Na konferencji Black Hat USA 2018 Ben Gras z Uniwersytetu Vrije w Amsterdamie przedstawił lukę w zabezpieczeniach procesorów Intela, nazwaną roboczo TLBleed. Jak groźny jest TLBleed dla mojego systemu i instytucji?
Już sama zapowiedź tematu prezentacji wzbudziła ogromne zainteresowanie mediów i liczne dyskusje na portalach branżowych i społecznościowych. O prezentacji i luce pisały największe strony, np. TheRegister, ArsTechnica, ZDnet, Techrepublic, TechTarget. Nic dziwnego, gdyż nie tak dawno, bo w styczniu tego roku, podatności Spectre i Meltdown stały się dla Intela i jego klientów źródłem wielu problemów. Okazało się, że ich załatanie za pomocą oprogramowania jest niemożliwe. 15 marca 2018 r. Intel poinformował, że przeprojektuje swoje procesory (co może doprowadzić do strat wydajności), aby pomóc w ochronie przed Spectre i Meltdown. Nowe produkty powinny trafić na rynek do końca tego roku. Zapowiedź TLBleeda wydawała się zatem kontynuacją tej serii. Słychać było głosy o tym, że czarna passa Intela trwa. Czy warto było czekać na TLBLeed?
TLBleed – cele i technika
Celem ataku są procesory Intela wykorzystujące technologię Hyper-Threading, czyli implementację wielowątkowości współbieżnej opracowaną przez firmę Intel i stosowaną m.in. w procesorach Core i3, Core i5, Core i7, Itanium czy Xeon. Badacze z Holandii zaprezentowali metodę pozyskiwania danych z wątku (ang. thread) wykonywanego współbieżnie na tym samym rdzeniu procesora z innym złośliwym i odpowiednio spreparowanym wątkiem. Luka należy do kategorii ataku czasowego kanałami bocznymi (ang. temporal (timing) side channel-attack).
Koncepcja teoretyczna takich ataków jest dość prosta i polega na obserwacji zachowania systemu w czasie, by na tej podstawie wnioskować o jego właściwościach kryptograficznych. Podstawą są zależne od danych właściwości behawioralne implementacji algorytmu kryptograficznego, a nie jego właściwości matematyczne, np. pomiar czasu potrzebnego na udzielenie odpowiedzi na określone hasło/kwerendę wynikający z zależności pomiędzy danymi a zachowaniem algorytmu. Typowym przykładem jest sytuacja, gdy na błędne hasło system odpowiada szybciej niż na poprawne, np. atak na laptopy Toshiby.
Podobna zasada jest wykorzystana w przypadku luki TLBleed. Atakujący nie ingeruje bezpośrednio w kod wykonywanego wątku, a koncentruje się na obserwacji Translation Lookaside Buffers (TLB) – fragmentu systemu odpowiedzialnego za zarządzanie pamięcią podręczną (ang. cache).
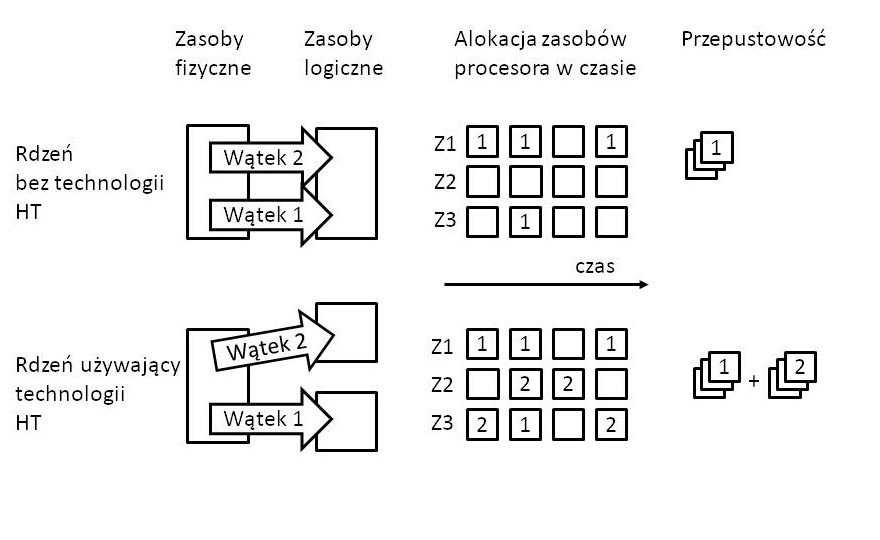
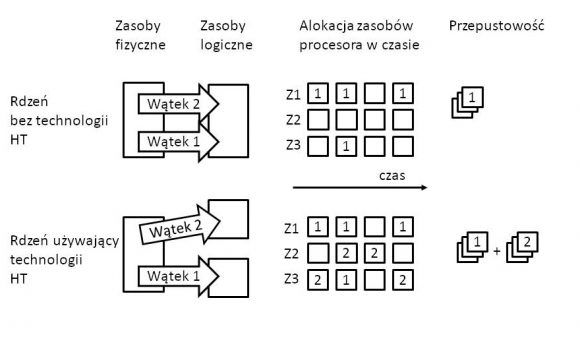
Rysunek 1. Uproszczony schemat zarządzania zasobami rdzenia w procesorze wspierającym technologie Hyper-Threading
We współczesnych implementacjach procesory Intela mają zazwyczaj kilka (kilkanaście) pracujących równolegle fizycznych rdzeni, z których każdy niezależnie pobiera i wykonuje kod (wraz z danymi) z pamięci głównej systemu. Po włączeniu funkcji Hyper-Threading dla każdego fizycznego rdzenia procesora adresowane są dwa (w większości implementacji) rdzenie wirtualne, które można wykorzystać do dzielenia obciążeń wynikających z obliczeń równoległych. Taka implementacja umożliwia zwiększenie liczby niezależnych instrukcji w potoku i wykorzystuje właściwości architektury superskalarnej, w której instrukcje mogą używać równolegle niezależnych danych (patrz Rysunek 1). To pozwala zaoszczędzić zasoby sprzętowe, a w wielu przypadkach przyspieszyć wykonanie kodu o nawet 30%. Kluczem do zrozumienia TLBLeeda jest jednak właściwość implementacji Intela, na mocy której wątki, które współdzielą czas obliczeniowy rdzenia fizycznego, współdzielą też inne zasoby rdzenia, m.in. pamięć podręczną, a także TLB.
Zespół badaczy z Amsterdamu wykorzystał ten sposób zarządzania zasobami procesora i uruchomił na tym samym rdzeniu dwa wątki, z których jeden był przygotowany (dedykowany) do obserwowania drugiego. Obserwacja koncentrowała się na czasie dostępu do pamięci liczonym na podstawie danych z modułu TLB. Bufor TLB to pamięć podręczna wykorzystywana do skracania czasu dostępu do fizycznej lokalizacji pamięci użytkownika będąca częścią jednostki zarządzającej pamięcią (MMU). TLB jest używany do obsługi pamięci wirtualnej i zawiera listę często używanych powiązań (ang. transactions) pomiędzy adresami wirtualnymi a fizycznymi – często nazywany jest cache’em pamięci wirtualnej. Jeśli powiązanie pomiędzy adresem wirtualnym znajduje się w TLB, operacja na danych z pamięci może zostać wykonana szybciej – powiązanie jest dostępne niemal natychmiastowo. W przeciwnym wypadku powiązanie pomiędzy pamięcią wirtualną musi zostać ustanowione – tzw. page walk. Jest to proces czasochłonny w porównaniu z szybkością procesora, ponieważ wiąże się z odczytem zawartości wielu lokalizacji pamięci i wykorzystaniem ich do obliczania adresu fizycznego. Zatem w zależności od tego, czy dane powiązanie znajduje się w TLB, czy też nie, zmienia się czas operacji – dostępu do pamięci.
To umożliwiło Benowi Grasowi napisanie kodu, który poprzez obserwację czasu dostępu do pamięci atakowanego wątku zmieniał w odpowiednim momencie zawartość pamięci podręcznej rdzenia i wymuszał określone zachowanie drugiego wątku, np. odświeżanie pamięci podręcznej. Ponieważ oba wątki (złośliwy i atakowany) mają dostęp do wspólnego cache’u umożliwiło to w rezultacie odczyt pobranych (i wrażliwych) danych. Warto zwrócić uwagę na wysoki poziom skomplikowania ataku. Zespół wykorzystał algorytmy sztucznej inteligencji – w szczególności maszynę wektorów nośnych (ang. support vector machine) – do zidentyfikowania, kiedy program wykonuje wrażliwą operację, taką jak funkcja kryptograficzna (opóźnienia w dostępie do pamięci wynikających z zastosowania TLB). Następnie atakujący odczytał prywatne dane atakowanego wątku z pamięci podręcznej, umożliwiając np. rekonstrukcję kluczy kryptograficznych. Rysunek 2 z publikacji autorów TLBleeda przedstawia przykład. Pierwszy (górny) wykres prezentuje opóźnienia (bez modyfikacji) w dostępie do pamięci wątku atakowanego w miarę pozyskiwania danych z TLB przez wątek szpiegowski. Obszary zacienione pokazują fragmenty przebiegu czasowego odpowiadające operacjom przetwarzającym bity tajnego klucza używanego przez wątek będący celem ataku. Wątek szpiegujący chce sprawdzić, która z operacji matematycznych stosowanych przez bibliotekę kryptograficzną (dup albo mul, patrz źródło) jest używana. Średnia krocząca pokazuje, że sygnał posiada charakterystykę pozwalającą na odróżnienie tych operacji. Ostatni (dolny) wykres prezentuje przebieg czasowy maszyny wektorów nośnych z klasyfikatorem, który bezbłędnie rozróżnia operacje.
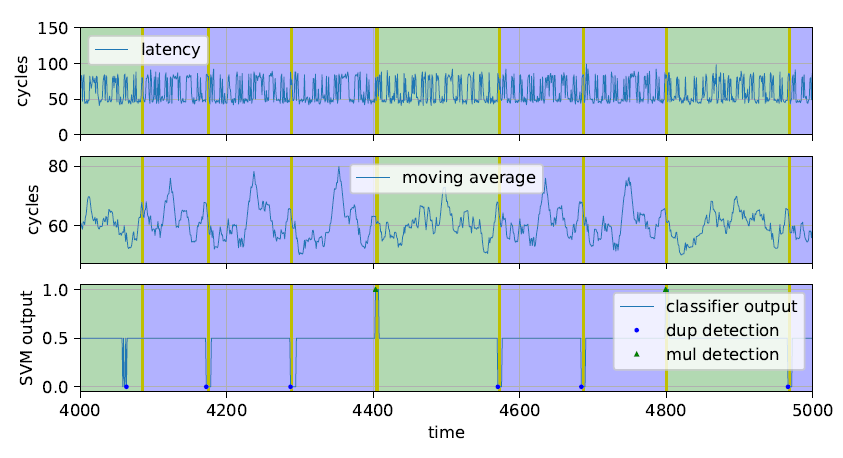
Rysunek 2. Przebieg ataku TLBleed w czasie, źródło – publikacja autorów
W danych zaprezentowanych magazynowi “The Register” autorzy twierdzą, że byli w stanie wykorzystać tę lukę do wyodrębnienia kluczy kryptograficznych z innego uruchomionego programu w 99,8% testów na procesorze Intel Skylake Core i7-6700K, 98,2% testów na procesorze Intel Broadwell Xeon E5-2620 v4 oraz 99,8% testów na wybranych egzemplarzach procesorów z serii Coffeelake. Celem ataku była biblioteka libgcryptowej Curve 25519 EdDSA używająca 256-bitowych kluczy, a średni czas to 17 sekund.
Czy jest się czego bać?
Pierwsze reakcje na informacje o ataku były bardzo ostre i stanowcze. Na przykład OpenBSD zdecydowało się na standardowe blokowanie funkcji Hyper-Threadingu, co pociągnęło falę spekulacji i komentarzy, że mamy kolejną lukę na miarę Spectre i Meltdown. Jednak późniejsze analizy były już bardziej stonowane.
Ataki Spectre i Meltdown były tak groźne, gdyż wymuszały modyfikacje architektury sprzętowej w celu 100% zapobiegania wyciekom danych i uszczelnienia bocznych kanałów. Innymi słowy, łatki w oprogramowaniu były nieskuteczne.W przypadku TLBleeda mamy do czynienia z atakiem, któremu można zapobiec w całości, modyfikując oprogramowanie. Co więcej, atak powiela znany teoretyczny schemat ataku (przykład to praca Colina Pervicala “Cache Missing for Fun and Profit” sprzed 13 lat) i są dostępne gotowe rozwiązania zapobiegawcze. Podobnie jak w przypadku wcześniej znanych kanałów bocznych, algorytmy szyfrowania można zaimplementować w taki sposób, aby ich schemat dostępu do danych był niezależny od klucza szyfrowania. Zlikwidowanie tego powiązania powoduje usunięcie kanału bocznego. Nawet sam odkrywca luki TLBleed twierdzi, że takie modyfikacje poprawiające bezpieczeństwo są obecnie rzadko stosowane, ale ich wprowadzenie nie nastręcza większych problemów i gdyby zostały wykonane, TLBleed nie będzie już dłużej działał.
Również reakcja firmy Intel była bardzo spokojna. Mimo że firma prowadzi program lojalnościowy dla pentesterów, stwierdzono, że problem ten nie kwalifikuje się do nagrody za wykrycie luki bezpieczeństwa. Intel argumentuje, że środki zaradcze przeciwko kanałom podręcznym mogą również chronić przed TLBleedem. Innymi słowy, procesor działa poprawnie, a kod TLBleed opiera się na błędach w implementacji kodu.
W oficjalnym oświadczeniu firmy czytamy (tłumaczenie autora):
Intel został poinformowany o badaniach przeprowadzonych przez Vrije Universiteit Amsterdam, w których przedstawiono potencjalną podatność wynikającą z analizy kanału bocznego, określaną jako TLBleed. Podatność ta nie ma związku ze spekulacyjnym wykonaniem rozkazów, a zatem nie ma związku ze Spectre lub Meltdown. Badania nad metodami analizy kanałów bocznych często koncentrują się na manipulacji i pomiarze charakterystyki (np. czasu) wspólnych zasobów sprzętowych. Pomiary te mogą potencjalnie pozwolić badaczom na uzyskanie informacji o oprogramowaniu i związanych z nim danych. TLBleed wykorzystuje Translation Lookaside Buffer (TLB), pamięć podręczną wspólną dla wielu wysokowydajnych mikroprocesorów. TLB przechowuje aktualne tłumaczenia adresów z pamięci wirtualnej na pamięć fizyczną. Oprogramowanie lub biblioteki oprogramowania, takie jak Intel® Integrated Performance Primitives Cryptography w wersji U3.1 – napisane w celu zapewnienia stałego czasu wykonania i niezależnych od danych śladów pamięci podręcznej – powinny być odporne na TLBleed. Ochrona danych naszych klientów i zapewnienie bezpieczeństwa naszych produktów jest dla firmy Intel priorytetem i będziemy nadal współpracować z klientami, partnerami i badaczami, aby zrozumieć i zminimalizować wszelkie zidentyfikowane słabe punkty.
Chyba najlepszym podsumowaniem jest tutaj opinia końcowa z raportu firmy Red Hat. Red Hat zaleca, aby wszyscy użytkownicy traktowali Hyper-Threading jako część normalnego procesu konfiguracji systemu. Technologia ta pozwala na maksymalizację wydajności, jednak błędnie użyta może prowadzić do zagrożeń dla bezpieczeństwa systemu – takich jak TLBleed i innych podobnych ataków związanych z analizą kanału bocznego. W związku z tym wątków w technologii Hyper-Threading nie należy nigdy postrzegać jako tanich dodatkowych rdzeni, lecz jako nieodłączną część jednego rdzenia. Każdy rdzeń powinien być konfigurowany i testowany jako całość – tak przez użytkownika, jak i system operacyjny. Właściwie zastosowany Hyper-Threading (w wielu przypadkach) faktycznie zwiększa ogólną przepustowość i wydajność systemu, jednak wymaga ostrożnego wykorzystania zasobów współdzielonych systemu.
Jak groźny jest zatem TLBleed dla mojego systemu czy instytucji? Ben Gras pokazał na konkretnym przykładzie, jak nie powinno się używać Hyper-Threadingu – co potwierdzają opinie Intela i Red Hata. Wiele wskazuje jednak na to, że kanał boczny wykorzystany przez TLBleed może być dość prosto uszczelniony. Technologia Intela jest zatem bezpieczna dla użytkownika, jeśli ten zachowuje podstawowe zasady bezpieczeństwa i stosuje się do wskazówek firmy i badaczy.
Adam Kostrzewa: Od ośmiu lat zajmuję się badaniami naukowymi i doradztwem przemysłowym w zakresie elektroniki motoryzacyjnej, a w szczególności systemów wbudowanych pracujących w czasie rzeczywistym do zastosowań mogących mieć krytyczne znaczenie dla bezpieczeństwa użytkowników. W wolnym czasie jestem entuzjastą bezpieczeństwa danych. Szczególnie interesujące są dla mnie sprzętowe aspekty implementacji obwodów elektrycznych i produkcji krzemu. Metody i narzędzia używane do tych zadań nie są aż tak dostępne i dokładnie przetestowane jak oprogramowanie, dlatego też stanowią interesującą dziedzinę do badań i eksperymentów.
Blog: adamkostrzewa.github.io
Twitter: twitter.com/systemWbudowany



Komentarze
M.in. dlatego Apple stosuje osobny core do Secure Enclave, a Trusted Zone, które mają niejako przy okazji, tylko do mechanizmu sprawdzania integralności jądra.
Zgadzam się z Intelem – projektując mechanizmy przetwarzające dane wrażliwe, analizę „co mozna zrobić z wykorzystaniem bocznych kanałów” robi się zawsze. Co jest m.in. elementem certyfikowania systemu do przetwarzania takich danych.
Cała ten hype jest z kategorii „jeśli napiszemy kod nieprawidłowo, to ma dziury!”.
Czy można gdzieś obejrzeć online prezentacje video z tegorocznego Black Hata?
ATAK CZASOWY KANAŁAMI BOCZNYMI…
A może jakiś artykuł o L1TF? To już tydzień.
http://www.intel.com/content/www/us/en/architecture-and-technology/l1tf.html
A ja znalazłem błąd merytoryczny. Co prawda niewielki, ale rzuca się w oczy czytając branżowe artykuły.
Żadna generacja procesorów i5 nigdy nie posiadała Hyper-Threading. :-)
Nieprawda, np. https://ark.intel.com/products/81016/Intel-Core-i5-4210U-Processor-3M-Cache-up-to-2_70-GHz
nie ma błędu gdyż jest wiele procesorów z rodziny i5 wspierających HT, wystarczy użyć wyszukiwarki Intela by to potwierdzić https://ark.intel.com/Search/FeatureFilter?productType=processors&HyperThreading=true
np. z 8 generacji modele Intel® Core™ i5-8400H, Intel® Core™ i5-8300H Processor, Intel® Core™ i5-8269U Processor
Czy jest to na tyle niskopoziomowy wektor ze obecne na rynku virtualizery maskuja/blokują tego typu atak ?
O tym problemie pisze autor TLBleed w wywiadzie dla The Register, https://www.theregister.co.uk/2018/06/22/intel_tlbleed_key_data_leak/
Cytat z artykułu za Benem Grasem:
„Jeśli oprogramowanie jest napisane tak, aby było odporne na działanie ataków kanałami bocznymi – przepływ kontrolny i przepływ danych są stałe i nie zależą od przetwarzanego klucza – [TLBleed] nie będzie działać, ale te implementacje są rzadko spotykane. „
Czyli jednak TLBleed będzie miał wpływ (powinien mieć) na stosowaną strategię wirtualizacji
„In cloud environments, a hypervisor could ensure that a core never simultaneously runs threads from two different virtual machines.”
co oznacza, że albo wyłączamy HT (strata 10-15% wydajności) albo nie mieszamy w jednym core fizycznym dwu 'odmiennych’* instancji virtualnych
* – takich o innym stopniu kontroli czy zaufania do wykonywanego na nich kodu
https://virtualizationreview.com/articles/2016/12/08/should-you-use-hyperthreading-with-vmware.aspx
http://www.vmwarebits.com/content/vcpu-and-logical-cpu-sizing-hyper-threading-explained
Ciekawi mnie czy tylko Intel jest podatny na ten atak. A co z innymi platformami jak AMD? Albo innymi liniami technologicznymi jak ARM, PowerPC?
TLBleed jest w 100% skoncentrowany na Intelu. Rzecznik prasowy AMD w oficjalnym komunikacie stwierdził, że żaden z produktów firmy nie jest podatny na TLBleed:
„Na podstawie naszych dotychczasowych analiz nie zidentyfikowaliśmy żadnych produktów AMD, które są podatne na atak TLBleed zaprezentowany przez badacza. Bezpieczeństwo pozostaje najwyższym priorytetem i będziemy nadal pracować nad identyfikacją wszelkich potencjalnych zagrożeń dla naszych klientów oraz, w razie potrzeby, nad ewentualnym złagodzeniem ich skutków.” źródło https://www.theregister.co.uk/2018/06/22/intel_tlbleed_key_data_leak/
O portowaniu ataku na SMT pisze Red Hat https://www.redhat.com/en/blog/temporal-side-channels-and-you-understanding-tlbleed
̄\_(ツ)_/ ̄
„stwierdzono, że problem ten nie kwalifikuje się do nagrody za wykrycie luki bezpieczeństwa” – kwintesnecja tej korporacji.
Przyczepie się. Muszę.
Ten pierwszy obrazek, z zasobami fizycznymi i logicznymi, trochę mi nie pasuję.
1. Zasób fizyczny nie powinien oddawać do zasobu logicznego, dlaczego tak? To tak jak w warstwach OSI, fizyczna to warstwa najniższa, niepodzielna. Logika natomiast, to może być własnie algorytm, czyli wątek utworzony na bazie procesu. Nawet nie proces, wątek, czyli kod maszynowy. Logika do fizyki bardziej mi pasuje, fizyka do logiki już mniej.
2. Dlaczego w pierwszym przypadku nie wykorzystuje się trzeciego taktu procesora? Przecież za wykorzystanie wszystkich taktów i czas pracy wątków, a raczej przydzielaniem mikrooperacji wykorzystuje się chociażby najprostszy do zdefiniowania algorytm Muntza-Coffmana, który na coś takiego to by nie pozwolił.
3. Dlaczego w pierwszym przypadku nie wykorzystuje się w ogóle drugiego rdzenia? (Z1, Z2, Z3, tak się na diagramach cyklu zegarowego oznacza rdzenie)
Z tego co pamiętam, Hyper-Treading (nie chce mi się tego sprawdzać, mogę walnąć głupotę), to dynamiczna alokacja mikrooperacji w takty zegara, łączona później po jednym cyklu zegarowym i to jest prawda dla tego obrazka – dla Z1: 1,1,2 – Z2: 1,2,2, Z3: 1,1,2,2,2 itp. za to odpowiada kontroler. Ma to na celu takie usprawnienie wykorzystań wszystkich rdzeni, by żaden nie był bezczynny i wykonały multioperację w szybszym czasie (przypominam, że operacje wykonywane przez rdzenie NIE SĄ tożsame).
Natomiast, dalej wracając do pierwszego obrazka, 2 wątki były by w pierwszym przykładzie realizowane dokładnie tak: Z1: 1,1,1,1,1,1 – Z2: 2,2,2,2,2 – Z3: 0,0,0,0,0,0.
No chyba, że to „Z” przedstawia coś innego. Problematyką jest podzielenie wątków na pojedynczych rdzeniach, może ktoś to jakoś tak próbował przedstawić. Zanim wprowadzono odpowiednia synchronizację taktowania w procesorach wielordzeniowych, z tym też był problem, ale obecnie nie występuje (dynamiczne taktowanie rdzeni i procesora).