Czy można pogodzić dostępność danych z ich bezpieczeństwem? Z jednej strony użytkownicy, pragnący łatwiejszego dostępu, z drugiej bezpiecznicy, chcący ten dostęp ograniczać. Jak rozwiązać ten konflikt? Pomóc mogą w tym mechanizmy Microsoftu.
Autorem artykułu jest Marcin Kozakiewicz, TS Security & Compliance, Microsoft.
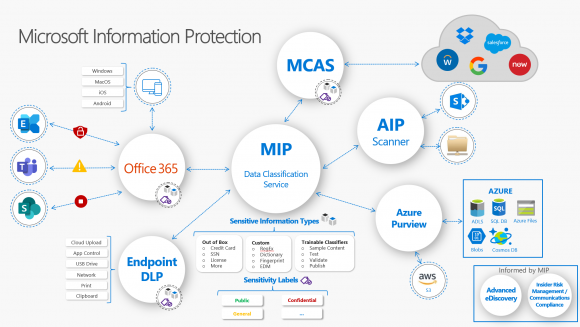
Microsoft 365 zawiera wiele mechanizmów pozwalających na ochronę danych. Możemy je klasyfikować i szyfrować za pomocą Azure Information Protection Unified Labeling (AIP UL), chronić przed wyciekiem za pomocą Data Loss Prevention (DLP) czy kontrolować ich przepływ w chmurze przy użyciu brokera Microsoft Cloud App Security. Wszystkie te elementy umożliwiają tworzenie polityk bazujących na Data Classification Service, dającym jednolite podejście do ochrony informacji w organizacji – Microsoft Information Protection (MIP).
MIP to także sposób, w jaki różne rozwiązania dotyczące ochrony informacji mogą ze sobą współpracować, tworząc skonsolidowaną platformę, pomagającą zabezpieczyć dane niezależnie do tego, czy znajdują się na urządzeniach, w usługach chmurowych czy w serwerach aplikacyjnych (np. Microsoft SharePoint). Relacje pomiędzy poszczególnymi elementami dobrze pokazuje poniższa grafika:
Typy danych poufnych jako podstawa klasyfikacji i ochrony
Powyżej widać także, że wspólny element konfiguracyjny każdej usługi wchodzącej w skład MIP stanowią typy danych poufnych (Sensitive Information Types). Wydaje się to logiczne, ponieważ chcąc zabezpieczyć określone dane, musimy najpierw wiedzieć, czego szukać. Stąd typy danych poufnych to bazujące na wzorcach elementy, których zadaniem jest dopasowanie danych wrażliwych; niejako definicje – szersze lub węższe – poszukiwanych informacji.
Ich charakterystykę stanowi możliwość wykorzystania w różnych elementach MIP. Definiując dany typ informacji poufnych, jeden raz mamy możliwość użycia go zarówno w celu klasyfikacji informacji, jak i w systemie DLP czy w MCAS.
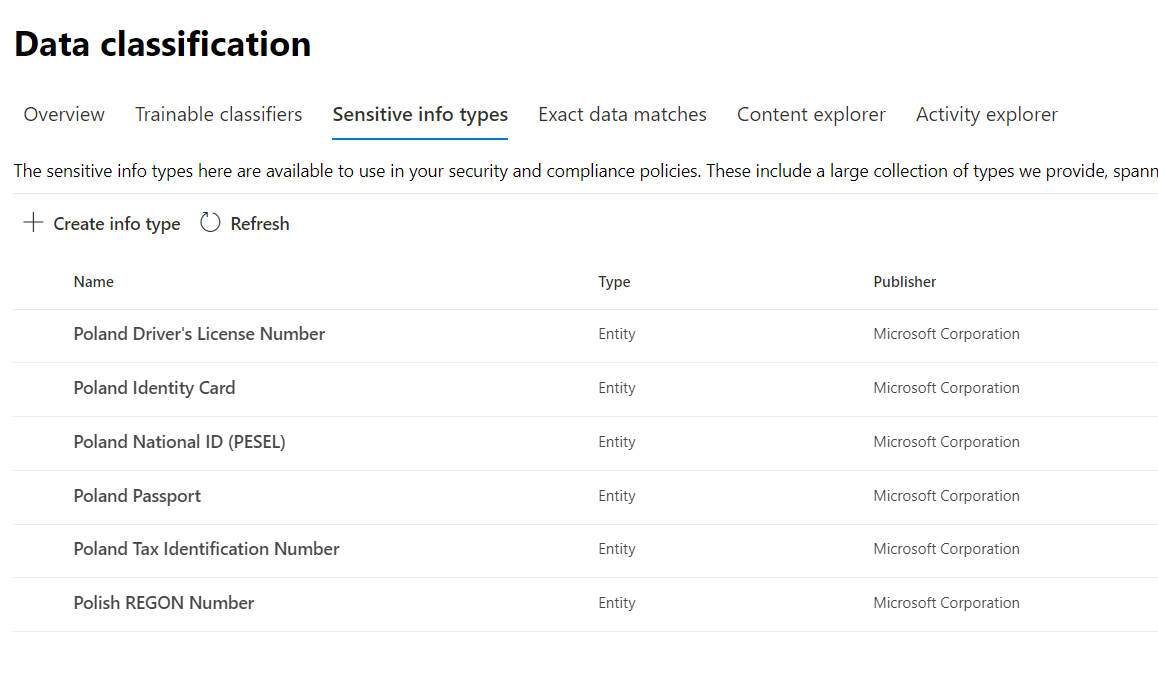
Microsoft 365 udostępnia ponad 200 gotowych do wykorzystania typów danych poufnych, typowych dla określonych krajów – jak numer PESEL czy NIP w przypadku Polski, czy choćby numer rachunku bankowego (IBAN) w przypadku informacji międzynarodowych. I choć w dalszej części artykułu prześledzimy, w jaki sposób tworzyć swoje własne, charakterystyczne dla naszej organizacji typy poufnych danych, to gotowa biblioteka umożliwia szybkie utworzenie reguł dla danych, które organizacje często chcą chronić (na przykład numer karty kredytowej) bez potrzeby tworzenia i testowania ich od zera. Wszystkie są dostępne w portalu Microsoft 365 Compliance w sekcji Data Clasification, na zakładce Sensitive Info Types.
Definicja każdego takiego typu składa się z następujących elementów:
- Primary element – główny mechanizm, który ma za zadanie znalezienie danych wrażliwych. W poszukiwaniu tych danych możemy opierać się na słowie-kluczu, wyrażeniu regularnym lub na dużym słowniku słów-kluczy.
- Supporting element oraz Proximity – mechanizm pomocniczy, którego zadaniem jest potwierdzenie trafności wyszukania. Polega na odnalezieniu danych poufnych tylko w przypadku, kiedy w określonej od nich odległości znajduje się inny element.
- Confidence level – poziom, który określa, na ile istnienie głównego elementu jest potwierdzone za pomocą elementu pomocniczego; im więcej elementów pomocniczych w pobliżu, tym większy poziom pewności.
Przyjrzyjmy się gotowej już definicji na przykładzie wbudowanego typu Poland national ID (PESEL). Oto jego definicja:
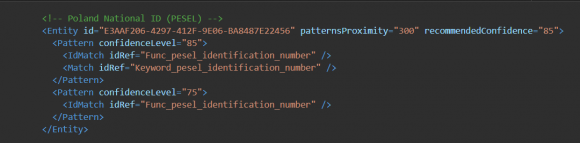
Widać, że przy poziomie pewności 85 brane są pod uwagę: element główny Func_pesel_identification_number i element pomocniczy Keyword_pesel_identification_number.
Aby numer PESEL został prawidłowo odnaleziony, musi on zostać zidentyfikowany przez funkcję, a następnie potwierdzony przez zestaw słów kluczowych (takich jak „dowód osobisty” czy „pesel”) i dodatkowo wszystko to musi się odbyć w obrębie 300 znaków (patternsProximity=300). Przy poziomie pewności do 75 potwierdzenie za pomocą słów kluczowych nie jest już wymagane. Widać więc, jak zmiana wymaganego poziomu pewności wpływa na szerokość wyszukiwania i w jaki sposób można to wykorzystać w ograniczaniu występowania false positives.
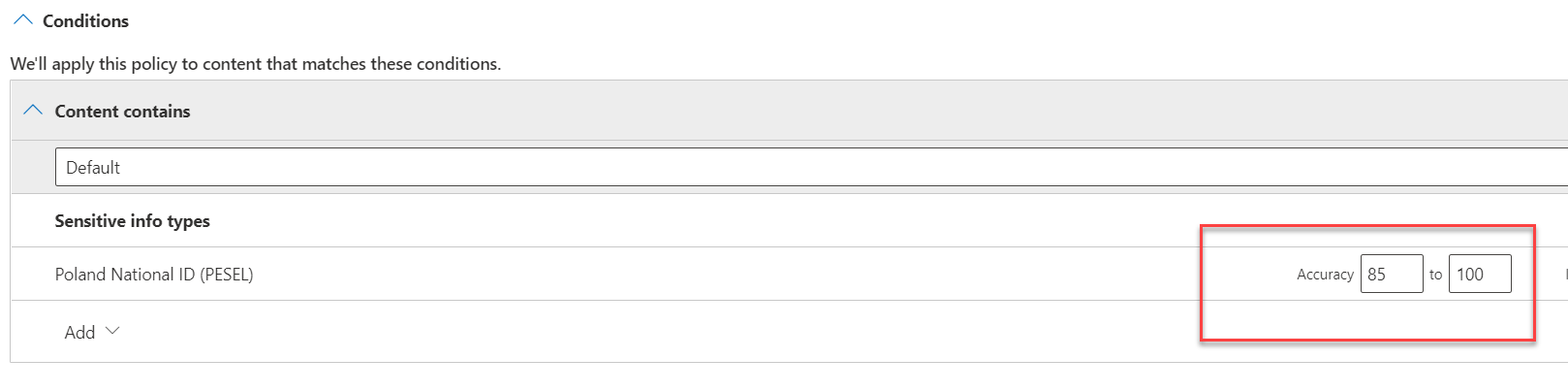
Warto jest znać definicje wbudowanych typów danych poufnych, ponieważ przy budowaniu polityk klasyfikacji danych czy DLP jesteśmy proszeni o określenie dokładności wyszukiwania, czyli właśnie confidence level. Opisy typów danych poufnych znajdziecie w dokumentacji.
Tworzenie własnych typów danych poufnych
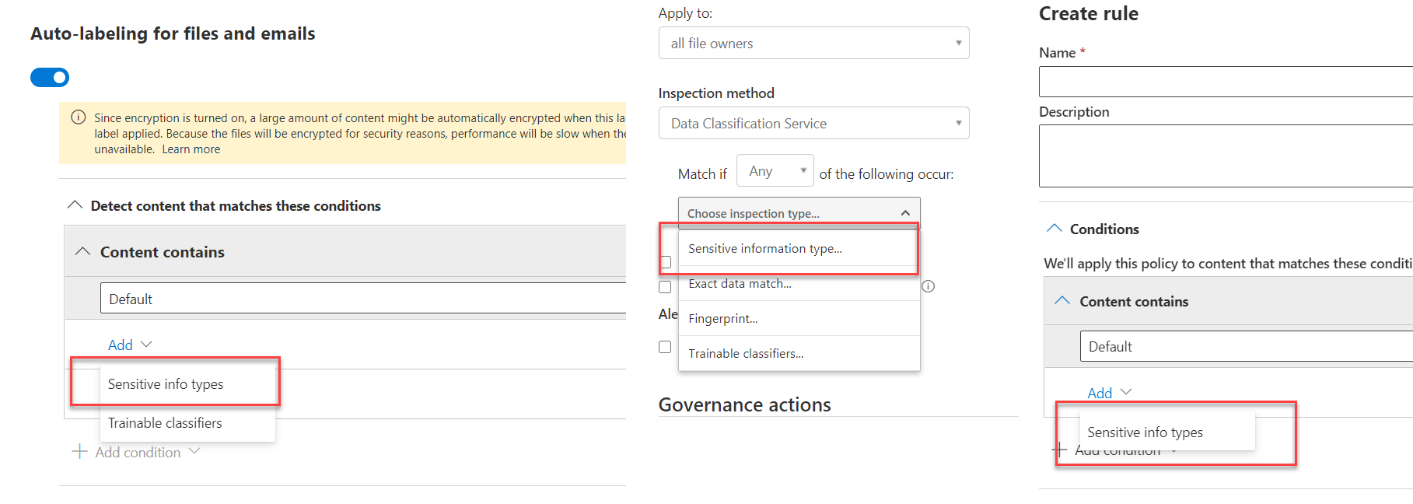
Mimo dużego wyboru wbudowanych typów często będziemy mieli potrzebę zdefiniowania własnych, charakterystycznych dla naszej organizacji. Możemy to zrobić na portalu Microsoft 365 Compliance za pomocą opcji create new info type. Musimy przy tym pamiętać, że należy do tego posiadać odpowiednie uprawnienia (Global admin lub Compliance administrator).
Interfejs pozwoli nam na zbudowanie definicji zgodnej z opisanym wcześniej przykładem.
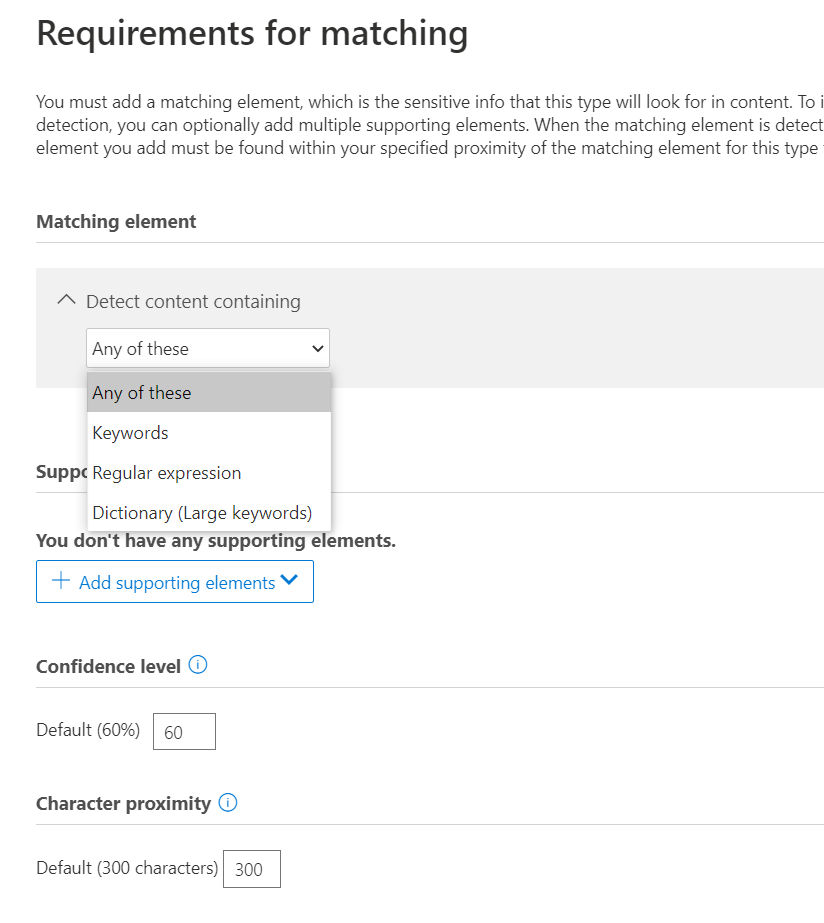
Dostępne mechanizmy wykrywające to:
- wyrażenie regularne (Regular expression) – na bazie silnika Boost.RegEx 5.1.3,
- lista słów kluczowych (Keyword list) – z limitem 50 znaków na jedno słowo,
- słownik (Keyword dictionary) – słownik słów kluczowych z limitem 1 miliona znaków na tenant.
Odcisk palca dokumentu
Taki zestaw możliwości pozwoli nam na zbudowanie wielu rozmaitych definicji. Jednak to nie wszystkie mechanizmy, które system ma nam do zaoferowania. Rezygnując z interfejsu graficznego na korzyść PowerShella, dostaniemy jeszcze jedną funkcjonalność, niedostępną z GUI – odcisk palca dokumentu (document fingerprinting). Pozwala on skonwertować pusty szablon dokumentu i wykrywać na tej podstawie wszystkie dokumenty, które bazują na tym oryginalnym szablonie. Dzięki temu jesteśmy w stanie zbudować mechanizm DLP wykrywający jeden określony typ dokumentów, które utworzono na bazie konkretnego szablonu. Nie szukamy więc tym mechanizmem słowa-klucza ani nie dopasowujemy zawartości do wyrażenia regularnego. Patrzymy natomiast na to, na podstawie jakiego innego dokumentu powstał nasz dokument.
Typ danych poufnych bazujący na odcisku palcu dokumentu tworzymy w następujący sposób:
- otwieramy konsolę PowerShell,
- łączymy się do Microsoft 365 Compliance Center,
- ładujemy szablon dokumentu do zmiennej,
- za pomocą cmdletu New-DlpFingerprint generujemy odcisk palca dokumentu; szablon jest zamieniany na skrót dokumentu,
- za pomocą cmdletu New-DlpSensitiveInformationType tworzymy nowy typ danych poufnych.
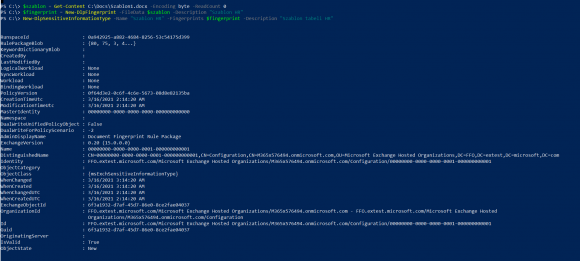
Definicja takiego typu danych w postaci XML wygląda następująco:

Po utworzeniu, gotowy typ danych poufnych jest widoczny w panelu administracyjnym Microsoft 365 Compliance.
Podobnie jak wbudowane typy danych poufnych nie może on być z tego miejsca edytowany.
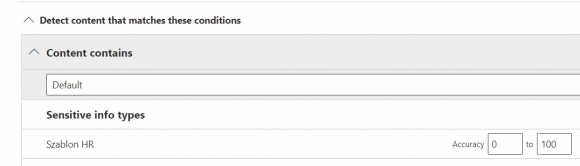
Tak przygotowany typ danych poufnych możemy wykorzystać w definicji reguł DLP.
Należy pamiętać, że wszystkie nasze operacje zostały zalogowane, dlatego tworzenie, zmiana i usuwanie typów danych poufnych są całkowicie rozliczalne.

Istnieją pewne ograniczenia w zakresie rozwiązania i jak zawsze należy je brać pod uwagę przy tworzeniu danego typu danych poufnych:
- tworzony dokument musi zawierać cały tekst z oryginalnego szablonu,
- weryfikowane dokumenty nie mogą być chronione hasłem,
- nie zadziała na dokumenty, które składają się tylko z grafiki.
Co dalej?
Na koniec warto wspomnieć, że to nie wszystkie dostępne metody rozpoznawania danych w dokumentach i wiadomościach. Niektóre typy informacji są trudne, lub wręcz niemożliwe do zdefiniowania przy wykorzystaniu słów-kluczy czy wyrażeń regularnych, a z drugiej strony nie mają na tyle jednolitej struktury, żeby użyć odcisku palca. W takim przypadku na pomoc przychodzą bazujące na modelach uczenia maszynowego klasyfikatory podlegające trenowaniu (Trainable Clasifiers), które „nauczą się” podobieństw między dokumentami, zawierającymi konkretny typ informacji, np. kod źródłowy czy CV.
Kolejnym sposobem wykrywania danych podlegających ochronie jest Exact Data Match, czyli metoda pozwalająca na wyszukanie konkretnych, faktycznych wartości pochodzących z wewnętrznych systemów, na przykład z baz danych.
Podsumowując, przy tworzeniu reguł wykrywających dane poufne możemy korzystać z wielu możliwości, w zależności od tego, czy chcemy, aby systemy odnajdywały konkretne słowa-klucze, posługiwały się jako podstawą szablonem dokumentu czy też klasyfikowały dokumenty, bazując na wcześniej zdobytej wiedzy o ich typie. Mieszanie różnego typu danych poufnych w regułach, elastyczne dostosowywanie wrażliwości wykrywania oraz wykorzystywanie typów danych poufnych w wielu elementach Microsoft Information Protection to jedne z wielu zalet rozwiązań Microsoft 365 Compliance.
Więcej na temat scenariuszy Compliance w środowisku Microsoft 365 można przeczytać w e-booku: Scenariusze compliance dla biznesu: jak Microsoft 365 pomaga chronić informacje w organizacji
Dla pełnej przejrzystości – za publikację powyższego artykułu otrzymujemy wynagrodzenie.



Komentarze
Bardzo udany artykuł, przydałby mi się 3 lata temu, kiedy z tym walczyłem! Linki, które autor podał są BARDZO ważne, nie przechodżcie do włączenia DLP bez zrozumienia typów danych i nie włączajcie też wszystkiego. Pisanie regexów, żeby zdefiniowac własny typ może być naprawdę trudne, bo możliwości są bardzo ograniczone, dlatego nie zapominajcie, że są słowa kluczowe i jest to w rzeczywistości potężne wzmocnienie definicji typu. Nie nastawiajcie się, że regex ma trafić wszystko, raczej skupcie się, by trafiał tylko to, co ma trafić. A, i funkcji nie da się zredefiniować, więc jak macie np. ID klientów, których obieg chcecie śledzić, opcja wyliczania sumy kontrolnej właściwie odpada :/
Takiego wala, abym komukolwiek dal odcisk palca.
PS Jak to jest – jeszcze 20 lat temu odciskiem palca dysponowaly tylko Policja i rozne agentury (i to czesto nielegalnie), a dzis normy same im na tacy go podaja. Wystarczylo 20 lat, czyli nawet nie jedno pokolenie, aby urobic to towarzystwo do narzuconych racji i jeszcze Kowalskie beda bronic swoja piersia tego rozwiazania, ze niby to wygodne, bezpieczne i nowoczesne. I jak tu nie czekac na reset tego bezrozumnego stada? Przeciez oni az sie prosza o zaglade.
Ekhm… artykuł jakby nie o tym.
Jedno z drugim uwazam za powiazane. Rzecz jasna nikt nie musi sie ze mna zgadzac, jednak swoje zdanie – i to konkretne – wyrazilem.
Nowy dowód osobisty wymaga odcisku. Jak to obejdziesz. Jak załatwisz wiele spraw bez niego.
@p0k3m0n @Józio
W artykule nie chodzi o odcisk palca człowieka tylko odcisk dokumentu.
p0k3m0n ma rację.
Odcisk, to odcisk.
Przez tydzień nie mogłem chodzić po weselu.
Nie wyobrażam sobie miesięcznego L4 po napisaniu pisma.
Co to, to nie!
Józio,p0k3m0n
idźcie podyskutowac na jakąs interie i czy inną wp.
Wszystko fajnie tylko, że większość funkcji wymaga E5.. co jest 'nieco’ kosztowne.. Fajnie, że MS mocno inwestuje w security, ale większość tooli jest nadal ciężka w współpracy.. plus masz 6 konsolek które musisz ogarnąć jeżeli chcesz mieć to w sensowny sposób zrobione.. imho da się lepiej, brakuje tylko porządnego QoL improvementu.