemy, jaki wpływ na wydajność ma luka L1TF.
W sierpniu tego roku wydawało się już, że skutki zagrożeń Meltdown i Spectre są znane, a sytuacja jest opanowana. Intel zaproponował łatki i nowe sterowniki poprawiające (chociaż częściowo) błędy, zaczęto też prowadzić publiczną dyskusję – na konferencjach i w mediach – na temat rozwiązań architekturalnych. Dodatkowo uspokajająco podziałała prezentacja na temat luki TLBleed, która w przeważającej większości komentarzy została uznana za błąd w użyciu mechanizmu procesora, a nie prawdziwą lukę bezpieczeństwa – czyli fałszywy alarm. W tej sytuacji opublikowanie informacji na temat luki L1TF i potwierdzenie tych wiadomości przez Intela było przysłowiowym “gromem z jasnego nieba”, który wywołał falę rozentuzjazmowanych komentarzy. Spekulowano o końcu bezpieczeństwa na poziomie sprzętu i kolejnych możliwych zagrożeniach. Niestety przy opisie możliwych konsekwencji ataku opierano się często na fałszywych przesłankach. Zakładano, że spekulacyjne wykonywanie kodu nie pozostawia śladów, gdy prognoza jest błędna, ponieważ wyniki zostają odrzucone. To ostatnie twierdzenie jest prawdziwe tylko dla logiki programu – nie występują błędy obliczeniowe. Stany w procesorze są jednak inne niż w przypadku prawidłowej prognozy. Ponadto, dzięki stale zwiększającej się pojemności pamięci głównych, dane są często posortowane i bezpośrednio adresowalne – atakujący nie musi już pracować z oknami i zakresami obszarów pamięci. Oba czynniki znacznie ułatwiają przeprowadzanie ataków. Dlatego teraz po kilku miesiącach można pokusić się o rzeczową analizę. Czy L1TF jest groźny dla mnie, mojej firmy lub organizacji? Czy są już dostępne łatki i jakie są spadki wydajności? Na te i inne pytania odpowiem w dalszej części artykułu.
Powtórka z teorii
Foreshadow, tak jak Meltdown, opiera się na wykorzystaniu podatności wynikających z konstrukcji współczesnych procesorów Intela: mikrooperacji (ang. micro-operations) oraz spekulacyjnego wykonania instrukcji (ang. speculative execution). Procesory Intela, mimo że teoretycznie należą do rodziny CISC (ang. Complex Instruction Set Computing), od dłuższego czasu wykorzystują mikrooperacje, by poprawić wydajność. Technika ta polega na podzieleniu wybranych instrukcji maszynowych na mniejsze tzw. mikrooperacje podczas dekodowania w potoku (ang. pipeline). Pozwala to nie tylko na uproszczenie budowy procesora bez zmiany modelu programowego, ale też na poprawienie jego wydajności poprzez mechanizmy znane z konkurencyjnych architektur RISC. Drugim z mechanizmów jest wykonanie spekulacyjne instrukcji (i mikrooperacji). Jest to technika optymalizacji czasu pracy procesora polegająca na wykonywaniu pewnych instrukcji znajdujących się w potoku (np. takich, które występują po skoku warunkowym), mimo że jeszcze nie wiadomo, czy warunek konieczny dla ich użycia wystąpi. Wyniki uzyskane z wyprzedzeniem zostaną albo uwzględnione, albo odrzucone – w zależności od tego, czy dany warunek logiczny jest spełniony, czy też nie. Wykonanie spekulacyjne należy do rodziny mechanizmów pozwalających na wykonanie instrukcji poza kolejnością (ang. out of order execution) w potoku procesora, tak aby jak najefektywniej wykorzystać czas pracy maszyny. Niestety, takie rozwiązanie może prowadzić do sytuacji, w której programista traci kontrolę nad tym, kiedy i jakie rozkazy procesora zostaną wykonane – chodzi np. o scenariusz wyścigu (hazardu), w którym mikrooperacje są wykonywane, mimo że jeszcze nie skończył się dla nich warunkowy proces autoryzacji. Właśnie ta właściwość stanowi podstawę ataku L1TF Foreshadow.
Enklawy SGX w architekturach Intela
Głównym celem ataku L1TF są fragmenty systemu chronione przez sprzętowe mechanizmy bezpieczeństwa Intela, który od dawna pracował nad wzmocnieniem ochrony użytkowników swoich produktów. Wynikiem wieloletnich starań firmy są enklawy SGX (ang. Intel Software Guard Extensions). Mechanizm ten dodaje do architektury procesora zestaw instrukcji, które umożliwiają aplikacjom działającym w przestrzeni użytkownika (trzeci pierścień ochrony) alokowanie prywatnych zakresów pamięci, zwanych enklawami, które będą chronione przed procesami działającymi na wyższych poziomach uprawnień (np. opanowany przez atakującego kernel). Dostęp do danych z enklawy jest przeprowadzany dla użytkownika z poziomu pamięci wirtualnej, jednak prawa dostępu są sprawdzane na poziomie sprzętowym, przez procesor wykonujący konkretne instrukcje. Takie wykonanie gwarantuje, że zainfekowane oprogramowanie systemowe nie może uzyskać dostępu do pamięci prywatnej enklawy, mimo że wciąż może nią zarządzać (np. alokacja, dealokowanie i mapowanie stron). CPU z obsługą SGX weryfikuje proces tłumaczenia adresów wirtualnych na fizyczne i może zasygnalizować błąd strony (ang. page fault) podczas próby dostępu przez nieuprawniony proces do zakresu pamięci enklawy. Wszelkie próby nieuprawnionego (w tym bezpośredniego) dostępu do prywatnych stron enklawy są ignorowane (zwracana jest wartość -1).
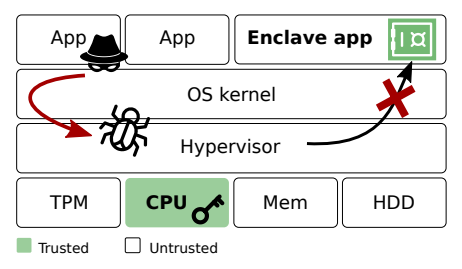
Schemat działania enklawy SGX, źródło.
Enklawy przez długi czas uchodziły za odporne na nowe ataki, np. typu Meltdown. Najdobitniej świadczą o tym nagłówki prasowe, np. International Business Times w artykule z 26 lutego tego roku zatytułowanym “Meltdown stopił wszystko za wyjątkiem jednego elementu” pisze “w przypadku ataku enklawy pozostają chronione i w 100% bezpieczne”. Jednak to właśnie enklawy SGX stały się głównym obiektem ataku Foreshadow L1TF, który w przeciwieństwie do poprzednich ataków na SGX nie wymaga założeń dotyczących kodu ofiary i niekoniecznie wymaga dostępu do systemu na poziomie kernela.
Atak Foreshadow
Tak jak w przypadku luk Meltdown i Spectre, L1TF Foreshadow cechuje bardzo wysoki stopień skomplikowania. Opis zaczniemy od przedstawienia ogólnych założeń koncepcyjnych tego ataku.
Podczas dostępu do pamięci na maszynach z włączoną wirtualizacją adres liniowy (ang. linear address) jest wykorzystywany do obliczania adresu fizycznego za pomocą bufora TLB (ang. translation lookaside buffer). TLB to pamięć podręczna służąca do skracania czasu dostępu do fizycznej lokalizacji pamięci użytkownika, będąca częścią jednostki zarządzającej pamięcią (MMU). TLB jest używany do obsługi pamięci wirtualnej i zawiera listę często używanych powiązań (ang. transactions) pomiędzy adresami wirtualnymi a liniowymi – często nazywany jest cache’em pamięci wirtualnej. Jeśli powiązanie pomiędzy adresem wirtualnym znajduje się w TLB, operacja na danych z pamięci może zostać wykonana szybciej – powiązanie jest dostępne niemal natychmiastowo. W przeciwnym wypadku powiązanie pomiędzy pamięcią wirtualną musi zostać ustanowione – tzw. page walk. Jest to proces czasochłonny w porównaniu z szybkością procesora, ponieważ wiąże się z odczytem zawartości wielu lokalizacji pamięci i wykorzystaniem ich do obliczania adresu fizycznego. Błąd strony (ang. page fault) jest sygnalizowany, jeśli page walk się nie powiódł, tzn. powiązanie nie istnieje bądź chodzi o dostęp do pamięci zastrzeżonej, np. kernela.
Atak L1TF celuje w ten właśnie mechanizm. Atakujący celowo wybiera taki adres liniowy który doprowadzi do wystąpienia błędu strony. Błąd w konstrukcji procesora polega na tym, że dane z dostępu do pamięci zastrzeżonej są przez krótki czas dostępne dla wykonanie spekulacyjnego zanim procesor wyśle komunikat (page fault) o błędzie i powróci do bezpiecznego stanu poprzez cofnięcie spekulacyjnie wykonanych mikroperacji. Tworzy to sytuację wyścigu (ang. race condition).
Podczas przygotowywania błędu strony procesor wciąż spekulacyjnie oblicza adres fizyczny z informacji znajdujących się w strukturze strony (ang. page structure) w TLB i adresu liniowego, który doprowadził do wystąpienia błędu. Jeśli dane z tego adresu fizycznego są wciąż obecne w pamięci podręcznej pierwszego poziomu (ang. L1 procesor cache), to mogą one zostać pobrane i przekazane do kolejnych mikroperacji wykonujących się wciąż spekulacyjne. Właśnie te instrukcje mogą tworzyć boczny kanał ataku. Ponieważ uzyskany w ten sposób adres fizyczny nie jest wynikiem pracy TLB, architekt założył, że TLB zwróci błąd, a adres wynikowy nie jest walidowany poprzez mechanizmy sprawdzające prawa dostępu do pamięci. Nazwa ataku L1TF pochodzi zatem od wykorzystywanych elementów: L1 cache i terminal fault. L1TF pozwala na ominięcie:
- kontroli dostępu do pamięci chronionych przez enklawy SGX Intela,
- sprawdzenia rozszerzonej tabeli stron (EPT),
- kontroli dostępu do pamięci chronionej SMM.
Nieautoryzowany dostęp do chronionych zakresów pamięci jest główną różnicą pomiędzy F1TF a poprzednimi atakami, gdyż wyżej wymienione mechanizmy uchodziły za bezpieczne (znane ataki miały bardzo wysoki stopień skomplikowania i często robiły daleko idące założenia na temat aplikacji pracującej w enklawie).
Przebieg ataku
Celem podstawowego wariantu ataku jest pobranie pojedynczego bajtu informacji z enklawy. Dokonuje się tego w trzech fazach:
- Załadowanie danych z enklawy do pamięci podręcznej L1 procesora.
- Przygotowanie TLB tak, by wystąpił wybrany błąd strony z wybranymi operacjami, które będą wykonane spekulacyjnie.
- Nieautoryzowane pobranie danych z L1.
Fazy te opiszemy w tej właśnie kolejności. Faza 1 zaczyna się od wymuszenia wykonania aplikacji wykorzystującej enklawę SGX, np. poprzez odpowiednio spreparowaną aplikację hosta, tak by dane z enklawy zostały załadowane do pamięci podręcznej L1. Badania autorów ataku jednoznacznie wykazały, że czas pomiędzy wystąpieniem błędu strony a reakcja na niego są zbyt krótkie na dostęp do dalszych poziomów z hierarchii pamięci (np. L2, L3 czy DRAM). Warto zauważyć, że dane z enklawy SGX są przechowywane jako plaintext w pamięci podręcznej. Specyfikacja mechanizmu Intela szyfrującego sprzętowo dane z enklawy zakłada, że procesor (i cała jego infrastruktura, czyli tzw. package, włączając wszystkie poziomy pamięci podręcznej) jest bezpieczny. Dane z enklawy są szyfrowane i deszyfrowane podczas dostępu do pamięci DRAM. Sukces ataku oznacza zatem bezpośredni dostęp do informacji. W drugiej fazie ataku atakujący przygotowuje sekwencje instrukcji (mikroperacji), które doprowadzą do pobrania danych. Przykładowy listing kodu przedstawiony jest poniżej.
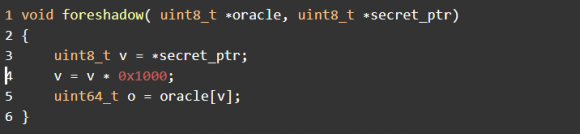
Odwołanie (zderefencjonowanie) pamięci enklawy, do której użytkownik nie ma praw dostępu, standardowo nie powoduje wystąpienia błędu strony. Mechanizm SGX usuwa zawartość strony i zastępuje ją jakąś domyślną wartością, w przypadku Intela jest to −1. Ze względu na brak wyjątku nie ma też sytuacji wyścigu i atak nie mógłby wystąpić. By poradzić sobie z tym problemem, autorzy ataku wykorzystali fakt, że ten mechanizm SGX-a jest zaimplementowany po wykonaniu tradycyjnej ochrony pamięci wirtualnej bazującej na stronach. Jeśli więc błąd strony wystąpi w TLB, to sprawdzanie praw dostępu nie jest wykonywane. W związku z tym atakujący nie musi mieć praw dostępu do pamięci enklawy bądź obawiać się, że dane zostaną zastąpione jakimś hashem. Zatem mimo że linia 3 spowoduje błąd strony, to instrukcje z linii 4 i 5 zostaną wykonane w sposób spekulacyjny, by policzyć adres elementu v w buforze wyroczni (ang. oracle buffer) przed jego pobraniem z pamięci. ∗oracle to wskaźnik do bufora wyroczni, który jest tablicą, a jej dane NIE znajdują się w pamięci podręcznej. Atakujący może upewnić się, że warunek ten jest spełniony poprzez użycie instrukturcji cflush dla wszystkich jego elementów. Jest to ważne, gdyż po wykonaniu ataku pomiar czasu dostępu do elementu będzie wskazywał na to, czy dane pochodzą z enklawy (pamięć podręczna L1) czy nie (np. pamięć główna). Wskaźnik ∗secret_ptr doprowadzi do błędu strony na wybranym przez nas adresie, po którym nastąpi wykonanie spekulacyjne. Tutaj czas na dygresję w odniesieniu do enklaw SGX.
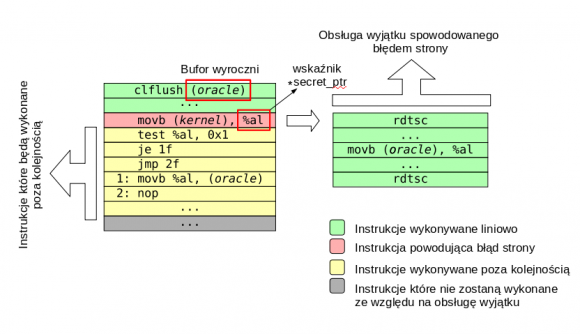
Schemat ataku L1TF foreshadow z kodem w assemblerze dla kodu z wcześniejszej części artykułu.
W fazie trzeciej procesor rozpoczyna obsługę błędu strony i przywraca stan procesora sprzed jego wystąpienia. Następnie system operacyjny zaczyna obsługę tego błędu w przestrzeni użytkownika. W związku z tym atakujący może napisać własną obsługę wyjątków, która mierzy czas dostępu do wszystkich elementów z bufora wyroczni. Jeśli czas dostępu do któregoś z nich jest wyraźnie krótszy niż do innych, mamy dostęp do danych z pamięci podręcznej L1 i będą to dane z enklawy SGX.
Ograniczenia ataku
Już z powyższego opisu można wywnioskować, że atak ma bardzo poważne ograniczenia. Po pierwsze L1TF może być wykonany, tylko jeśli dane, które są celem ataku, znajdują się już w pamięci podręcznej L1 procesora. Warto zauważyć, że dane w L1 są zastępowane bardzo szybko, więc okno czasowe dla atakującego jest bardzo krótkie. Po drugie złośliwy kod musi być wykonany na tym samym fizycznym rdzeniu procesora co kod enklawy. Warto zauważyć, że większość procesorów Intela implementuje teraz mechanizm wielowątkowości współbieżnej – hyper threading. W takich systemach rdzenie logiczne (wirtualne) pracujące na tym samym fizycznym rdzeniu współdzielą pamięć podręczną poziomu pierwszego. Oznacza to, że dane wczytane do L1 przez jeden procesor logiczny mogą być spekulacyjnie dostępne przez kod uruchomiony na innym procesorze logicznym. Ponadto atakujący musi zgadnąć strukturę strony w TLB, której zdekodowanie doprowadziłoby do pobrania danych z fizycznego adresu znajdującego się w pamięci enklawy.
Ocena Intela
Intel został poinformowany o ataku przez autorów 3 stycznia 2018 roku, jednak za obopólną zgodą autorzy zgodzili się nie publikować wyników do sierpnia tego roku. Przez siedem miesięcy pracownicy firmy Inel oprócz potwierdzenia wyników dla SGX zaprezentowali również warianty dla SMM i VMM. Na dzień dzisiejszy znane są zatem trzy warianty ataku:
- podstawowy L1 Terminal Fault-SGX (CVE-2018-3615) na enklawy SGX (omówiony w tym artykule), który jest opisywany jako zagrożenie o wysokim stopniu (7.3/10 high),
- L1 Terminal Fault-OS/ SMM (CVE-2018-3620), w którym atakujący za pomocą L1TF odczytuje z pamięci podręcznej dane z całości systemu – zagrożenie średnie (6.5/10),
- L1 Terminal Fault-VMM (CVE-2018-3646), w którym atakujący operujący z maszyny wirtualnej za pomocą L1TF odczytuje z pamięci podręcznej dane z całości systemu (6.5/10).
Mimo że Intel uznaje zagrożenie za istniejące, zwraca jednocześnie uwagę, że jego praktyczne zastosowanie pozostaje w sferze spekulacji. Jest to związane z wysokim stopniem skomplikowania ataku, a także wąskim zakresem dostępu do danych (tylko pamięć podręczna pierwszego poziomu). W istocie, jak dotąd nie zostały przedstawione praktyczne przykłady użycia L1TF w celu uzyskania wymiernych korzyści (a nie skoncentrowanych na pobraniu losowych bajtów danych). Na L1TF podatne są następujące modele od producenta:
- procesory generacji 2/3/4/5/6/7/8,
- seria Intel Core X dla platform Intel X99 i X299,
- rodzina Intel Xeon E3 v1/v2/v3/v4/v5/v6,
- rodzina Intel Xeon E5 v1/v2/v3/v4,
- rodzina Intel E7 v1/v2/v3/v4,
- rodzina procesorów Intel Xeon Scalable,
- jak i procesor Intel Xeon D (1500, 2100).
Intel wypuścił już patche w mikro-kodzie, które likwidują sytuacje wyścigu w większości z wymienionych produktów i pozwalają uniknąć zagrożenia. Wyniki większości benchmarków potwierdzają, że wpływ łatek na wydajność jest minimalny w przypadku większości zastosowań dla systemów typu PC. Jednak przedstawione wyniki – patrz poniżej – potwierdzają też, że wyłączenie hyper threadingu wymagane do zabezpieczenia przed L1TF znacząco zmniejsza wydajność procesorów Xeon w wielu aplikacjach serwerowych (co było do przewidzenia). Spadki wydajności są największe w przypadku serwerów z wieloma maszynami wirtualnymi (ataków z użyciem złośliwych wirtualnych maszyn). Sprzętowe mechanizmy ochronne obiecane przez Intela dla następnych generacji procesorów Intela mają zapewnić zdecydowanie lepszą wydajność niż aktualizacje mikrokodów. Przyjdzie nam na nie jednak trochę poczekać.
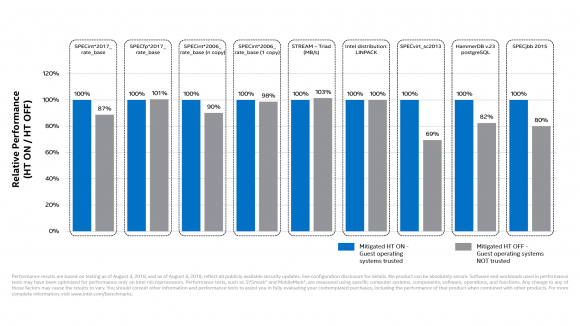
Wyniki wydajności dla procesorów w zastosowaniach serwerowych z patchami likwidującymi podatność L1TF, źródło Intel.
Podsumowanie
Luki typu L1TF i Meltdown to bez wątpienia przełom, jeśli chodzi o bezpieczeństwo systemów. Do tej pory zakładano, że sprzęt (np. procesor) jest stosunkowo bezpieczny ze względu na inny proces produkcyjny niż w przypadku oprogramowania. W związku z tym większość wysiłków instytucjonalnych zorientowana była na poszukiwaniu błędów w oprogramowaniu i ciągłych aktualizacjach. Luki typu L1TF, Meltdown i Spectre pokazały, że agresywne metody optymalizacji, takie jak wykonywanie poza kolejnością czy spekulacyjne wykonywanie kodu, mogą zniwelować działanie programowych mechanizmów bezpieczeństwa. Zagrożeń tego typu nie da się uniknąć bez głębokich zmian w architekturze, wpływających na całe procesy produkcyjne. Co gorsza, trzeba się liczyć ze stratami wydajności, które na domiar złego w większości wypadków są nie do zaakceptowania dla wielu obecnych klientów, np. dostawców usług internetowych. No dobrze, a skąd termin “foreshadow”? Jest to angielski termin do określenia narzędzia pisarskiego, za pomocą którego autor powieści zdradza w subtelny sposób to, co za chwilę ma nastąpić.
Adam Kostrzewa: Od ośmiu lat zajmuję się badaniami naukowymi i doradztwem przemysłowym w zakresie elektroniki motoryzacyjnej, a w szczególności systemów wbudowanych pracujących w czasie rzeczywistym do zastosowań mogących mieć krytyczne znaczenie dla bezpieczeństwa użytkowników. W wolnym czasie jestem entuzjastą bezpieczeństwa danych. Szczególnie interesujące są dla mnie sprzętowe aspekty implementacji obwodów elektrycznych i produkcji krzemu. Metody i narzędzia używane do tych zadań nie są aż tak dostępne i dokładnie przetestowane jak oprogramowanie, dlatego też stanowią interesującą dziedzinę do badań i eksperymentów.
Blog: adamkostrzewa.github.io
Twitter: twitter.com/systemWbudowany



Komentarze
jak zawsze bardzo profesjonalny artykuł
czy ma pan w planach poruszyć temat hardware-based encryption i związanych z nim zagrożeń http://bits-please.blogspot.com/2016/06/extracting-qualcomms-keymaster-keys.html https://www.theregister.co.uk/2016/07/01/turns_out_breaking_android_fulldisk_encryption_is_easy_with_the_right_code/ ?
Cieszę że się podoba! Dziękuję za linki i nie wykluczam że w przyszłości coś będzie na ten temat!
„Warto zauważyć, że większość procesorów Intela implementuje teraz mechanizm wielowątkowości współbieżnej – hyper threading.”
Tylko, ze ostatnio zaleca sie wylaczenie HT ze wzgledu na spadek wydajnosci i podatnosc na kolejne bledy typu timing atack:
„Mark Kettenis of the OpenBSD project, said the OpenBSD team was removing support for Intel HT because, by design, this technology just opens the door for more timing attacks. Timing attacks are a class of cryptographic attacks through which a third-party observer can deduce the content of encrypted data by recording and analyzing the time taken to execute cryptographic algorithms. The OpenBSD team is now stepping in to provide a new setting to disable HT support because „many modern machines no longer provide the ability to disable hyper-threading in the BIOS setup.””
Nie moge teraz znalezc wzmianki o tym, ze przy wlaczonym HT we wspolczenych srodowiskach mozna zauwazyc spadek wydajnosci.
Zgadzam się w 100% / piszę na ten temat w ostatniej sekcji artykułu („Ocena Intela”) dokładne wyniki Intela jeśli chodzi o spadki wydajności po wyłączeniu HT były prezentowane na konferencji Hot Chips (mój komentarz https://zaufanatrzeciastrona.pl/post/bezpieczenstwo-czy-wydajnosc-jakie-decyzje-podejma-producenci-procesorow/)
w kontekście L1TF wyniki producenta są dostępne tutaj: https://www.intel.com/content/www/us/en/architecture-and-technology/l1tf.html
No wiec niestety praktyczna mozliwosc wykorzystania wzrasta przy wylaczonym HT.