To pierwszy z czterech artykułów opisujący ciekawy i rzadko tak dogłębnie badany świat osób dokonujących płatności za pomocą wykradzionych danych kart płatniczych. W świat ten wprowadzi was ekspert Marcin Mostek.
Uwaga! Poniższy artykuł ma charakter popularno-naukowy, a nie analityczno-techniczny, toteż autor stanowczo odżegnuje się od zwykle stosowanej formy trzecioosobowej i poważnego, profesjonalnego tonu wypowiedzi. Oczywiście twórca mógłby popuścić wodze swojej fantazji i zasypać czytelnika najdrobniejszymi szczegółami technicznymi, jednak w jego odczuciu zniechęciłoby (a raczej zanudziłoby) to dużą część audytorium. W artykule mogą znajdować się śladowe ilości kodu JavaScript, jednak w trosce o zdrowie psychiczne czytelnika, zostaną one ograniczone do niezbędnego minimum.

Ekosystem antyfingerprintowy
Jedną z ciekawszych, a jednocześnie mniej znanych usług dostępnych w tak zwanym „dark necie” (tfu, co za nazwa! brakuje jeszcze tylko przedrostka „cyber”) jest handel narzędziami utrudniającymi fingerprintowanie. By opisać to zjawisko, należy na początku wyjaśnić, czym właściwe jest fingerprinting.
Kiedyś to było, czyli krótki rys historyczny
Dobre wyjaśnienie istoty fingerpintingu wymaga od autora przytoczenia pewnego uproszczonego kontekstu historyczno-technicznego dotyczącego internetu, sposobu działania stron WWW i przeglądarek internetowych.
W swojej pierwotnej idei strony WWW miały być skarbnicą całej wiedzy zgromadzonej przez ludzkość – odpowiednikiem starożytnej Biblioteki Aleksandryjskiej. By skutecznie poruszać się w takim mrowiu informacji, potrzebna jest dobrze zdefiniowana struktura. Stanowić ją miały dokumenty zawierające uporządkowane informacje wraz z metadanymi (np. autorem, czasem dodania, typem dokumentu – tekst, mapa itp.). Struktura tego typu miała znacząco uprościć wyszukiwanie potrzebnych informacji. Dodatkowo, projektując cały system, starano się odwzorować w nim sposób, w jaki ludzie przetwarzają i uczą się nowych informacji. By pokazać relacje pomiędzy poszczególnymi dokumentami, posłużono się hiperlinkami – odpowiednikami ludzkich skojarzeń. Do przeglądania dokumentów, informacji i relacji pomiędzy nimi miały służyć specjalne przeglądarki.
Jednak życie życiem, a idea ideą – ludzie posługujący się językiem „programowania” (znanym dzisiaj jako HTML) zaczęli używać go wbrew zamierzeniom pomysłodawców tej koncepcji. HTML był wykorzystywany już nie do opisywania zawartości dokumentów, ale jako forma modyfikacji ich wyglądu. Następnie historia potoczyła się błyskawicznie – firma Netscape wprowadziła LiveScript (znany dzisiaj pod nazwą JavaScript), umożliwiając budowanie interaktywnych interfejsów użytkownika na stronach WWW. Kolejnym krokiem milowym było wprowadzenie przez Microsoft API XMLHttpRequest, które umożliwiło komunikację z serwerem bez przeładowywania strony. Krok ten pozwolił de facto na budowanie złożonych aplikacji / interfejsów użytkownika bezpośrednio w przeglądarce (webaplikacje).
Jednakowoż technologie wykorzystywane u podstaw tych wszystkich zmian nie były projektowane z myślą o tak złożonych systemach. Rodziło to liczne problemy. Jednym z nich była bezstanowość protokołu wykorzystywanego do przesyłania stron WWW – HTTP. Protokół ten nie był w stanie zachować żadnych informacji o poprzednich transakcjach z klientem (po zakończeniu transakcji wszystko „przepada”). Mając złożoną aplikację internetową, chcemy przecież zapamiętać ustawienia użytkownika czy potwierdzić jego tożsamość pomiędzy wejściami na stronę. By tego dokonać, musimy zapisać jakąś informację w przeglądarce użytkownika. Mechanizm, który został wprowadzony właśnie w tym celu to HTTP cookie. Jest to po prostu mały fragment tekstu, który serwis internetowy wysyła do przeglądarki i który przeglądarka wysyła z powrotem przy następnych wejściach na witrynę.
Ten prosty trik pozwala na identyfikację użytkownika. Lecz co w wypadku, gdy złośliwy użytkownik usunie tę informację z przeglądarki? Oczywiście istnieją bardziej karkołomne metody zapisywania danych identyfikacyjnych (np. Evercookie), ale je także można usunąć. W tym momencie na ratunek zjawia się właśnie fingerprinting!
Fingerprint – co to za zwierz?
Fingerprint to charakterystyczny dla danego użytkownika zestaw danych pobranych z przeglądarki, mogących z dużym prawdopodobieństwem potwierdzić jego tożsamość pomiędzy wejściami na daną stronę internetową.
Opisując to bardziej obrazowo:
Odpowiednikiem pliku cookie (czyli zapisania informacji w przeglądarce) w świecie rzeczywistym byłyby tablice rejestracyjne auta. Odpowiednikiem fingerprintu opis słowno-muzyczny: „czerwony volkswagen passat z urwanym lusterkiem, zielonym spojlerem i koralikami na fotelach”.
Fingerprint – a komu to potrzebne? A dlaczego?
Fingerprint jest nagminnie stosowany w antyfraudowych systemach płatniczych typu card not present (czyli wszystkich tych, w których płacimy kartą w internecie). Czy zastanawiało Cię, drogi czytelniku, skąd to kręcące się kółko po dokonaniu płatności kartą? Fingerprintowanie użytkownika jest jednym z powodów tego popularnego zjawiska (oprócz wysyłania danych do samego systemu płatności i mnóstwa innych operacji dziejących się w tym czasie).
Wbrew pozorom systemom tego typu nie zależy na permanentnej inwigilacji użytkowników internetu ani dowiedzeniu się, kim naprawdę są, a na zablokowaniu tylko tych z nich, którzy próbują dokonać płatności kradzionymi kartami. Częstym manewrem stosowanym przez carderów jest testowanie, które karty z nabytej przez nich paczki / wycieku nie są już zablokowane i tym samym zdatne do dalszego popełniania przestępstw. Zwykle szuka się do tego celu słabiej zabezpieczonej strony, która oferuje możliwość płatności kartą lub założenia subskrypcji (również opartej na karcie).
W pierwszym przypadku bardzo popularne bywają strony charytatywne, które umożliwiają przekazanie dowolnej wielkości datku. Mała kwota zwiększa szansę, że prawowity właściciel karty nie zauważy faktu nieautoryzowanej płatności i nie zgłosi kradzieży do odpowiedniego organu, blokując tym samym kartę.
Dla zrozumienia drugiego przypadku trzeba zagłębić się w sposób, w jaki procesowane są płatności kartowe w modelu subskrypcyjnym. W bardzo dużym uproszczeniu działa to następująco:
- Użytkownikowi proponowany jest okres próbny usługi, w którym nic nie płaci (zwykle miesiąc), jednak musi podać dane karty w celu cyklicznego naliczania opłat w przyszłości.
- Po stronie usługodawcy i banku następuje operacja tak zwanej autoryzacji, czyli stwierdzenia, czy dana karta jest aktywna i czy zawiera jakiekolwiek pieniądze. Operacja ta praktycznie realizowana jest poprzez pobranie ze środków przypisanych do karty symbolicznej kwoty, np. 1 dolara). Kwota ta jest zwracana później na konto; opóźnienie, z jakim tam trafia, wynika z charakterystyki płatności kartowych. Jeśli operacja autoryzacji udała się, użytkownik zyskuje od razu dostęp do usługi.
- Po zakończeniu okresu próbnego z konta użytkownika przypisanego do karty cyklicznie zaczynają być pobierane pieniądze.
Jako że w przypadku poprawnej autoryzacji praktycznie od razu można uzyskać dostęp do usługi, pozwala to na natychmiastowe potwierdzenie, że dana karta nie została jeszcze zablokowana.
Oczywiście w większości tego typu przypadków carderzy nie bawią się w detal i sprawdzają kilka lub kilkadziesiąt kart. Działania tego typu są oczywiście maskowane, czy to przez usunięcie cookies, czy bardziej wyrafinowane metody. Operacja carderów może być bardzo bolesna dla właściciela serwisu, w którym takie „badanie” miało miejsce. To właśnie on zostanie pociągnięty do odpowiedzialności – czy przez kary pieniężne narzucone mu przez dostawcę systemu płatności, czy też w ekstremalnych wypadkach przez odłączenie od sieci płatniczej.
Do czego mogą posłużyć tego typu sprawdzone karty? To już zależy od doświadczenia i inwencji danego przestępcy. Może to być wypranie pieniędzy w dużo lepiej zabezpieczonych serwisach, w których można kupić na przykład dobra luksusowe i elektronikę (im drożej, tym lepiej) czy bilety lotnicze. Ale sposoby działania carderów to temat na zupełnie inny artykuł…
Oczywiście samo fingerprintowanie nie jest jedynym sposobem powstrzymywania wyżej opisanych ataków, a raczej jednym z wielu elementów systemów antyfraudowych. Obowiązuje tutaj powszechnie znana w systemach bezpieczeństwa zasada ochrony w głąb (bądź jak nazywały to nasze babcie – „na cebulkę”).
Jak się tworzy fingerprinty?
Dobrze, to skoro już mniej więcej wiemy, czym jest fingerprint, to w jaki sposób się go tworzy?
Na początku trzeba wytypować technologie / pola z informacjami, które mogą:
- dotyczyć rzeczy, które użytkownik może skonfigurować / zainstalować w systemie lub przeglądarce
LUB
- przechodzić przez wiele warstw systemu, z których każda modyfikuje dane wyjściowe.
O ile pierwsza część wydaje się dosyć intuicyjna (np. zebranie pluginów czy czcionek z przeglądarki powinno załatwić sprawę), to o co chodzi autorowi z drugą opcją?
Przykładem drugiego podejścia do fingerprintingu może być wyrenderowanie w przeglądarce obrazka z użyciem WebGL-a (technologii odpowiedzialnej za renderowanie grafiki 3D w przeglądarkach). W przypadku gdy dynamicznie tworzymy w przeglądarce każdego użytkownika identyczny obrazek, przechodzimy przez następujące warstwy:
- przeglądarka, a raczej jak przeglądarka zaimplementowała WebGL,
- konkretna wersja sterownika karty graficznej i meandry jego implementacji (w sterownikach jest masa „dedykowanych rozwiązań”),
- różnice w implementacji funkcji systemowych w różnych systemach operacyjnych,
- różnice w dokładności obliczeń zmienno-przecinkowych (spróbujcie sobie policzyć cosinusa z tej samej wartości w JS na różnych przeglądarkach i systemach),
- sama karta graficzna.
Każda z wyżej wymienionych warstw wpływa na końcowy kształt obrazka. Powoduje to, że ten sam obraz wyrenderowany na dwóch różnych komputerach wygląda niemal identycznie, ale w praktyce nie jest dokładnie taki sam (różnica kilku pikseli). To właśnie ten szczegół umożliwia identyfikację bądź rozróżnienie użytkowników.
Nie ma róży bez ognia, czyli o wadach fingerprintingu
Jak każda technologia, fingerprinting nie jest doskonały i posiada swoje wady. Każdy istniejący fingerprint znajduje się gdzieś na następującej skali:
Stabilność <—————————————> Granularność
gdzie stabilność oznacza, jak długo dany fingerprint działa (jak długo jest w stanie identyfikować danego użytkownika, zanim ulegnie zmianie), a granularność – jak wielu różnych użytkowników może posiadać ten sam fingerprint (im mniej, tym lepiej).
Niestety (albo i stety – zależy, z której perspektywy patrzeć) wartości te w zdecydowanej większości przypadków wykluczają się nawzajem. Bardzo granularny fingerprint będzie działał naprawdę krótko, natomiast niezwykle stabilny fingerprint będzie miał te same wartości dla różnych użytkowników. Quid pro quo – jak mawiali starożytni Rzymianie.
Przykładowo:
Jeśli do fingerprintowania użyjemy adresu IP użytkownika, fingerprint ten zyska na granularności, aczkolwiek czas jego działa będzie bardzo krótki. Złośliwy carder zmieni swój adres IP w ciągu kilku godzin lub dni.
Natomiast jeśli do fingerprintingu użyjemy samych informacji o technologiach, które są wspierane przez przeglądarkę, fingerprint będzie bardzo stabilny w czasie, ale jego wartość będzie taka sama dla wszystkich użytkowników z tą samą przeglądarką.
Ciekawostka mostka
Twórcom przeglądarek można często pogratulować precyzji i ułańskiej fantazji. Przykładem obu tych cech jest API określające stopień wsparcia odtwarzania danego formatu dźwięku, np.:
new Audio().canPlayType(’audio/mp3′)
Może zwrócić nam wartości: probably, maybe i no. Cokolwiek to oznacza…
Oczywiście wraz ze wzrostem wolumenu ruchu zwiększa się szansa na to, że nawet granularny fingerprint będzie miał tę samą wartość dla różnych użytkowników. Fakt ten, a także inne właściwości fingerprintu (granularność vs stabilność) są w zasadzie pomijane nawet w publikacjach naukowych. Spowodowane jest to zbyt małą skalą badań – wyniki wieszczące koniec prywatności, internetu i świata, jaki znamy, są zwykle oparte na próbie 100-2000 osób. W takiej skali nie da się praktycznie zauważyć powyższych zjawisk.
Część z proponowanych w rozważaniach akademickich sposobów fingerprintowania użytkownika nie nadaje się do zastosowań produkcyjnych. Przykładowo, dokładne zmierzenie wydajności urządzenia wymaga zwykle od użytkownika zbyt długiego, kilkunastosekundowego przebywania na stronie. Trzeba jednak przyznać tworzącym tego typu badania, że wykazują się niemałą pomysłowością i kreatywnością w doborze technologii, które mogą posłużyć do stworzenia fingerprintu.
Co zrobić, by Ameryka była znów wielka, Polska była najważniejsza, a ten kraj był nasz i wasz?
W świecie rzeczywistym, to znaczy takim, w którym użytkownik wraz z przeglądarką nie porusza się ruchem jednostajnie przyśpieszonym w próżni, problem spadku granularności wraz ze wzrostem ilości ruchu rozwiązuje się, łącząc wiele typów fingerprintów. Naturalnie, im więcej fingerprintów użyjemy, tym bardziej obniżymy stabilność – określenie złotego środka jest nietrywialnym problemem optymalizacyjnym. Należy przy tym pamiętać, że znalezienie takiego optimum nie jest stałe w czasie.
Na przykład:
Jeśli w naszym fingerprincie mocno polegamy na obecności czcionek w systemie, to wraz z dużą zmianą geograficznego źródła ruchu (np. z USA na Chiny), może się okazać, że większość wytypowanych przez nas fontów jednak jakimś cudem nie spopularyzowała się wśród mieszkańców Państwa Środka. Doprowadzi to do zmniejszenia ilości bitów informacji, które możemy odczytać, a więc i granularności samego rozróżnienia użytkowników.
(Fingerprint oparty na czcionkach wymaga z góry ustalonej ich listy, którą chcemy sprawdzić, patrz też dalsza część artykułu.)
To jest fingerprint na miarę naszych możliwości, czyli przykłady
User-Agent
Najprostszą rzeczą zdatną do fingerprintingu jest User-Agent, czyli to, w jaki sposób przeglądarka przedstawia się serwerowi, z którym nawiązuje połączenie. Wartość tę można uzyskać niezależnie z dwóch miejsc:
- nagłówków wysyłanych przy żądaniu HTTP
LUB
- korzystając z javascriptowego API window.navigator.userAgent.
Nie jest to jednak zbyt dobre pole do wykorzystania w celu rozróżnienia lub identyfikacji użytkownika, gdyż można je w łatwy sposób podmienić w przeglądarce lub poza nią.
Przykładowy User-Agent (Chrome na Windows 7) wygląda w następujący sposób:
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36Zaraz, zaraz – skoro jest to Chrome, skąd tu Mozilla, Apple, Gecko i Safari? Zwykle odpowiedź jest jedna – jeśli w świecie przeglądarek nie wiadomo, o co chodzi, to chodzi o kompatybilność wsteczną (no i pieniądze). No i tu zaczyna się zabawa…
Jedną z pierwszych przeglądarek był Mosaic, który przedstawiał się w następujący sposób:
Mosaic/0.9Proste, prawda? Ale w życiu, jak to w życiu, nic nie pozostaje zbyt długo proste. Następną większą nowością na rynku był produkt firmy Netscape Communications o znajomo brzmiącej nazwie kodowej Mozilla (notabene od połączenia słów Mozaic Killa). Oczywiście Mosaic nie był zachwycony takim wyborem, więc oficjalną nazwę zmieniono na Netscape. Niemniej jednak złośliwi programiści pozostawili codename w User-Agencie:
Mozilla/2.02 [fr] (WinNT; I)Jak widać, dodano informacje o języku, platformie i sposobie szyfrowania (I oznacza w tym wypadku szyfrowanie 40-bitowe).
Następną większą przeglądarką, jaka pojawiła się na rynku, był uwielbiany w kręgach programistów JavaScriptu Internet Explorer. Przeglądarka ta nie obsługiwała niektórych technologii wspieranych przez konkurencję, toteż właściciele serwisów WWW zaczęli filtrować odwiedzających strony w zależności od User-Agenta. W przypadku IE serwowali inną wersję serwisu bądź nie serwowali jej w ogóle. Fakt ten nie przysparzał raczej popularności nowej przeglądarce, toteż cwany Microsoft wpadł na pomysł, by udawać User-Agentem rozwiązania konkurencji (większość sprawdzeń analizowała tylko pierwszy człon UA):
Mozilla/2.0 (compatible; MSIE 3.02; Windows 95)Trend udawania przeglądarki powtarzał się aż do dzisiejszych czasów, więc User-Agent Chrome’a należy rozumieć w następujący sposób:
- Chrome używał silnika renderującego Webkit (człon AppleWebKit/537.36),
- który został wymyślony przez Apple w Safari i w sumie działał jak w Safari (człon Safari/537.36),
- Webkit z kolei udawał KHTML, który był użyty w Linuksowym Konquerorze (człon KHTML),
- KHTML udawał Gecko – silnik renderujący Firefoksa (człon KHTML, like Gecko),
- a że wszystkie przeglądarki udawały Mozillę, nie mogło zabraknąć i tego członu (Mozilla/5.0 ).
Ciekawostka mostka
Dokładniejszy opis tych zawiłości (które są niezmiernie ciekawe do momentu implementacji parsera) czytelnik może znaleźć tu i tu, a także w coraz bardziej starzejącej się książce „Splątana sieć”, którą autor niezmiernie poleca.
Przykład Chrome’a jest naturalnie dopiero początkiem wspaniałej przygody w świecie User-Agentów, gdyż w międzyczasie:
- dodano typ urządzenia (tablet, komórka itp.),
- niektóre firmy stosują własny schemat nazewnictwa, do którego później same się nie stosują,
- niektóre urządzenia WAP wystawiają X-WAP profile z właściwościami urządzenia,
- starsze wersje IE wystawiają informacje o wspieranych wersjach net-frameworka,
- schemat User-Agenta nie jest spójny pomiędzy producentami (prym wiodą tu konsole do gier czy telewizory),
- w najbliższym czasie autor jest w stanie sobie wyobrazić zalew U-A z żarówek, lodówek, pralek, suszarek i innego Internet of Things (choć z tą rewolucją jest jak z niższymi podatkami – co roku słychać zapowiedzi, ale jeszcze nigdy się nic nie zdarzyło).
Jak widać, mamy tu stosunkowo wiele bitów informacji.
Pluginy
Kolejną właściwością przeglądarki, która może posłużyć do fingerprintowania, są pluginy (nie mylić z rozszerzeniami). Pluginy (jak sama nazwa wskazuje) służą do rozbudowywania przeglądarki o nowe niedostępne wcześniej funkcje. Przykładem może być tutaj bardzo popularny swego czasu Flash czy Java. Okazuje się, że liczba wtyczek jest stosunkowo duża, więc ich lista może pozwolić na identyfikację użytkownika.
Pluginy można wydobyć za pomocą poniższego kodu:
var detectedPlugins = [];
var pluginsLength = navigator.plugins[0].length;
for(var i=0; i < pluginsLength; i++){
detectedPlugins.push(navigator.plugins[0][i]);
}Zwracane informacje mogą zawierać nazwę pluginu, jego opis, nazwę pliku powiązaną z pluginem i jego wersję.
Co ciekawe, w przypadku Internet Explorera proces ten wygląda troszeczkę inaczej – przeglądarka wymaga od użytkownika nazwy pluginu i dopiero po jej podaniu zwraca informacje, czy plugin jest zainstalowany:
var plugins = [];
var names = [
'AcroPDF.PDF',
'WMPlayer.OCX'
// tu należy wstawić więcej nazw pluginów
];
for (var i = 0; i < names.length; i++) {
try {
// sprawdź czy plugin jest dostępny za pomocą odwołania ActiveX
new window.ActiveXObject(names[i])
// jeśli nie nastąpił wyjątek plugin jest obecny
plugins.push(names[i])
} catch (e) {
// jeśli nie ma pluginu obsłuż wyjątek
}
}Właściwości ekranu
Następnym ciekawym API przydatnym w próbach identyfikacji użytkownika jest window.screen. Jest ono silnie skorelowane z typem urządzenia, które wykorzystuje użytkownik (inną rozdzielczość będzie miał laptop, a inną telefon komórkowy). Co więcej, API to może nieść informację o tym, jakiego systemu operacyjnego używa użytkownik – dostępne są w nim właściwości mówiące o całkowitej wysokości / szerokości ekranu urządzenia, a także wysokości / szerokości faktycznie dostępnej dla przeglądarki. Na podstawie różnicy tych danych można stwierdzić, jaką część ekranu pokrywają paski menu w najpopularniejszych systemach operacyjnych. Więcej o tym API można znaleźć tu.
WebGL
WebGL jest próbą umożliwienia webdeweloperom renderowania obrazów 3D w przeglądarce z użyciem karty graficznej. W swoim założeniu miał być jak najbardziej podobny do wykorzystywanego w klasycznych desktopowych zastosowaniach OpenGL-a (bazuje na OpenGL ES 2.0). Jednak, oprócz renderowania demoscenowych perełek pokroju tej czy tej, technologia ta może służyć do innych celów. Jak łatwo można się domyślić wprawionemu już w tej kwestii czytelnikowi, można jej użyć do fingerprintowania.
Pierwszym ze sposobów jest bazowanie na właściwościach udostępnianych przez API, np. maksymalnej obsługiwanej wielkości tekstury (MAX_TEXTURE_SIZE). Takich właściwości jest bardzo dużo i większość z nich powiązana jest z kartą graficzną bądź wersją sterowników do niej (a więc rzeczami, które nie zmieniają się dosyć szybko). Mają one pozwolić deweloperowi na zdecydowanie, czy urządzenie, które otwiera daną stronę z grafiką 3D, ma wystarczającą moc obliczeniową, by wyświetlić grafikę, czy należy np. pogorszyć parametry wyświetlanego obrazu.
Więcej właściwości można znaleźć na tej stronie (tylko część z nich nadaje się do fingerprintowania, reszta to zwykłe stałe). Należy przy tym pamiętać, że WebGL jest dosyć kapryśną technologią i potrafi się „wykrzaczyć” w losowych momentach (np. przez niedostateczną ilość wolnej pamięci graficznej). Możliwe są również sytuacje, w których przeglądarka uzna, że warto przełączyć się na tryb software’owy, zmieniając tym samym wszystkie widoczne właściwości WebGL (np. z powodu problemów ze sterownikiem).
Drugim, bardziej zaawansowanym sposobem jest dynamiczne stworzenie obrazka za pomocą kodu i nałożenie na niego różnych transformat (np. obrócenia obrazu lub dodania cieniowania itp.). Z powodu różnic opisanych we wcześniejszej części artykułu istnieje duża szansa, że dwóch różnych użytkowników nie będzie miało wyrenderowanego takiego samego obrazka, co pozwoli na ich rozróżnienie.
Przykład takiego podejścia wraz z kodem można obserwować pod tym adresem.
Ciekawostka mostka
WebGL może zostać wykorzystany również do innych, bardziej egzotycznych ataków, np. Rowhammer (marketingowa nazwa na klasę ataków potencjalnie pozwalających na odczytywanie, a nawet modyfikację pamięci innego procesu przez przeglądarkę). Więcej na ten temat można znaleźć na tej stronie.
Czcionki
Bardzo popularnym wektorem fingerprintowania użytkowników są czcionki zainstalowane w systemie. Można się do nich dostać na przynajmniej dwa sposoby.
Prostszym z nich jest umieszczenie na stronie aplikacji Flash, która po prostu posiada odpowiednie API umożliwiające sczytanie listy czcionek dostępnych w systemie. Ta metoda powoli odchodzi w niepamięć z powodu wycofywania się głównych przeglądarek z wsparcia Flasha (domyślnie bywa on wyłączony bądź nawet nie jest instalowany) i powolnego zastępowania go przez HTML5.
Druga metoda jest znacznie bardziej sprytna – w przypadku przeglądarek istnieje byt, który można nazwać w uproszczeniu czcionkami bazowymi. Są to typy czcionek, które znajdziemy w przeglądarce niezależnie od producenta, wersji czy systemu operacyjnego (np. serif, sans-serif i monospace). Konkretne czcionki stojące za danym typem różnią się w zależności od systemu operacyjnego, np. domyślną czcionką serif w przypadku Firefoksa będzie zwykle:
- Windows – Times New Roman,
- Mac OS X – Times,
- Linux – serif.
Dobrze, ale co nam po tym fakcie? – zapyta skonfundowany czytelnik.
Otóż w przeglądarkach zaimplementowano mechanizm fallbacku, na wypadek gdyby zbyt awangardowy designer wybrał tak elitarną i hipsterską czcionkę, którą posiada w systemie tylko on sam i Salvador Dali. Wygląda to mniej więcej w taki sposób:
font-family: Lato, Sans-Serif;I znaczy dla przeglądarki tyle co: wyświetl ten tekst za pomocą czcionki „Lato”, a jeśli jej nie będzie, użyj czcionki oznaczonej przez system jako wartość domyślną sans-serif. Gdzie w tym enumeracja? Ano można:
- wybrać długi i charakterystyczny ciąg znaków,
- kazać przeglądarce go wyrenderować w pierwszej kolejności dla wybranego fallbacku, np. sans-serif,
- zmierzyć długość wyrenderowanego ciągu znaków,
- wybrać czcionkę, którą chcemy przetestować pod względem obecności w systemie,
- wyrenderować wybraną czcionkę z fallbackiem,
- zmierzyć szerokość otrzymanego wyniku.
Jeśli szerokość jest taka sam jak fallbackowej czcionki, mamy pecha – nie ma jej w systemie (wyrenderował się wybrany przez nas wcześniej sans-serif). W przeciwnym wypadku czcionka znajduje się w systemie (wartość szerokości inna niż fallback).
Takie podejście ma sporo nieoczywistych pułapek, np.:
- musimy mieć wcześniej przygotowaną listę czcionek,
- lista może zmieniać swoją skuteczność fingerprintowania ze względu na kraj pochodzeniu ruchu (np. w przypadku krajów arabskich powinna być inna niż europejskich),
- do powyższej listy nie możemy dorzucać wpisów na zasadzie „ile fabryka dała” – nagłe wczytywanie z dysku miliona czcionek zablokuje użytkownikowi przeglądarkę,
- z drugiej strony, przeglądarki nie byłyby sobą, gdyby każda z nich wyświetliła ten sam element w identyczny sposób, toteż zebranie szerokości daje nowe możliwości fingerprintingu (różnice wynikają z silników renderujący przeglądarek, a także właściwości związanych z kartą graficzną i systemem).
WebRTC
Technologia ta służy głównie do hole punchingu, czyli nawiązywania bezpośredniego połączenia pomiędzy dwoma końcówkami (w tym wypadku dwiema przeglądarkami). Rozwiązanie tego typu przydaje się głównie w przypadku komunikacji głosowej i wideo-głosowej, w której każde opóźnienie gwałtownie obniża jakość usługi. W bardzo dużym uproszczeniu usługa ta działa w następujący sposób:
- Pojawiają się dwie przeglądarki, które chcą nawiązać ze sobą połączenie.
- Obie przeglądarki nie wiedzą nic o sobie ani nie mają odpowiednich informacji sieciowych potrzebnych do nawiązania połączenia bezpośredniego. Mają za to informację o wspólnym serwerze STUN i serwerze sygnałowym.
- Przeglądarki łączą się z serwerem STUN, uzyskując informacje o zewnętrznym adresie sieciowym.
- Przeglądarki łączą się z serwerem sygnałowym i wymieniają niezbędne metadane do nawiązania bezpośredniego połączenia.
Okazuje się, że negocjacja połączenia (ICE na rysunku) działa w kilku trybach. Niektóre tryby gwarantują lepszą wydajność połączenia kosztem prywatności.
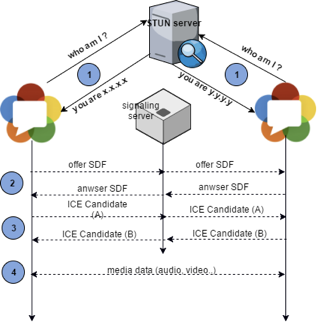
Efektem negocjacji może być ujawnienie wszystkich adresów IP na trasie do przeglądarki (nawet jeśli użyty był VPN czy proxy). Wycieknąć mogą też lokalne adresy IP, które – zwłaszcza w przypadku IPv6 – mogą zostać użyte do fingerprintingu.
Canvas fingerprint
Jest to kolejna metoda fingerprintowania oparta na anomaliach związanych ze stosem graficznym (podobnie jak WebGL fingerprinting). W wersji 5 HTML wprowadzono mechanizm canvas umożliwiający programowe rysowanie grafiki 2D za pomocą JavaScriptu. Przykładowy kod fingerprintujący może wyglądać w następujący sposób:
// tworzymy obiekt canvas
var canvas = document.createElement('canvas');
// informujemy przeglądarkę, że będziemy "rysować" w 2d
var context = canvas.getContext('2d');
// ustawiamy tekst, jaki chcemy "narysować" w canvasie
var textToRender = 'Lubię placki!';
// ustawiamy czcionkę i wielkość tekstu
context.font = "14px 'Arial'";
// rysujemy tekst wewnątrz canvasa kolorem czarnym
context.fillText(textToRender,10,50);
// zamieniamy gotowy obrazek na postać tekstową, tak aby móc go przesłać lub porównać
return canvas.toDataURL();Oczywiście nic nie szkodzi, by dać upust swojej wizji artystycznej i gwałtowniej zmodyfikować napis bądź nawet skupić się na samej grafice – im bardziej skomplikowany obraz, tym bardziej granularny powinien być otrzymany fingerprint.
Audio fingerprint
Ostatnim opisanym w tym artykule będzie audio fingerprint. Jest to przeniesienie koncepcji fingerprintingu opartego na stosie graficznym na… stos dźwiękowy. W przypadku WebGL-a bądź canvasu wykorzystywaliśmy meandry interakcji pomiędzy sobą:
- przeglądarki,
- systemu operacyjnego,
- sterownika karty graficznej,
- samej karty graficznej.
Natomiast tutaj robimy to samo z użyciem karty muzycznej, za pomocą dostępnego w HTML5 API – konkretniej AudioContext. Przykłady takiego fingerprinta wraz z wizualizacją można znaleźć tu. Kod wymaga dłuższego wprowadzenia w niuanse AudioAPI, więc dla zdrowia czytelnika nie będzie tutaj przytaczany i analizowany.
Podsumowanie
Powyższy artykuł miał za zadanie wprowadzić czytelnika w wesoły świat fingerprintów, szans i problemów z nimi związanych, a także przedstawić najczęstsze techniki wykorzystywane przy fingerprintowaniu. W kolejnej części przedstawione zostaną techniki i programy używane przez carderów do oszukiwania systemów fingerprintujących będących częścią mechanizmów antyfraudowych.
Marcin Mostek
Nethone


Komentarze
3 uwagi:
1. bardzo fajny artykuł
2. brakuje mi najpierw pola gry – czyli zakreslenia „spisu tresci cyklu” przed wrzuceniem w fingerprinting
3. i najważniejsza. Nie rozumiem, dlaczego autor nazwał cardera złośliwym.
2) Jasne, następnym razem dodam!
3) Zabieg narracyjny :) Znaczna część ludzi trudniących tym zajęciem jest bardzo pomysłowa i niejednokrotnie wynajduje naprawdę oryginalne rozwiązania w celu ominięcia zabezpieczeń.
Bardzo ciekawy artykuł ! Niedawno czytałem o polskim startupie, który twierdzi, że ochroni nasze konta w banku przed kradzieżą. Coś co nie udaje się ogromnym bankom uda się startupowi? Odważna teza. Nurtuje mnie kilka pytań. Byłbym wdzięczny gdyby ekspert rozwiał moje wątpliwości np. w następnym artykule.
https://www.wykop.pl/link/5123281/polski-startup-ktory-ochroni-twoje-konto-w-banku-przed-kradzieza/
1. Czy to rzeczywiście przełomowe rozwiązanie czy kolejny broker danych który chciałby zarabiać np. na rynku RTB?
2. Czy rzeczywiście ma szanse ochronić konto w banku przed kradzieżą? Złodzieje nie wiedzą o fingerprintach?
3. Czy gdyby to jednak było przełomowe i skuteczne to nie byłoby ogromnym zagrożeniem dla prywatności?
4. Czy wierzycie że dane nie są możliwe do powiązania z konkretnym internautą? A co jeśli nie da się powiązać z imieniem i nazwiskiem, ale np. z danymi medycznymi?
Z tym ekspertem to chyba trochę na wyrost ;)
1) Ciężko powiedzieć nie znam tego systemu. Technicznie rzecz biorąc jest to konkurencja, więc nie będę obiektywny w ocenie.
2) Wiedzą; jest to kolejna warstwa zabezpieczeń – chodzi o zwiększenie kosztu atakującego, tak aby nie opłacało mu się (czasowo lub pieniężnie) dokonać ataku.
3) Fingerprint jest narzędziem i jak w przypadku każdego narzędzia dużo zależy od jego użytkownika. Bardziej obawiał się skali i wiedzy dużych zagranicznych firm na G i F. Polecam tą książkę: https://www.schneier.com/books/data_and_goliath/
4) Na podstawie samego fingerpinta wydaje się to bardzo trudne, wręcz niemożliwe – fingerprint (sam z siebie) nie zawiera przecież danych osobowych – identyfikuje się wejście tego samego użytkownika, bez świadomości kim on jest.
Dziękuję za odpowiedź !
podoba mi sie styl językowy autora artykułu
A ja mam pytanie „z drugiej strony” – jak się przed takim czymś „bronić”? Czy są jakieś gotowe rozwiązania, które pozwalają „oszukać” fingerprinting?
Jedyną opcją są wbudowane zabezpiecznia pokroju tych z Tor Browser.
albo Tor Browser (wszyscy użytkownicy Tor Browser mają ten sam fingerprint) albo maszyna wirtualna na przykład Whonix i w środku skonfigurowana przez ciebie przeglądarka (wtedy fingerprint jest unikalny ale nie powiązany z innymi twoimi działaniami)
podobno istnieją płatne zamkniętoźródłowe programy Fraudfox i Multilogin które mają robić to co normalnie maszyna wirtualna ale nie wiem co trzeba mieć w głowie aby marnować pieniądze na takie trojany podejrzane
Ale za nazwę „FraudFox” to szacun dla autorów :-) Urzekła mnie :)
Ciii, proszę nie spojlerować ! :) będzie opisane w następnej części artykułu :)
Czyli co dla pranoików pozostają osobne kontenery do każdej czynności, inny do banku, inny do fejsa, inny do pornoli a jeszcze inny do zwykłej aktywności…
Do szybkiego sprawdzenia, jak unikatowa jest nasza przeglądarka przydaje się Panopticlick: https://panopticlick.eff.org/
Super artykuł, styl pierwsza klasa.
To zdanie jest odrobinę nie logiczne, albo coś jest identyczne albo nie :
„Powoduje to, że ten sam obraz wyrenderowany na dwóch różnych komputerach wygląda identycznie, ale w praktyce nie jest dokładnie taki sam (różnica kilku pikseli)”
Czytelniejsze wydaje mi się, że byłoby:
„Powoduje to, że ten sam obraz wyrenderowany na dwóch różnych komputerach wygląda podobnie, ale nie jest identyczny i może zawierać kilka różniących się pikseli”
Dziękuje za zwrócenie uwagi, poprawione! Jak widać, dla autora język polski nadal bywa trochę językiem obcym :P
Naprawdę dobry artykuł – oby więcej takich
Czołem,
well done. Dodłbym tylko jedo: wspłczesne rozwizania FP nie są jednordne i w zasazie są to kmbajny scapujące wsystko co powyej jednoczśnie i jeszce dużo węcej. Dopero spojrenie na ssję, użytkwnika, urządenie z lotu ptaka powala na dobra granlację i stablność. Przy czym każde z narzdzi da się obejść i to w zaadzie cakiem łatwo więc FP jako cyrowa tosamość raczej nie będie miła zastoowania na maową skalę, ale uzupłniając ją o dane persnalne i biomtrię daje dużą szase na wykorzstanie tego typu rozwązań do autorzacji.
pozdawiam i czkam na ciąg dalzy.
ps. odpoiadając na pyanie: nie, przed krdzieżą nie ochoni cię to rozwiąznie. Nic Cię nie ocroni poza Tbą saym.
Pozdr
A z wyjasnieniem obrazowo czym jest „fingerprint” nie mozna prościej że to po prostu jak „odcisk palca” użytkownika (słowo fingerprint właśnie to oznacza jakby ktos nie wiedział). Że jest to unikalny „ślad” użytkownika tak jak odcisk palca – u każdego inny.
No nie do końca. Jest to z pewnością marketingowa nazwa, która się najbardziej utarła, stąd też autor wykorzystuje ją by nie dodawać nowego nazewnictwa. Należy zwrócić uwagę na część artykułu dotyczącą zależności pomiędzy stabilnością, a granularnością – kilku różnych użytkowników może mieć ten sam fingerprint.
„…popuścić wodze swojej fantazji i zasypać czytelnika najdrobniejszymi szczegółami technicznymi…”
A ja prosty inżynier myślałem, że szczegóły techniczne wynikają ze ścisłej wiedzy – a tu proszę, fantazja :-)
Ale poza tym ciekawy artykuł, dziękuję za przystępne wyłożenie podstaw fingerprintingu!
Przewaga klasowa karderów nad waszą społecznością nigdy nie zostanie zrozumiana ani zgłębiona przez badaczy.
Znany badacz społeczności karederów Dr. Hab. Mirosław Stefaniak stwierdził w swojej znanej pracy iż karderzy są kreatywni z przymusu i tylko idiota z koroporacji może sądzić iż zajmują się oni procederem kardingowym z nudów.
W związku z czym krzywe dzieci z klasy średniej nigdy nie będą w stanie zabezpieczyć się przed ludźmi którzy po prostu chcą przeżyć. Jako przykład przytoczył bank.
Bank jako instytucja dysponuje wielką ilością gotówki, w związku z czym instaluje wielkiego sjema. Karder jednak myśli inaczej ! Karder myśli „bank tworzą ludzie, ludzie mają rodziny, rodziny mają znajomych, ludzie mają dostęp zdalny …”
Tak więc pytanie nie brzmi czy karderzy zrobią wam fingerprinting, pytanie brzmi czy jesteście gotowi aby chronić siebie nie bank
Możesz podać tytuł tej znanej pracy?
Nie mogę, ponieważ klauzula sumienia mi nie pozwala, poza tym to tajne wszystko jest.
WebRtc brzmi okrutnie nie wiedziałem że coś takiego jest, bardzo tresciwe. Btw. Fajne The JS’y. Czekam na więcej.
” firma Netscape wprowadziła ECMAScript (znany dzisiaj pod nazwą JavaScript)”
Najpierw był LiveScript o którym nikt już nie pamięta. Potem zmienił nazwę na JavaScript, a dopiero teraz jest ECMAScript.
Faktycznie, przepraszam za przekłamanie i dziękuje za znalezienie błędu. Za chwile poprawię.
jou! senkju za obszerny, wmiare przystępnym jęzorem opis:) czekam na ciąg dalszy
tutaj możecie sobie sprawzić wasze przeglądarki odnośnie tego artykułu.
https://browserleaks.com/
„[…] im bardziej skomplikowany obraz, tym granularniejszy powinien być otrzymany fingerprint.”
No nie wiem, ale jeżeli już trzeba używać słowa „granularny”, to ja bym stopniował go inaczej. Raczej:
granularny -> bardziej granularny -> najbardziej granularny
a nie:
granularny -> granularniejszy -> najgranularniejszy
Zrozumieć można, ale wygl
… Zrozumieć można, ale wygląda koślawo :-\
Słuszna uwaga, dziękuję! Poprawiłem.
Poza tym bardzo ciekawy artykuł, merytoryczny i napisany z lekkością (mój ulubiony fragment to: „[…] na wypadek gdyby zbyt awangardowy designer wybrał tak elitarną i hipsterską czcionkę, którą posiada w systemie tylko on sam i Salvador Dali.”)
.
Dobre! :-D
I proszę o więcej!
Doskonały artykuł, z przyjemnością przeczytałem i z niecierpliwością czekam na kolejne.
Świetny artykuł ;)
Brak autoryzacji w bramkach platnosci juz sie nie zdarza, obojetnie jak jest skonfigurowana przegladarka..
Autoryzacja dotyczy zupełnie czego innego – jest to operacja sprawdzenia czy karta nie jest zablokowana / ma wystarczające środki. Odbywa się ona często przez pobranie symbolicznej kwoty, która zostanie po pewnym czasie zwrócona. Przykładowo:
https://www.bigcommerce.com/ecommerce-answers/credit-card-authorization/