Ujawnienie podatności Meltdown i Spectre wywołało niemałe zamieszanie. Teraz, gdy emocje opadły, pora na wyjaśnienie. O co tam właściwie chodzi? Wyjaśnimy to krok po kroku w specjalnym cyklu artykułów.
Meltdown i Spectre to podatności niezależnie odkryte przez badaczy z Google Project Zero, Cyberus Technology oraz Politechniki w Graz (m. in. Jann Horn i Paul Kocher). Opublikowane artykuły są zwieńczeniem kilku lat żmudnych badań polegających na reverse-engineeringu procesorów. Samo istnienie tego typu podatności nie jest zaskoczeniem dla naukowców zajmujących się architekturą komputerów, prace wykazujące podobne niedopatrzenia w chaotycznym standardzie x86 ukazują się od wielu lat, ale te dwie są przełomowe.
Publikacje, które ukazały się w styczniu zawierały PoCe (ang. Proof of Concept) udowadniające istnienie ataków pozwalających na wykradzenie pamięci innego procesu, a nawet samego kernela. W tej serii artykułów spróbujemy wyjaśnić dosyć skomplikowaną przyczynowość pomiędzy wprowadzeniem optymalizacji, a powstałymi zagrożeniami.
Przetwarzanie potokowe
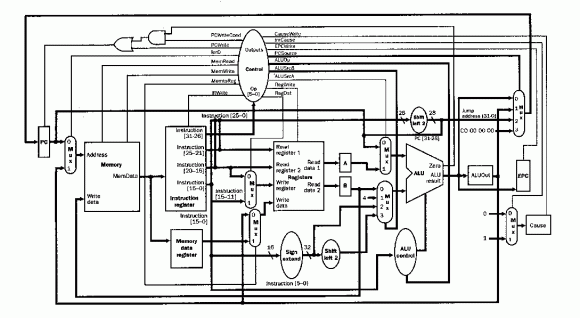
Rozważania warto rozpocząć od pytania: dlaczego w ogóle procesory są optymalizowane i jak wyglądają te optymalizacje? Każdy procesor stanowi skomplikowany układ cyfrowy, który jest zbudowany z pewnych bloków funkcjonalnych.
Przykładowa ścieżka danych w prostym procesorze MIPS. Na rysunku widać zależności pomiędzy blokami takimi jak pamięć, rejestry, jednostka arytmetyczno-logiczna, dekoder etc. Źródło: https://www.cise.ufl.edu/~mssz/CompOrg/CDA-proc.html
Najbardziej oczywistym i zarazem najprostszym podejściem byłoby zaprojektowanie procesora tak, aby instrukcje były wykonywane całkowicie sekwencyjnie. Przykładowo, instrukcję add [eax], ebx można zrealizować w następujący sposób:
- Pobierz instrukcję z pamięci (adres obecnej instrukcji wskazuje rejestr EIP).
- Zdekoduj instrukcję.
- Wczytaj pierwszy argument z pamięci (spod adresu zawartego w eax).
- Wykonaj operację dodawania w jednostce arytmetyczno-logicznej.
- Zapisz wynik do pamięci (pod adres zawarty w eax).
- Przesuń wskaźnik instrukcji na następną instrukcję.
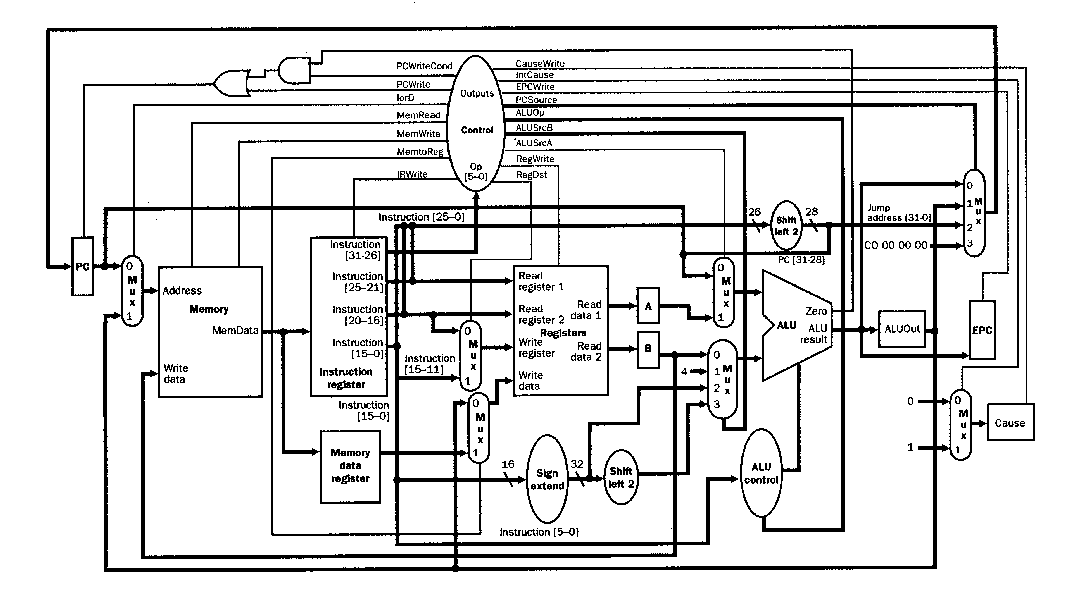
Niestety, takie podejście projektowe umożliwia pracę procesora w częstotliwościach rzędu kilku MHz. Ponadto, niektóre bloki funkcjonalne będą bezczynne przez większość czasu potrzebnego do wykonania instrukcji. Przykładowo, jednostka arytmetyczno-logiczna (ALU) jest potrzebna wyłącznie w kroku #4, podczas wykonywania kroków #1-3 oraz #5 nie będzie miała żadnego zajęcia.
Wykonywanie instrukcji bez potokowości. Źródło: https://www.slideshare.net/nithilgeorge/2010-1002-intro-to-microprocessors1
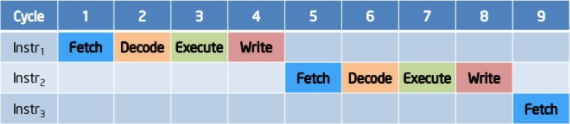
Ponieważ rozważane bloki są fizycznymi układami, powinniśmy przeprojektować procesor tak, aby możliwie zwiększyć ich obciążenie. Tak powstała idea nazywana pipelining, czy też idea „przetwarzania potokowego”.
Potok, który wykonuje instrukcje po kolei, zgodnie z kolejnością zapisania ich w programie. Źródło: https://www.slideshare.net/nithilgeorge/2010-1002-intro-to-microprocessors1
Instrukcje dzielone są na mniejsze etapy, które w miarę możliwości wykonywane są równolegle. Wykonywanie instrukcji w kolejności programu ma swoje minusy. Tak jak widać na powyższym obrazku, w niektórych przypadkach złożone instrukcje mogą zakorkować potok na kilka cykli.
Out-of-order execution
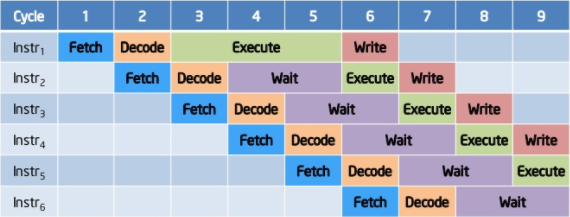
Innym ciekawym aspektem optymalizacji jest wykonywanie poza kolejnością (ang. out-of-order execution). Ustalenie zależności pomiędzy poszczególnymi instrukcjami pozwala na wykonywanie ich w optymalnej kolejności dostępności poszczególnych danych, a nie w arbitralnej kolejności zapisania ich w programie.
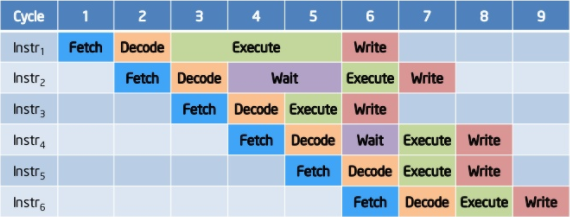
Potok z niekolejnym wykonywaniem. Instrukcje są kolejkowane tak, aby maksymalnie wykorzystać zasoby procesora. Źródło: https://www.slideshare.net/nithilgeorge/2010-1002-intro-to-microprocessors1
Ponadto, niektóre bloki funkcjonalne w nowoczesnych procesorach są zdublowane, więc niektóre instrukcje mogą zostać całkowicie zrównoleglone, o ile jest to bezpieczne dla integralności.
Instrukcje skoku
Najwięcej kłopotu sprawiają jednak instrukcje skoku warunkowego. Pamiętajmy, że zgodnie z powyższym modelem, w momencie kiedy rozpoczyna się dekodowanie instrukcji skoku, musimy już zacząć ładować następną instrukcję. Niestety, na tym etapie nie wykonaliśmy jeszcze instrukcji skoku do końca, więc nie wiemy jaką ścieżką dalej podąży program. Czy warunek był pozytywny i skok wystąpił, czy też warunek okazał się negatywny i skok powinniśmy zignorować?
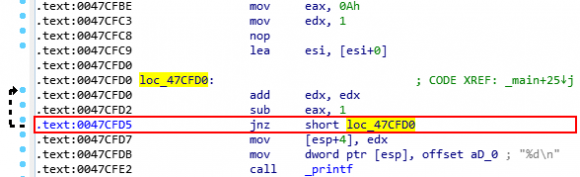
Po załadowaniu instrukcji jnz short loc_47CFD0 musimy natychmiast zacząć ładować następne instrukcje. Nie wiemy jednak, czy będzie to instrukcja pod adresem 0x0047CFD7, czy 0x47CFD0, ponieważ instrukcja skoku zostanie wykonana dopiero kilka cykli później (w momencie kiedy potok całkowicie ją przetworzy).
Branch prediction
Najprostszym rozwiązaniem tego problemu jest zaprzestanie ładowania następnych instrukcji do potoku, tak aby zaczekać na wynik wykonania instrukcji skoku i podjąć właściwą decyzję. Ponownie powracamy jednak do znanego problemu: postępując w ten sposób spowodujemy, że podczas wykonywania każdego skoku większość zasobów procesora będzie marnowana.
Jest jednak sprytniejszy sposób na rozwiązanie tej sytuacji, formalnie nazywany branch prediction. Procesor po napotkaniu instrukcji skoku stara się przewidzieć, jaki będzie wynik jej wykonania. Do tego celu wykorzystuje specjalne heurystyki, które bazują głównie na danych historycznych.
W dużym uproszczeniu: jeżeli niedawno ten kawałek kodu był wykonywany kilka tysięcy razy i w większości przypadków skok wykonał się pozytywnie, to warto obstawiać że również tym razem tak będzie.
Speculative execution
Dzięki tego typu predykcjom procesor po przejściu przez instrukcję skoku może zacząć ładować dalsze instrukcje zgodnie z najbardziej prawdopodobną ścieżką. Ponieważ jednak w nowoczesnych procesorach potok (pipeline) jest znacznie dłuższy niż na prezentowanych tutaj przykładach, wciąż nie jest to wystarczające rozwiązanie.
Idąc za ciosem, producenci procesorów wymyślili jeszcze ciekawszą optymalizację nazywaną speculative execution. Procesor po napotkaniu instrukcji skoku zapisuje swój stan (całkiem analogicznie do np. zapisywania stanu w grze komputerowej), obstawia jaki będzie wynik wykonania tej instrukcji i na tej podstawie ładuje oraz wykonuje następne instrukcje.
Kiedy wykonywanie brancha dojdzie do końca i znany jest wynik, procesor może podjąć decyzję: jeżeli obstawił prawidłowo, to wszystko jest w porządku i może kontynuować pracę bez żadnych opóźnień. Jeżeli jednak spekulacja okaże się błędna, procesor wczytuje zapisany stan, efektywnie cofając się do momentu przejścia przez brancha i ponownie wykonuje ten kawałek programu, tym razem prawidłowo.
Taki sposób działania procesora, sam w sobie nie powoduje jeszcze niczego złego. Nawet jeżeli procesor obstawi błędnie i przez to wykona złe instrukcje, chwilę później „zorientuje się”, że spekulacja była błędna i „naprawi” swój stan. Niektóre instrukcje mają jednak swoje efekty uboczne, których nie można tak łatwo odwrócić. Warto tu podkreślić, że nie chodzi tutaj o takie efekty jak zmiana wartości w pamięci, czy zapisanie pliku na dysku. Procesor nie zleca takich operacji, dopóki nie upewni się, że wykonana instrukcja była prawidłowa. Nieprawidłowe spekulacje pozostawiają jednak efekty uboczne wewnątrz samego procesora, np. w stanie pamięci podręcznej.
Biorąc pod uwagę, że spekulacje zaprojektowane są tak, aby większość z nich wykonała się pozytywnie, ich wpływ na zwiększanie wydajności procesora jest niezwykle istotny. W nowoczesnych procesorach pojedyncze okno spekulacji zawiera nie kilka, lecz nawet kilkadziesiąt instrukcji. Takie zrównoleglenie wiąże się jednak z istotnymi problemami po stronie bezpieczeństwa, ale do tego wrócimy niebawem.
Podsumowanie
Pierwsza część artykułu przybliżyła podstawowe techniki optymalizacji nowoczesnych procesorów. Prawidłowe zrozumienie podstawowych zasad budowy CPU wykorzystujących potokowość jest kluczowe, aby później prawidłowo zinterpretować ataki Meltdown i Spectre. Następna część artykułu poruszy tematykę bocznych kanałów oraz omówi ten, który jest stosowany w obu wspomnianych atakach.



Komentarze
Fajnie się czyta, ale moim zdaniem artykuł mógłby być dłuższy.
Będą kolejne części.
W sam raz na raz, inaczej dodałbym do zakładek i nigdy nie przeczytał
„Linia produkcyjna” to po naszemu „potok” :) https://pl.wikipedia.org/wiki/Potokowo%C5%9B%C4%87
Eh, zawsze mnie pokonuje polska terminologia ;) Od teraz wszędzie będzie „potok”. Dzięki za czujność.
To jeszcze uczepię się słowa „branch”: czy nie lepiej pisać i mówić „wykonywanie rozgałęzienia”?
No można, tylko porównaj długość tych słów ;)
Myślę, że stosowanie określeń 'skok’ i 'skok warunkowy’ będzie wystarczające, nawet jeśli nie są do końca tożsame. W końcu 'branch’ jest realizowany za pomocą skoków właśnie.
Also: w zależności od architektury, instrukcje skoków są różnie nazywane; w ARM-ach są to branche, w Intelach – jumpy. Np. instrukcja skoku warunkowego, jeśli porównywane liczby są równe/wartość jest różna od zera:
– ARM: BNE (Branch Non Equal)
– Intel: JNZ (Jump Non Zero)
Nikt jeszcze nie wyjaśnił tego zjawiska w sposób zrozumiały, ale widzę, że wreszcie coś z tego zrozumiem. Dzięki, czekam na kolejne :)
Napisz całość i opublikuj jako jeden art. Dzielenie na krótkie fragmenty, w których duża część treści to powtórzenie faktów już wielokrotnie opisanych w innych miejscach sieci to IMHO lekka przesada.
Taki format bloga. Nie jestem pewien ile osób wytrwałoby do końca, gdyby na raz otrzymali artykuł „cegłę”, który aż przywiesza przeglądarkę ;) Pierwsza część jest wprowadzeniem, stąd sporo nie-unikalnej treści. Od części drugiej robi się znacznie ciekawiej.
Dobry artykuł, jest sporo smaczków technicznych :)
Czekam na dalsze części!
To samo w formie prezentacji
https://youtu.be/FBy2gZD3OUw
Spoko fajne bajeczki. Odkąd poszła bajeczka o tych spowalniaczach procesorów ja nie zauważyłem by jakkolwiek zwolnił mój laptop. Mam mobilną wersję procesora Intel i7 Haswell oraz 24GB RAM i naprawdę nie widzę różnicy przed medialną falą ściemy marketingowej o tym całym Meltdown i Spectre a teraz. To po prostu stek bzdur marketigowych zachęcający konsumentów do wydawania pieniędzy na nowszy sprzęt pozornie zabezpieczony przed tym wyimaginowanym zagrożeniem. Czysty marketing wymyslony przez inteligencję dla głupiego plebsu.
@neo86 … „ignorance is a bliss”
Niektórzy operatorzy chmurowi mieli bardzo duży problem, bo po zastosowaniu łatek faktycznie przestało wystarczać procesora na wszystkie maszyny wirtualne. Spowolnienie zależy od profilu obciążenia na danym serwerze, a patche faktycznie mają prawo spowalniać procesory. Techniczne wyjaśnienie dlaczego się to dzieje będzie w następnych częściach ;)
A gówno… Nie ma na na rynku procesorów, które sprzętowo rozwiązują te problemy. I jeszcze chwilę nie będzie bo procesora się nie projektuje w 6 miesięcy. Nawet następna linia Intela będzie podatna (co ten potwierdził) jedynie zmiany w mikrokodzie będą przetestowane pod kątem zmniejszenia prawdopodobieństwa udanego ataku.
Masz rację. Łaty na spectre i meltdown nie mają wpływu na wydajność wyświetlania tapety na pulpicie w Łindołs. Co do tego co napisałeś o marketingu świadczy, że masz poważne problemy z logicznym myśleniem – otóż opisywane podatności kładą się ogromnym cieniem na Intela i inne firmy i nie ma tutaj mowy o jakiejś promocji czy zachęcie do zakupu nowszego sprzętu. Duże firmy i ludzie z branży zastanawiają się teraz ile jeszcze podobnych bugów jest w prockach i jak się to odbije na ich biznesie.
Może i spectre i meltdown istnieją ale nic nie robią z komputerami. To bujda internetowa i marketingowa by przestraszyć naiwnych. I nie używam Windowsa. Tylko Linuksa Debiana (raz na miesiąc go aktualizuję). Żadnych łat nie instalowałem (bo po co) i żadnej zmiany w zachowaniu laptopa nie widzę. Używam go nadal do zastosowań multimedialnych. Czyli obróbka filmów i zdjęć. Temperatura procesora nie przekracza +38/+40 stopni przy obróbce w 4K h.265. Zatem ja bajeczki o spowalnianiu sprzętu przez spectre i meltdown wkładam między historie o mitycznym wirusie na linuksa który podobno istnieje ale jakoś odkąd od 2002 roku używam linuksa jako głównego systemu nigdy nie trafiłem. Chodzi mi o takiego wirusa który by narobił szkód w systemie i w plikach BEZ potrzeby używania atrybutów „root”. I tyle na temat.
Meltdown i Spectre są exploitami read-only, za ich pomocą można jedynie wykraść dane. Oczywiście jeżeli atakującemu uda się ukraść jakieś istotne informacje, możliwe jest przejęcie kontroli nad systemem. Niewykluczone że takie specjalizowane ataki już istnieją.
„Spowolnienie” wynika z charakterystyki łatek, które wyłączają pewne optymalizacje, aby uniemożliwić atak. Zostanie to wyjaśnione dokładnie w dalszej części cyklu artykułów.
Szkoda mi oczu na te bajki. Jak to mówi powiedzenie „Bujaj las a nie Nas…”
Istnienie exploitów zostało udowodnione w sposób naukowy i jest weryfikowalne.
Dobry troll, daję 8/8.
Troll to są serwisy takie jak ten oraz Niebezpiecznik powielające te głupoty marketingowe kuszące do kupna nowego procesora lub całego komputera.
W końcu ludzkim językiem! Dzięki
A co gdyby wykorzystać `rdtsc` do spekulacji ile czasu wykonywał się program w innym wątku na tym samym rdzeniu?
Artykuły pisze Wam Anglik ze znajomością polskiego, czy odwrotnie?
'Kiedy wykonywanie brancha’
Kicha rycha z takim pisaniem.
Easy, każdy wie że angielski jest must-have językiem dla developerów, więc większośc paperów, talków i dev-logów jest pisana właśnie w tym języku. Sporo słów, jak np. branch, nawet nie ma dobrych polskich translacji!
> Sporo słów, jak np. branch, nawet nie ma dobrych polskich translacji!
Zgoda, ale na pewno mamy w języku polskim np. słowo „tłumaczenie” zamiast „translacja” czy słowo „konieczność” zamiast „must-have”.
Używanie obcej terminologii (np. „branch” czy „pendrive”) do zagadnień technicznych nie musi oznaczać kaleczenia języka.
„Niestety, takie podejście projektowe umożliwia pracę procesora w częstotliwościach rzędu kilku MHz”
Yyy.. że co??? :P