
… czyli opowieść o tym, jak z publicznych pieniędzy stworzono zamknięte rozwiązanie i źródło zarobku kilku prywatnych firm, bo ustawa nie mówiła, że tak nie wolno.
Podczas projektowania dowodów rejestracyjnych w 2004 roku, ustawodawca przewidział umieszczenie na nich kodu 2D, który pozwoli w prosty sposób przenieść dane „do komputera”. Polska Wytwórnia Papierów Wartościowych zrealizowała pomysł w dość niestandardowy sposób i… kazała płacić abonament za możliwość automatycznego sczytywania informacji z dowodów. W tym artykule zbieramy dotychczas dostępne informacje wraz z archiwalnymi pismami dostarczonymi przez różne strony w wyniku „boksowania się” z PWPW. Udostępniamy również informacje o faktycznej implementacji kodu oraz pierwszą otwartoźródłową aplikację na Androida, która pozwala na skanowanie dowodów rejestracyjnych.
Od kilku lat każdy zmotoryzowany obywatel Polski posiada dowód rejestracyjny pojazdu wyposażony w charakterystyczny element. Jest to tak zwany kod AZTEC, będący zapisem cyfrowym wszystkich informacji zawartych w dokumencie. Cel wprowadzenia takiego rozwiązania był szczytny, bo miał uprościć pracę stacji kontroli pojazdów i ubezpieczycieli. Wystarczy przygotować moduł, który automatycznie wprowadzi zeskanowane dane do firmowej bazy i w ten sposób ekspresowo przejść do załatwiania sprawy.

Obowiązujący wzór dowodu rejestracyjnego. W lewym dolnym rogu znajduje się wspomniany AZTEC.
No to gdzie jest haczyk? Mniej więcej w zwrocie “wystarczy przygotować moduł”. Symbol faktycznie jest zgodny ze specyfikacją AZTEC, ale znajdujące się w nim dane są zakodowane bliżej nieokreślonym algorytmem. Reasumując: kod jest, jakieś dane w nim są, ale nikt nie wie, w jaki sposób te informacje wydobyć.
“Kod Aztec, czyli jak celowo utrudnić sobie życie”
Sprawę już w maju 2014 roku poruszył dziennikarz TVN Turbo Tomasz Bodył. W swoim artykule na portalu motoryzacyjnym Interii zastanawiał się on, dlaczego pomimo upływu wielu lat od wprowadzenia AZTEC-a nadal nie jest on powszechnie używany choćby przez drogówkę:
Kontrola drogowa. Oczywiście, jak każdemu z nas, bardzo mi zależy na ułatwieniu życia policjantom. Czy zatem zamiast mozolnie przepisywać dane samochodu do swoich kajecików nie mogliby zeskanować kodu?
Dziennikarz zauważył również słabe wykorzystanie kodów wśród innych organizacji, które mogłyby być zainteresowane automatycznym odczytem informacji:
Po długich dociekaniach dowiedziałem się, że podobno korzystają z niego niektórzy ubezpieczyciele (ja u takiego jeszcze nie byłem), jakaś bardzo mała część stacji kontroli pojazdów (nie spotkałem się) i niektórzy dealerzy.
Słabe wykorzystanie AZTEC-ów wynika z pewnych trudności implementacyjnych, które dla wielu programistów okazały się nie do przeskoczenia. Mianowicie nie istnieje żaden oficjalny i publicznie dostępny dokument, który wyjaśniłby, w jaki sposób informacje zostały zakodowane.
Techniczne wyjaśnienie problemu
Poniżej prezentujemy konkretne wyjaśnienie sytuacji dla osób technicznych. Uspokajamy, że z punktu widzenia artykułu tę sekcję można bezpiecznie pominąć. Problem z punktu widzenia typowego programisty wygląda następująco:
- Skanujemy kod za pomocą skanera AZTEC (np. ten znajdujący się na wzorze dowodu rejestracyjnego) i otrzymujemy następujące dane:
BgQAANtYAAJDAPkxAHwAQXIw7zcGNN4ANiox+w81HrUGOP8eUABSAEUA+1oAWQBEDv9OAFQAIABN3wAuClMAvlQPV/eKUhq9Wg5X7k58UtcWSVq9TF5J79pBZ+5PAEsG12bTSm5GVQBM/ntSAEH7L1dj+0MAS1vvMvovewo3Ut4wDi39HjEAN6Pbl0FNe3YgPt5Q3kv3IlSevVnX1z9FMmuCShL2WgBaG9umKADvSAApJnx75k+itwZMAEx9X0rvbkSOTXtOOF/DRy0WOW53fPYLFoMzLr0xAi3DGnevLQOCfJ/vQZ5TcBZrN0oa9k4AfA82Q4QaDzj3q8deN6sN7zIE/1x8lbMnQdwBQi5ZT86jL2tqNAr2MwAw34xSH+uPSVPYFxZThBMzON8AMJM5wQA3MwRcMX7bNcET2jInwyedE01HZ4dlM94qKy0DL38fNgAqeBszSxOvNIeKfHM7fCLxNQAwVkMtdzl7Xiw/YMyrFzxQACBWw+Hza7c3C93/NWuHg1OWRquPQ5KP02K9IBZT4QZC9oNZU7aXFiOX83U4ADJFC7ADhrNVCyOW8w9qMbEnZhdHbHxjdjIT7E4DW0M3OQuGaxYmCSSSSSr/
- Dekodujemy algorytmem Base64 i otrzymujemy następujące dane:
$ base64 -d vehicle.bin | xxd
00000000: 0604 0000 db58 0002 4300 f931 007c 0041 .....X..C..1.|.A
00000010: 7230 ef37 0634 de00 362a 31fb 0f35 1eb5 r0.7.4..6*1..5..
00000020: 0638 ff1e 5000 5200 4500 fb5a 0059 0044 .8..P.R.E..Z.Y.D
00000030: 0eff 4e00 5400 2000 4ddf 002e 0a53 00be ..N.T. .M....S..
00000040: 540f 57f7 8a52 1abd 5a0e 57ee 4e7c 52d7 T.W..R..Z.W.N|R.
00000050: 1649 5abd 4c5e 49ef da41 67ee 4f00 4b06 .IZ.L^I..Ag.O.K.
00000060: d766 d34a 6e46 5500 4cfe 7b52 0041 fb2f .f.JnFU.L.{R.A./
00000070: 5763 fb43 004b 5bef 32fa 2f7b 0a37 52de Wc.C.K[.2./{.7R.
00000080: 300e 2dfd 1e31 0037 a3db 9741 4d7b 7620 0.-..1.7...AM{v
00000090: 3ede 50de 4bf7 2254 9ebd 59d7 d73f 4532 >.P.K."T..Y..?E2
000000a0: 6b82 4a12 f65a 005a 1bdb a628 00ef 4800 k.J..Z.Z...(..H.
000000b0: 2926 7c7b e64f a2b7 064c 004c 7d5f 4aef )&|{.O...L.L}_J.
000000c0: 6e44 8e4d 7b4e 385f c347 2d16 396e 777c nD.M{N8_.G-.9nw|
000000d0: f60b 1683 332e bd31 022d c31a 77af 2d03 ....3..1.-..w.-.
000000e0: 827c 9fef 419e 5370 166b 374a 1af6 4e00 .|..A.Sp.k7J..N.
000000f0: 7c0f 3643 841a 0f38 f7ab c75e 37ab 0def |.6C...8...^7...
00000100: 3204 ff5c 7c95 b327 41dc 0142 2e59 4fce 2..\|..'A..B.YO.
00000110: a32f 6b6a 340a f633 0030 df8c 521f eb8f ./kj4..3.0..R...
00000120: 4953 d817 1653 8413 3338 df00 3093 39c1 IS...S..38..0.9.
00000130: 0037 3304 5c31 7edb 35c1 13da 3227 c327 .73.\1~.5...2'.'
00000140: 9d13 4d47 6787 6533 de2a 2b2d 032f 7f1f ..MGg.e3.*+-./..
00000150: 3600 2a78 1b33 4b13 af34 878a 7c73 3b7c 6.*x.3K..4..|s;|
00000160: 22f1 3500 3056 432d 7739 7b5e 2c3f 60cc ".5.0VC-w9{^,?`.
00000170: ab17 3c50 0020 56c3 e1f3 6bb7 370b ddff ..<P. V...k.7...
00000180: 356b 8783 5396 46ab 8f43 928f d362 bd20 5k..S.F..C...b.
00000190: 1653 e106 42f6 8359 53b6 9716 2397 f375 .S..B..YS...#..u
000001a0: 3800 3245 0bb0 0386 b355 0b23 96f3 0f6a 8.2E.....U.#...j
000001b0: 31b1 2766 1747 6c7c 6376 3213 ec4e 035b 1.'f.Gl|cv2..N.[
000001c0: 4337 390b 866b 1626 0924 9249 2aff C79..k.&.$.I*.
- Pod spodem znajduje się kolejna warstwa kodowania/kompresji, bliżej nieokreślona. Entropia i kilka prostych testów statystycznych wskazuje, że dane raczej nie są zaszyfrowane. Nie wiadomo jednak, co dokładnie trzeba zrobić, aby te dane odkodować do postaci “otwartego tekstu”.
Informacja publiczna? No, nie do końca…
Około dwóch lat temu sprawa była przedmiotem dyskusji na portalu wykop.pl, gdzie użytkownik v3l0c1r4pt0r napisał tak:
Na pewno duża część z Was ma własne cztery kółka, a zatem często w swoim portfelu trzyma dowód rejestracyjny. Być może niektórzy zauważyli w nich tajemniczy kod dwuwymiarowy przypominający popularne kody QR. Czy zastanawialiście się jednak do czego służy?
Ja się zastanowiłem. A było to mniej więcej rok temu, przy okazji wprowadzenia przez ministerstwo usługi HistoriaPojazdu.gov.pl. Zajmowałem się wtedy aplikacją androidową, która miała ułatwić korzystanie z tego serwisu. (…) Wpadłem jednak wtedy na pomysł, żeby dane do owej aplikacji można było wprowadzić w sposób zautomatyzowany. (…)
Krótki research w Google pokazał jednak, że tak naprawdę nikt nie wie jak to ustrojstwo rozkodować. Dowiedziałem się tyle, że owy kod zwie się kodem Aztec, znalazłem skaner na smartfona i tyle. Próbowałem przejść dalej na wszystkie możliwe sposoby: ręczne dekodowanie, szukanie wszelkich wskazówek w necie, po czym doszedłem, że kod ten jest najprawdopodobniej kompresją bezstratną, nauka algorytmów kompresji, ściąganie nawet najbardziej egzotycznych dekompresorów i nic. Ostatecznie miałem pewną teorię co do formatu zapisu, ale mimo to nie byłem w stanie odgadnąć całego algorytmu. Poddałem się.
Niecały rok później, a więc ok. miesiąc temu spróbowałem raz jeszcze. Tym razem udało mi się znaleźć program, który lokalnie dekompresował te dane. Po paru(nastu) wieczorach reverse engineeringu z dekompilatorem i debuggerem byłem w stanie prawidłowo odtworzyć cały proces. Owocem tego jest aplikacja pod linkiem powyżej.
(Wspomniany link: https://github.com/v3l0c1r4pt0r/delz (web archive), we wszystkich cytatach zachowaliśmy pisownię oryginalną – przyp. red.)
I w ten sposób zrodziła się prawdopodobnie pierwsza “wolna” implementacja dekodera kodów z dowodów rejestracyjnych. Jej problemem było to, że budziła wątpliwości w zakresie praw autorskich, co przyznał sam autor. W rozmowie pod znaleziskiem na wykopie pojawiło się jednak ważne pytanie:
dlaczego nie próbowałeś ustalić czym jest ten kod i jak go dekodować po prostu pytając w trybie dostępu do informacji publicznej?
– maniac777
co spotkało się z odpowiedzią autora implementacji:
bo moje życie nie składa się wyłącznie z siedzenia na wykopie a taka sprawa zapewne przeszłaby przez wszystkie instancje sądownictwa administracyjnego a poza tym nie jestem prawnikiem tylko programistą. Tak było po prostu łatwiej
Niezadowolony z takiej odpowiedzi wykopowicz postanowił udowodnić, że polska administracja pomoże w dojściu do prawdy i sformułował do rządowego Centralnego Ośrodka Informatyki oraz Ministerstwo Infrastruktury i Rozwoju następujące pismo:
Działając na podstawie art 61 konstytucji wnoszę o informacje publiczną na temat formatu zapisu danych w kodzie 2D znajdującym się na jednej ze stron dowodów rejestracyjnych wydawanych od 2004 roku który we wzorze opisanym w rozporządzeniu z dnia Dz.U. 2002 nr 133 poz. 1123 (tekst jednolity Dz.U. 2014 nr 0 poz. 1522) znajduje się w miejscu opisanym jako „pole dla kodu kreskowego”. W szczególności wnoszę o:
- Informację na temat tego jaki to rodzaj graficznego kodu 2D.
- W jakim formacie zapisane są dane?
- Jakie informacje są w tych danych zawarte?
- Dokumentacji technicznej (lub jej fragmentów) będącej w posiadaniu organu opisującej format danych i/lub opis formatów i algorytmów używanych do zapisu i odczytu kodu i informacji w nim zawartych.
Korespondencję w tej sprawie proszę kierować do mnie za pomocą środków komunikacji elektronicznej zgodnie z art. 39′ ustawy z dnia 14 czerwca 1960 r. Kodeks postępowania administracyjnego (Dz. U. z 2000 r. Nr 98, poz. 1071, z późn. zm.).
Efekty ponownie opisuje użytkownik maniac777:
Okazuje się że być może faktycznie lepiej było posiedzieć nad kodem. COI odpowiedziało że nie ma tych informacji. PWPW nie odpowiedziała w terminie. Zadzwoniłem i chciałem sprawdzić do kogo trafiają maile z [email protected] i się wdałem w czeski film :). Telefony ze strony odbiera portiernia skierowała do informatyków, informatycy ustalili że odbiorców jest dwóch i podali ich nazwiska zapamiętałem jedno, zadzwoniłem ponownie na centralę centrala powiedziała że mają dwóch pracowników o tym imieniu i nazwisku. Jedna Pani jest na produkcji, druga w kancelarii głównej. Uznałem że to kancelaria główna. Kancelaria główna pracuje jak chce ale udało mi się ustalić że odbierają pocztę i wniosek trafił do innej kobieciny (podali numer telefonu i nazwisko) postanowiłem zadzwonić dowiedziałem się że już mają odpowiedź tylko musi podpisać dyrektor (maila :p). Ostatecznie dotarł po kilku dniach skan pisma zatytułowany „stanowisko” z odmową udostępnienia informacji ponieważ wg PWPW nie jest to informacja publiczna wyszczególniona w art 6 ustawy. (…)
Po tej odpowiedzi użytkownik zrezygnował z dalszych kontaktów, a sprawa pozostała nierozwiązana.
Pismo do PWPW
W zbliżonym czasie również inne osoby kierowały pisma do PWPW z prośbą o udostępnienie informacji na temat dekodowania AZTEC-ów. Udało nam się dotrzeć do pisma z odpowiedzią udzieloną w 2015 roku.

Oryginał przesłanego zdjęcia z pismem od PWPW
Dotyczy: udostępnienia biblioteki dekodującej dane z kodu Aztec z dowodu rejestracyjnego.
W nawiązaniu do Pana pisma (usunięte) w sprawie umożliwienia odczytywania danych z kodu 2D AZTEC znajdującego się na dowodach rejestracyjnych informuję, że możliwe jest udostępnienie terminowej i określonej co do zakresu licencji na wykorzystanie stosownej biblioteki, umożliwiającej odczyt danych technicznych pojazdu oraz numeru rejestracyjnego bez możliwości odczytu danych osobowych.
Licencjobiorca:
(usunięte)
Zakres wykorzystania licencji: odczyt danych technicznych pojazdu oraz numeru rejestracyjnego, bez możliwości odczytu danych osobowych, tylko na potrzeby związane z wykorzystaniem oprogramowania Pana/Pana firmy. Deszyfracja ww. danych może odbywać się jedynie centralnie bez rozproszonej dystrybucji udostępnionej biblioteki.
Termin ważności licencji: roczny z możliwością odnowienia w kolejnych latach.
W celu dalszego załatwienia sprawy i określenia warunków, konieczne jest podanie poniższych informacji:
dokładna i pełna nazwa wnioskującego podmiotu, któremu będzie udzielana licencja oraz adresu,
opis sposobu i celu wykorzystania informacji zawartych w kodzie 2D AZTEC,
precyzyjne wskazanie instytucji, którym będzie udostępnione rozwiązanie.
W związku z powyższym po otrzymaniu powyższych informacji będzie możliwe dokonanie stosownych uzgodnień technicznych i warunków finansowych związanych z przygotowaniem stosownej wersji biblioteki.
W przypadku dodatkowych pytań, osobą upoważnioną do udzielania informacji jest p. Wojciech Kowalczyk, tel. (usunięte).
W związku z taką odpowiedzią ta sama osoba przesłała listę pytań do rzecznika prasowego:
Ile szacunkowo wydano dowodów rejestracyjnych od 1 października 2004 r. (wg nowego wzoru)?
Ok. 50 mln sztuk.
Z czyich środków finansowany jest druk dowodów rejestracyjnych?
Kwestie te reguluje umowa pomiędzy Ministerstwem Infrastruktury i Budownictwa a PWPW oraz umowy z urzędami (Starostwa Powiatowe i Urzędy Miast).
Z tej wypowiedzi wynika, że produkcja dowodów rejestracyjnych jest prawdopodobnie finansowana z budżetów poszczególnych miast, które z kolei są zasilane pieniędzmi pobieranymi bezpośrednio od interesantów (za wydanie dowodu rejestracyjnego należy wnieść opłatę).
Kto jest autorem algorytmu dekodującego dane zawarte w kodzie Aztec (dwuwymiarowym kodzie kreskowym) na dowodzie rejestracyjnym?
Autorem algorytmu kodu Aztec jest firma ZETO Koszalin.Kto i w jaki sposób wybrał firmę ZETO Koszalin jako jedyny podmiot dostarczający oprogramowanie do dekodowania danych z kodu Aztec w dowodach rejestracyjnych?
Firma ZETO Koszalin została wybrana przez PWPW w wyniku postępowania na zasadach określonych w regulaminie zamówień PWPW.Na jakiej podstawie pobierana jest opłata za bibliotekę do dekodowania danych w dowodach rejestracyjnych? Jaka jest licencja tego oprogramowania?
Istnieją dwa rodzaje odbiorców: komercyjni i niekomercyjni. Odbiorcy niekomercyjni (wskazani przez Ministerstwo Infrastruktury i Budownictwa) otrzymali licencję bezpłatną. Odbiorcy komercyjni mają licencję płatną. O szczegóły związane z licencją płatną dla odbiorców komercyjnych proszę pytać ZETO Koszalin.
Ta wypowiedź sugeruje, że choć PWPW zamówiło usługi od firmy ZETO Koszalin, to nie doszło do przekazania autorskich praw majątkowych, więc wspomniane ZETO nadal może zarabiać na oprogramowaniu do dekodowania.
Dlaczego algorytm służący do dekodowania danych zawartych w kodzie Aztec z dowodów rejestracyjnych nie jest jawny? Czemu służy zaciemnianie tych danych?
W algorytmie zaszyte są dane osobowe i techniczne zawarte w dokumencie oraz informacje zabezpieczające z systemu produkcyjnego, które stanowią tajemnicę przedsiębiorstwa. To dlatego algorytm nie może być jawny.
Zeskanowanie dowodu rejestracyjnego jest możliwe tylko wtedy, kiedy zostanie on udostępniony przez jego posiadacza… a skoro mamy już dowód w rękach, to równie dobrze można zrobić zdjęcie lub zwyczajnie przepisać wydrukowane dane. Przecież sam kod ma jedynie ułatwić przepisywanie danych!
Jeżeli algorytm jest tajemnicą przedsiębiorstwa, to dlaczego ZETO Koszalin / PWPW nie reaguje na doniesienia o złamaniu tego algorytmu oraz działania innych podmiotów oferujących odpłatnie złamany algorytm?
Proceder udostępniania kodu Aztec przez strony trzecie jest znany PWPW, ale zgodnie z informacją zawartą w pkt. 3 to firma ZETO jest autorem algorytmu i tylko ona może podjąć stosowne kroki prawne. Obecnie w PWPW trwają prace nad wprowadzeniem odpowiednich zabezpieczeń i zmianą sposobu licencjonowania biblioteki.Podobno planowane są zmiany w strukturze dowodów rejestracyjnych – czy będą one też obejmowały zmiany w kodzie Aztec? Jeżeli tak, to czy nowy algorytm będzie jawny?
Niestety, nie możemy Pani udzielić informacji o planowanych zmianach. To obszar kompetencji ministerstwa właściwego ds. transportu.Z poważaniem
Paweł Prus
Rzecznik prasowy PWPW
Utrudnienia zasygnalizowane przez Komisję Nadzoru Finansowego
Problemy z odczytywaniem kodów z dowodów rejestracyjnych objawiły się w raporcie KNF z listopada 2017 r. (pozycja 68, strona 103):
Umożliwienie odczytywania kodów polowych 2D AZTEC na dowodach rejestracyjnych pojazdów
W celu zautomatyzowania procesów odczytywania danych zasadne byłoby zdjęcie mechanizmu szyfrowania z kodów polowych 2D Aztec na dowodach rejestracyjnych pojazdów lub ujawnienie zakładom ubezpieczeń klucza szyfrującego. Pożądana byłaby zmiana rozporządzenia w sprawie rejestracji i oznaczania pojazdów.
W ramach prac Zespołu przedstawiciel PIU [Polskiej Izby Ubezpieczeniowej – przyp. red.] zwrócił uwagę, że szyfrowanie danych zawartych na dowodach rejestracyjnych pojazdów w kodzie polowym 2D Aztec nie wynika z żadnych przepisów prawa i uniemożliwia automatyczne odczytywanie danych za pośrednictwem skanera podczas operacyjnej działalności zakładów ubezpieczeń. Wskazał, że zasadne byłoby zdjęcie szyfrowania lub ujawnienie klucza szyfrującego.
PODJĘTE DZIAŁANIA:
MR [Ministerstwo Rozwoju – przyp. red.] nawiązało kontakt z MIB [Ministerstwem Infrastruktury i Budownictwa – przyp. red] w celu wyjaśnienia kwestii szyfrowania danych na dowodach rejestracyjnych pojazdów w kodzie polowym 2D Aztec
W opinii MIB wyłącznym posiadaczem praw autorskich do mechanizmów (algorytmów) kodowania/dekodowania danych zawartych w kodzie 2D AZTEC dowodu rejestracyjnego jest Polska Wytwórnia Papierów Wartościowych S.A. – producent dowodów rejestracyjnych, wybrany przez ministra właściwego do
spraw transportu na podstawie art. 75d ustawy z dnia 20 czerwca 1997 r. – Prawo o ruchu drogowym (Dz. U. z 2017 r. poz. 1260).
Podmioty zainteresowane uzyskaniem dostępu do mechanizmów pozwalających
na odczyt danych z kodu 2D AZTEC drukowanego w dowodzie rejestracyjnym mogą kierować wnioski w tej sprawie bezpośrednio do PWPW S.A. MIB wyjaśnia jednocześnie, że rozporządzenie Ministra Infrastruktury
z dnia 22 lipca 2002 r. w sprawie rejestracji i oznaczania pojazdów (Dz. U. z 2016 r. poz. 1038) określa jedynie miejsce umiejscowienia kodu kreskowego w dowodzie rejestracyjnym, w ramach uprawnienia wynikającego z delegacji ustawowej do określenia wzoru dowodu rejestracyjnego. Rozporządzenie to nie reguluje kwestii technicznych dotyczących kodu 2D Aztec zamieszczanego w dowodzie rejestracyjnym przez jego producenta, w tym kwestii jego kodowania/dekodowania. Tym samym nie zawiera regulacji stanowiących barierę prawną w umożliwieniu ich odczytywania.
Jednocześnie w ramach prac Zespołu wskazano, że dostawcą mechanizmu szyfrowania danych na dowodach rejestracyjnych pojazdów w kodzie polowym 2D Aztec jest firma ZETO Koszalin Sp. z o.o.
REKOMENDOWANE DALSZE DZIAŁANIA:
Podjęcie działań przez PIU, we współpracy z MIB, GIODO, PWPW S.A. i ZETO Koszalin Sp. z o.o., w zakresie uwzględnienia postulatu sektora ubezpieczeniowego dotyczącego umożliwienia automatycznego odczytywania danych na dowodach rejestracyjnych pojazdów w kodzie polowym 2D Aztec.
Zapytanie przedstawiciela Polskiej Izby Ubezpieczeniowej sugeruje, że programista powiązany z tą organizacją również analizował AZTEC zawarty w dowodach rejestracyjnych, ale dodatkową warstwę kompresji zidentyfikował jako formę szyfrowania i zaprzestał dalszej analizy. Pytanie zwraca jednak uwagę na bardzo istotny problem – w dokumentach wydanych przez administrację publiczną i wyprodukowanych z publicznych pieniędzy na niejasnych zasadach użyto zamkniętej technologii. Odpowiedź opublikowana w raporcie wspomina również o “szyfrowaniu”, mimo że jest to określenie wprowadzające w błąd, ponieważ dane nie zostały zaszyfrowane, a jedynie dodatkowo skompresowane czy też zakodowane.
Roszczenia firmy PELock
O ile samo ZETO Koszalin (twórca rozwiązania) ani PWPW (zamawiający) nie robiły problemów w związku z publikacją użytkownika v3l0c1r4pt0r, niedawno został on zablokowany przez firmę PELock w ramach DMCA (web archive).
Are you the copyright owner or authorized to act on the copyright owner’s behalf? (Czy jesteś właścicielem praw autorskich lub jego autoryzowanym przedstawicielem? – przyp. red.)
Yes
Please provide a detailed description of the original copyrighted work that has allegedly been infringed. If possible, include a URL to where it is posted online. (Proszę przedstawić dokładny opis oryginalnej pracy, względem której złamano prawa autorskie. Jeżeli to możliwe, proszę dołączyć adres URL pod którym pracę opublikowano – przyp. red.)
https://www.pelock.com/products/aztec-decoder (english product page)
http://www.dekoderaztec.pl/ (main polish site)
What files should be taken down? Please provide URLs for each file, or if the entire repository, the repository’s URL (Które pliki powinny zostać zablokowane? Proszę podać adres URL do każdego pliku z osobna lub do całego repozytorium – przyp. red):
Z informacji podawanych przez firmę PELock LLC wynika, że odtworzyła ona algorytm do dekodowania informacji zawartych w dowodach rejestracyjnych w efekcie samodzielnych analiz. Następnie zaczęła sprzedawać usługę odczytywania danych. Podstawowym sposobem użycia usługi jest “Web API” z abonamentem, którego miesięczny koszt zaczyna się od kilkuset dolarów.

Strona produktowa dekodera firmy PELock

Fragment cennika opłat za korzystanie z uslug firmy PELock
Użytkownik GitHuba o nicku dex4er, zdenerwowany całym zajściem, opublikował alternatywną implementację (web archive) używającą biblioteki UCL, ale również została ona zablokowana przez PELock LLC (web archive).
O ile można domniemywać, że użytkownik v3l0c1r4pt0 naruszył jakieś prawa firmy PELock LLC, analizując ich produkt metodami inżynierii wstecznej (co samo w sobie nie jest nielegalne), o tyle drugie repozytorium zawierało jedynie przykładowy kod wywołujący jedną funkcję z biblioteki na licencji GPL. Historia wspomnianej biblioteki sięga 1996 roku i co więcej, jest ona częścią linuksowych dystrybucji Debian i Ubuntu (w ramach paczki libucl-dev).
/* drpdecompress -- Dowod Rejestracyjny Pojazdu - decompression Copyright (c) 2018 Piotr Roszatycki <[email protected]> This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. */ #include <stdio.h> #include <stdlib.h> #include <ucl/ucl.h> #define MAX_BUFFER 10240 int main () { unsigned char input[MAX_BUFFER], output[MAX_BUFFER]; ucl_uint sizein, sizeout; if (!(sizein = fread(input, 1, sizeof input, stdin))) { fprintf(stderr, "Cannot read file\n"); exit(1); } ucl_nrv2e_decompress_8(input + 4, sizein - 4, output, &sizeout, NULL); if (!(fwrite(output, 1, sizeout, stdout))) { fprintf(stderr, "Cannot write file\n"); exit(1); } return 0; }
Kod, wobec którego właściciel firmy PELock LLC zgłosił DMCA
Nie jest trudno stwierdzić, że zamieszczony powyżej kod jest trywialny, a biblioteka UCL raczej nie została opracowana ani przez PWPW, ani przez firmę PELock LLC.
Komentarz prawnika
Nie mogę ocenić konkretnej implementacji bez znajomości jej kodu. Ale generalnie, jeśli bibliotekę rozpowszechnianą na GNU GPL wywołujemy we własnym programie, to cały program powinien być objęty tą licencją. Oznacza to w skrócie, że nie mamy obowiązku go rozpowszechniać, ale jeśli to zrobimy, to tylko w oparciu o GPL, bez opłat licencyjnych i z zapewnieniem dostępu do kodu źródłowego. Naruszenie tej zasady powoduje utratę prawa do korzystania z danej biblioteki.
– Bohdan Widła, radca prawny specjalizujący się w prawie IT i nowych technologii
Stanowiska organizacji powiązanych ze sprawą
ZETO Koszalin udzieliło nam następującej odpowiedzi:
Szanowni Państwo,
w odpowiedzi na zadane pytania informujemy, że oprogramowanie (biblioteka DLL) służące dekodowaniu kodów 2D, zostało opracowane przez nas w roku 2004 na potrzeby Klienta naszej firmy.
Zasady udostępniania oprogramowania innym podmiotom, objęte są klauzulą poufności i zgodnie z nią nie jesteśmy w stanie udzielić Państwu szczegółowej informacji na zadane pytania.
Przedstawiciel firmy PELock zgodził się odpowiedzieć nam na kilka zadanych pytań:
Skąd firma PELock posiada wiedzę o sposobie kodowania danych w dowodach rejestracyjnych, skoro te informacje nie były publiczne?
Nasza firma od lat specjalizuje się w kryptografii, kompresji oraz analizie danych. Tworzymy specjalistyczne oprogramowanie szyfrujące:
https://www.pelock.com/pl/produkty/pelock
oraz wykonujemy audyty bezpieczeństwa dla firm i agencji rządowych na całym świecie. Byłem również waszym gościem:
https://zaufanatrzeciastrona.pl/post/jak-napisac-ciekawe-crackme-na-ctf-instrukcja-krok-po-kroku/
Co do formatu danych, to wykonaliśmy szereg badań, dziesiątki testów i prac nad formatem kodowania danych. Na ich podstawie byliśmy w stanie stwierdzić, jakiego rodzaju algorytmy zostały użyte do kodowania danych. Proces ten zajął nam kilka tygodni pracy, dzięki czemu byliśmy w stanie stworzyć odpowiednie biblioteki dekodujące i na ich bazie utworzyć całą infrastrukturę, dodając do naszej oferty binarne wersje bibliotek (DLL), wersje z kodami źródłowymi oraz usługę WebAPI wraz z rozpoznawaniem obrazów bezpośrednio ze zdjęć kodów AZTEC 2D (z czym do dzisiaj nie radzą sobie darmowe biblioteki open source jak np. ZXing), stworzone zostały także implementacje w takich językach programowania jak Java, Delphi / Pascal, Visual Basic / VBA, C/C++, C#, PHP, Python i Ruby:
https://www.pelock.com/pl/produkty/dekoder-aztec
Cały proces zajął nam kilka lat ciężkiej pracy i pozwolił zaoferować rozwiązania programistyczne, których nie dostarczała w tym czasie żadna inna firma.
Czy firma PELock posiada jakieś dowody na to, że implementacja programu „delz” (https://github.com/v3l0c1r4pt0r/delz) była bazowana na Państwa produkcie, a nie na implementacji algorytmu NRV2E opublikowanej 20 lipca 2004 roku przez Markusa F.X.J. Oberhumera? Skoro użytkownik „v3l0c1r4pt0r” dokonał inżynierii wstecznej Państwa produktu, to czy posiadają Państwo dowód sprzedaży lub jakąkolwiek inną umowę prawną z tym użytkownikiem?
Charakterystyczne cechy skompilowanego kodu i odtworzonych źródeł pozwoliły nam domniemywać, że do stworzenia tej kopii została wykorzystana nasza biblioteka, która wpadła w niepowołane ręce. Pan Grzegorz (imię zmienione – przyp. red.) czyli „v3l0c1r4pt0r”, sam przyznał, że dokonał dekompilacji biblioteki i nawet nie wie skąd ją wziął ani czyją była własnością:
Tym stwierdzeniem Pan Grzegorz jasno stwierdził, że nie analizował formatu danych, tylko zdekompilował jakąś „nieznaną” bibliotekę. Pan Grzegorz nigdy nie był naszym klientem.
Czy firma PELock jest w stanie uzasadnić zablokowanie repozytorium programu „drpdecompress” (https://github.com/dex4er/drpdecompress) poprzez DMCA? W naszej opinii, zamieszczony tam kod był trywialny i nie mógł naruszać niczyich praw autorskich.
Droga jaka doprowadziła do opublikowania tego kodu prowadziła przez analizę naszej biblioteki, a nie analizę faktycznego sposobu kodowania danych, uważamy, że to podchodzi pod tzw. derivative work (https://h2o.law.harvard.edu/collages/44648 punkt 2) i na tej podstawie zostało wysłane zgłoszenie.
Chciałbym dodać, że nigdy nie mieliśmy zamiaru nikogo ciągać po sądach, jednak uważamy, że każdy ma prawo do ochrony swoich interesów i postanowiliśmy z tego skorzystać na na tyle, na ile jest to możliwe i realne do wykonania.

PWPW w zeszły czwartek odpowiedziała, że wkrótce udzieli nam odpowiedzi, jednak nie zdążyła tego zrobić przed publikacją artykułu.
Uwolnić dowody rejestracyjne!
Ponieważ cała sytuacja jest niesamowicie groteskowa, postanowiliśmy wziąć sprawę w swoje ręce i stworzyć pierwszą otwartą implementację skanera, która zrealizuje cały proces od początku do końca.
Postanowiliśmy bazować na androidowej aplikacji Zxing Barcode Scanner, która jest jedną z najbardziej rozwiniętych otwartoźródłowych implementacji skanera różnych kodów 2D. Okazało się jednak, że aplikacja nie radzi sobie z detekcją tak dużych kodów AZTEC, jak te zawarte w dowodach rejestracyjnych.
Niezwykle pomocne w rozwiązywaniu tego problemu okazały się dyskusje pod zgłoszeniami problemów na portalu Google Code, który wówczas hostował projekt wspomnianej aplikacji. Programista Mariusz Dąbrowski umieścił tam swoją implementację wykrywacza krawędzi. Autor stwierdził, że jego przeróbka pozytywnie wpływa na możliwość skanowania dużych kodów. Choć nie była ona idealna, to faktycznie stanowiła krok milowy – aplikacja zaczęła skanować większe “azteki” i robiła to poprawnie, choć z pewnym trudem.
Kod Mariusza zintegrowaliśmy w aplikacji i przeprowadziliśmy kilka dostrojeń polegających m.in. na poprawieniu współczynników w detektorze krawędzi oraz dostosowaniu algorytmu wykrywania prostokątów. Skoro już “nauczyliśmy” aplikację skanować duże kody AZTEC, co wcześniej było problemem, teraz przyszedł czas na zajęcie się dalszymi warstwami kodowania. Dzięki kilku eksperymentom przeprowadzonym metodą „prób i błędów” udało się ustalić ich kolejność oraz znaczenie:
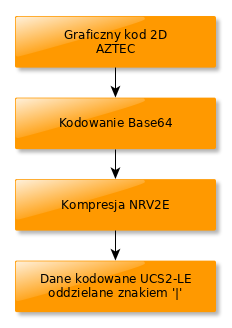
Finalny schemat warstw kodowania w polskich dowodach rejestracyjnych
Algorytm Base64 jest dobrze znany i z jego zdekodowaniem nie było większych problemów. Przejście przez kolejną warstwę umożliwił natomiast Bartosz Soja, który opublikował swoją implementację kompresji NRV2E (web archive) w języku C#. Jego implementacja w całości bazuje na otwartej bibliotece UCL autorstwa Markusa F.X.J. Oberhumera, wydanej na licencji GPL. Po poświęceniu kilkunastu minut na przeportowanie kodu z języka C# do Javy, a później kilku godzin na zintegrowanie tego wszystkiego w aplikacji… stało się. Powstał pierwszy otwarty skaner dowodów rejestracyjnych.
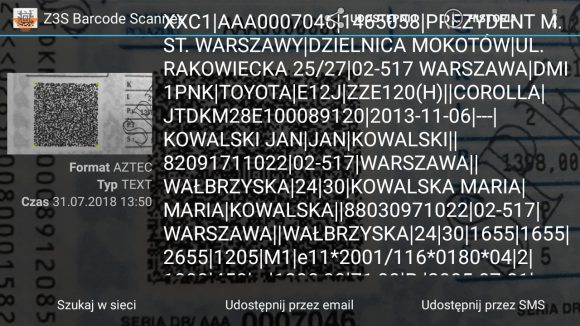
Dowód rejestracyjny zdekodowany w przerobionej aplikacji Barcode Scanner
Kod źródłowy przerobionej aplikacji udostępniamy za darmo na portalu GitHub. Możecie użyć go, aby stworzyć własne rozwiązania wykorzystujące informacje z dowodów rejestracyjnych. Aplikację gotową do przetestowania udostępniamy natomiast za pośrednictwem Google Play.
Aplikacja może działać lepiej lub gorzej, zależnie od używanego smartfona oraz jakości wbudowanego w nim aparatu. Zainteresowanych programistów zachęcamy do dalszego rozwijania projektu (można np. zaimplementować transformację perspektywy w oparciu o siatkę odniesienia, która obecnie nie jest w ogóle używana).
Podsumowanie
Sprawa AZTECów w naszych dowodach niewątpliwie wprowadza wiele kontrowersji. Cała idea przyświecająca powstaniu różnych standardów kodów 2D polega na zwiększaniu dostępności określonych informacji, interoperacyjności systemów i w związku z tym redukcji zbędnej “papierologii”. Gdyby tego typu rozwiązania były tworzone zgodnie ze sztuką programistyczną, odpowiednia specyfikacja powinna zostać upubliczniona w dniu wydania pierwszego dowodu rejestracyjnego wyposażonego w symbol 2D. Tak się jednak nie stało, a wręcz stworzono bariery, które skutecznie powstrzymały wiele instytucji przed korzystaniem z tego udogodnienia.
Mamy nadzieję, że opublikowany przez nas kod okaże się przydatny. Być może pojawią się osoby zainteresowane dalszym rozwojem projektu w charakterze open source (my tego raczej nie planujemy). Oby dzięki temu powstały nowe rozwiązania, które ułatwią życie Polaków podczas wizyty u ubezpieczyciela, na stacji kontroli pojazdów czy podczas kontroli drogowej.



Komentarze
Szanuję!
Za walkę z biurokratyczną patologią i śmierdzącymi przetargami ;)
Wspaniała robota, serdecznie gratulacje i wielkie dzięki!
Drodzy autorzy, część firm ubezpieczeniowych już korzysta z takich rozwiązań (pierwsze zaczęły ok 3-4 lat temu), lecz w większości przypadków są to aplikacje tak utrudnione do używania, że szybciej idzie wprowadzić te dane ręcznie do programu :) Dodatkowo kod Aztec zawiera dane jedynie właściciela z pierwszej strony dowodu rejestracyjnego, tak więc jest to kolejny jego słaby punkt.
Swego czasu firma Warta rozdawała agentom kamerki internetowe do skanowania tych kodów, lecz ich rozdzielczość była średniej jakości i różnie z tym wychodziło. Wg mnie, na chwilę obecną najlepiej ze sprawą poradziły sobie firmy Hestia i Compensa, które posiadają skanery w postaci aplikacji na smartfony i z automatu agentowi zaczytują się dane, są to jedyne firmy z których jestem w stanie korzystać z oferowanego programu do zaczytywania kodów AZTEC i nie oszaleć (a współpracujemy z ponad 20 firmami ubezpieczeniowymi).
Firmę łamiącą GPL najlepiej zgłosić do gpl-violations.org
„Wizja
Chcemy, żeby Polska była państwem innowacyjnym i przyjaznym, w którym interakcje między państwem, obywatelami i przedsiębiorcami są proste.
Misja
Celem działania Ministerstwa Cyfryzacji jest doprowadzenie do tego, żeby dzięki cyfryzacji ludziom żyło się lepiej.”
No. To tyle tytułem komentarza :D
Popatrz tylko na daty. To kolejny przekręt kolesiów poprzedniej ekipy PO/PSL.
Skoro to jest przekręt poprzedniej ekipy, to dlaczego obecna ekipa nie chce tego odkręcić tylko każda instytucja zapytana zasłania sie tym i owym i nadal nie umożliwia otwartego dostepu do tego kodu? Wynika z tego, ze obecna jest tak samo „dobra” jak nie lepsza. Gdyby chcieli zrobić dobrze, to by dawno zrobili. Od 2015 mieli trochę czasu i co?
Spójrz na daty, 2004 rok, wtedy rządzili inni kolesie – SLD. Być może coś tam jeszcze mieszali swoimi paluszkami chłopcy PSL, ale ta partia opuściła koalicję w 2003 roku. Ot, taka prehistoria ale nie wszystko co było przed 2015 to PO/PSL…
Brawo! Zarabianie tego ZETO na utajnieniu czegoś co było wymagane ustawą jest zwyczajnie nieuczciwe.
Świetna robota, ale… tworzycie kolejny problem prawny, który potencjalnie może mocno utrudnić wykorzystanie tej wersji. Widzę, że Z3SBarcodeScanner jest wydany na licencji Apache 2.0, natomiast implementacja Bartosza na GPL 3, podobnie jak na GPL wydana była biblioteka na której bazuje. Problem w tym, że licencja GPL… nie pozwala na zmianę licencji i firma PELock może dla odmiany żądać usunięcia nowych implementacji z powodu – o ironio – naruszenia licencji GPL.
Dziękujemy za to spostrzeżenie, omyłkowo w repozytorium dołączona była licencja Apache 2.0 pochodząca z oryginalnego projektu zxing. Ze względu na obecność kodu na GPL 3 dokonaliśmy zmiany licencji projektu:
https://github.com/AnonimowiAnalitycy/Z3SBarcodeScanner/commit/0e110052961985fc190f457b0abf88143f3ebdc9
Licencja Apache 2.0 jest kompatybilna z GPL 3 jeżeli projekt jest licencjonowany na GPL 3 i zawiera elementy na licencji Apache 2.0: https://www.apache.org/licenses/GPL-compatibility.html
W zasadzie dobrze ale… czy w ty momencie nie zmieniliście licencji dla całości projektu, w tym oryginalnego skanera, który był na licencji Apache? Na to też jest potrzebna zgoda autora skanera.
IMVHO najczystsze rozwiązanie to stworzenie samej biblioteki na licencji GPL w języku pozwalającym na integrację ze skanerem, a następnie podesłanie patcha do upstramu integrującego tę bibliotekę.
BTW Ciekawym tropem wydaje się sprawdzenie, czy firma PELock faktycznie posiada prawa do nrv2e – wygląda, że autor nrv http://www.oberhumer.com/products/nrv/ jest jeden i udostępniał kod albo na GPL, albo na licencji komercyjnej. Skoro tak, PELock musi albo licenjonować swój soft na GPL (przypadek pierwszy), albo… mieć wykupioną stosowną licencję. Mail do firmy Oberhumer ze stosownym może mieć interesujące skutki. ;-)
Oryginalny kod zxinga nadal jest na licencji Apache 2.0, ale ponieważ zawarliśmy tam fragmenty kodu na GPL 3 to cały projekt musi być obsługiwany tak, jakby był na GPL 3. Jeżeli usuniesz/przepiszesz GPLowe modyfikacje to znowu możesz używać na zasadach Apache 2.0 ;)
Wow! Gratuluję wytrwałości i duży szacunek za postawę
Repozytorium https://github.com/dex4er/drpdecompress jest odblokowane, bo poszedł DMCA counter notice. Musiałem czekać 2 tygodnie, no ale jak widać, poza tym problemów nie było.
PELock bredzi, że ten kod był „derivative works”. Teoretycznie za fałszywe zgłoszenie DMCA grozi odpowiedzialność karna, to tak przy okazji.
Dziękuję za zaangażowanie w temacie AZTECA.
Fajnie, szanuję za artykuł i pracę nad oprogramowaniem, ale skoro open source dlaczego tego nie ma na fdroidzie
Przy okazji, skodziłem też wersję Javascript https://github.com/dex4er/js-nrv2e-decompress co by można było zrobić jakiś dekoder tylko na przeglądarkę, albo komuś chciało się reimplementować na inny język. Zawiera komentarze, gdy próbowałem jeszcze analizy danych, zanim upewniłem się, że chodzi właśnie o algorytm NRV2E
Nieładnie tak nadużywać DMCA. Otwarłem im pull requesta, ciekawe czy go zdejmą.
https://github.com/PELock/Dekoder-AZTEC-2D-Python/pull/1
trash, strasznie mi przykro, ale nie sprawdziłem czy mój kod działa pod FreeBSD :( jakby co, to przymuję pull requesty.
Brakuje jeszcze objaśnienia znaczenia poszczególnych pól, jak w https://bitbucket.org/bsoja/polish-vehicle-registration-certificate-decoder/src/fcadf57f5183a4a35f66892ebecb5566f5e7c758/src/VehicleRegistrationInfoParser.cs?at=master&fileviewer=file-view-default
Spokojnie, zaraz się rozkręci: https://github.com/dex4er/js-polish-vehicle-registration-certificate-decoder
Może pull request? ;)
Wspaniała robota proszę Państwa! Sam kilka lat temu walczyłem z tym problemem ale musiałem się poddać. Wam się udało. Gratuluję! I dziękuję!
Co do rozpoznawania kodów: istnieje aplikacja na androida która rozczytuje te kody i zawiera zmodyfikowaną bibliotekę ZXing. Wystarczy wstukać frazę „pl.mobiltek.carhistory.CarHistoryAndroid apkmonk” w google. Po dekompilacji tej biblioteki pokazuje się ładny kod Javy, który być może można wykorzystać w usprawnieniu rozpoznawania kodów Aztec z biblioteki ZXing
Fraza klucz: „po dekompilacji”. Nikogo nie zachęcam do takich działań, ponieważ konkretne rozwiązania usprawniające skaner mogą być odrębną własnością intelektualną. Do aplikacji prezentowanej w artykule doszliśmy wykorzystując wyłącznie wolne oprogramowanie, cenne uwagi nieznajomych programistów oraz własną inwencję (btw. osobiście nie jestem wielkim fanem GPLa, ale to nie istotne).
Definiując „nieznajomych programistów” – tak jak podano w artykule, Mariusz Dąbrowski kiedyś wrzucił pomysł usprawnienia detekcji krawędzi wraz z kawałkiem kodu na grupie dyskusyjnej ZXinga, Bartosz Soja wykonał implementację NRV2E w C#, która bazowała na otwartym libucl i łatwo ją było później przeportować do Javy.
Zachęcamy do dalszego forkowania projektu i jego rozwijania, albo wysyłania pull requestów.
Remark: Żadna z w/w osób nie jest w żaden sposób powiązana z projektem aplikacji, ani redakcją z3s.
Pozwoliłem sobie napisać do autora algorytmu:
Turns out that in Poland vehicle registration system is using your GNU licensed algorithm to encode information within IR Codes.
2D IR codes of are compressed with your UCL algorithm. Which was proven by this repository -> https://github.com/dex4er/drpdecompress/blob/master/drpdecompress.c#L75
Also there’s at least one Polish company named 'PElock’ which sells products based on your algorithms -> https://www.pelock.com/pl/produkty/dekoder-aztec
They even filed DMCA action against people who discovered it first -> here’s the repository blocked by github -> https://github.com/v3l0c1r4pt0r/delz
Just thought you might be interested in this whole ordeal.
If you want more info feel free to contact me, also check this site -> https://zaufanatrzeciastrona.pl/post/historia-o-dowodach-rejestracyjnych-dekoderze-aztec-i-pewnym-monopolu/
Przykro to mówić, ale dekodowanie kodów AZTEC 2D jest chyba we wszystkich aplikacjach ubezpieczeniowych, diagnostycznych i bankowych OD LAT, jeśli dla kogoś w 2018 roku to nowość – to przegapiliście dobre X lat w tym temacie.
Nie uważasz za dziwne, że PWPW próbuje pobierać pieniądze (i to w formie abonamentu!) za dostęp do czegoś, co powinno być informacją publiczną?
Przykro mi to stwierdzić ale na 16 które widziałem, tylko 7 ma wczytywanie z kodu AZTEC.
Parę lat temu pracowałem przy pewnym znanym serwisie ogłoszeniowym i miałem pomysł na ułatwienie wystawiania ogłoszeń przez skanowanie tego kodu właśnie. Co ciekawe, nie miałem żadnych problemów z PWPW kiedy pytałem ich o taką możliwość. Od razu skierowali mnie do firmy ZETO w Koszalinie aby ta bezpłatnie udostępniła nam tę bibliotekę. Finalnie pomysł nie został wdrożony ale faktem jest, że samo udostępnienie biblioteki nie było problemem.
Najwidoczniej kliknąłem w niewłaściwe 'Odpowiedz’. Chciałem odpowiedzieć na odpowiedź powyżej.
Po prostu wow
Brawo!
A gdyby tak mieć znak `|` w imieniu/nazwisku/adresie? :D
Świetna robota! :)
Super że ruszyliście temat!
W przypadku skanowania jednego dowodu dostaję:
„Error: java.lang.ArrayIndexOutOfBoundsException:
length=1037; index=-2147482612” (ale np Yanosik lub Atena Aztec Reader poprawnie czyta).
a drugi nowszy rozpoznawany jest bez problemu :)
Super apka, gratulacje.
2 moje dowody wyświetla poprawnie, niestety 3-ci daje komunikat:
„Error: java.lang.ArrayIndexOutOfBoundsException:
length=935; index=-2147482714”
Możliwe że macie dowody rejestracyjne w „starym formacie”. Czy możecie zrobić wyraźne zdjęcie kodu i przesłać na adam (małpa) zaufanatrzeciastrona (kropka) pl? Postaramy się poprawić aplikację.
Z tego co udało mi się ustalić to jest to problem dekompresora, nie wie czasami kiedy ma się zatrzymać, przez co mimo iż odczytał już wszystkie dane z dowodu, próbuje czytać dalej. Myślę, że nie jest to duży problem i wkrótce zostanie to naprawione, czy to przeze mnie czy innego developera.
Będę wdzięczny za przykładowy base64 który powoduje błąd dekompesji (na priv raczej, bo tam są jakieś dane).
Nie wiem czy nadal występuje ten błąd, ale problem tkwi w dekodowaniu Base64, a nie w NRV2E. Poradziłem sobie z tym problemem małym hackiem, ale ponieważ w zasadzie nie wiem co ten mój hack naprawia, że dekompresja nie wyrzuca wyjątku, to trudno mi się wypowiadać. Moje działanie było intuicyjne. Domyśliłem się, ze problemem jest wiele implementacji dekodowania Base64, nie zawsze ze sobą kompatybilne (różny padding w różnych implementacjach), więc eksperymentowałem ze skracaniem tablicy bajtów na wyjściu var bytes = DecoderBase64(data). Przyjąłem, ze jeśli bytes.Length % 4 == 2, to skracam tablicę bytes o jeden bajt i to dopiero wysyłam do dekompresji. Nie mam dużej ilości stringów z dowodów rej. więc nie wypowiem się czy ten hack działa zawsze, czy tylko w jednym moim przypadku.
Wiem że Warta korzystała z skanerów tego kodu, mieli to zaimplementowane w swojej aplikacji do wystawiania polis jeszcze w 2013 lub 2014 eoku, cała aplikacja opierała się na bazie accessa :P
Jest już kila takich aplikacji w Play, np.:
https://play.google.com/store/apps/details?id=com.apreel.aztecscanner
https://play.google.com/store/apps/details?id=pl.atena.aztecreader
Ciekawe jak ich autorzy dekodują te kody. Czy sami do tego doszli?
Czy ktoś mi powie jakim cudem bezpłatne aplikacje z repozytorium Google Play mogą przeczytać dane wrażliwe, takie jak imię i nazwisko, adres, PESEL?
A to tylko płatne mają móc? :)
No skandal jak darmowa aplikacja aparat fotograficzny może sobie ot tak bez problemu zrobić zdjęcie dowodu osobistego? Wyłączyć, natychmiast wyłączyć!
Kilka lat temu (2?) używałem autorentgen – skanował kod bezproblemowo.
Piękne działania! Z tymi dowodami jest podobnie jak z radiowymi kluczami do samochodu, przynajmniej niektórymi: algorytm, którego bezpieczeństwo opiera się na jego utajnieniu. Tyle, że tam akurat jest szyfracja, chociaż bardzo słaba.
Mam jedną małą uwagę krytyczną. Ogłosiliście, że gotowy program jest dostępny przez Google Play. Ja ze względów bezpieczeństwa nie używam tego WWW (jest tam mnóstwo oprogramowania spamującego, nie chcę też żeby były zbierane moje dane). Czułbym się bezpieczniej mogąc ściągnąć program bezpośrednio od Was.
Plik APK jest też dostępny na stronie www apkpure.
Znam Bartka od lat, pracował dla nas nad kilkoma projektami, w relacjach biznesowych bezproblemowa osoba i naprawdę zdolna, a to, że potrafi być nieprzyjemny? Nie dziwi mnie to, widziałem niektóre wypowiedzi na wykopie skierowane do niego, niejednokrotnie jakieś chamskie wyzywanie całą gamą inwektyw, każdy by się wnerwił.
@Markoni, kiedyś zwykło się określać takich typów jako „kozak w necie…”.
Testowałem waszą appkę na 3 dowodach z firmy, żadnego nie rozpoznaje. Kiedy będzie jakaś aktualizacja?
Nie wiem skąd macie takie rewelacje. ITS oferuje czytnik kodów 2D +oprogramowanie dekodujące za 1450zł http://www.patronat.pl/programy/2D%20Gryphon%20D432_ulotkam.pdf. I oferuje to już od ładnych kilku lat. Używałem tego oprogramowania. Z porządnym czytnikiem działa super. Mało tego jest w pełni zintegrowane z ich programem. I pewnie działa na sporej liczbie Stacji Kontroli Pojazdów :)
A jak uzyć Waszej poprawionej biblioteki zxing w projekcie Cordova?
Udało mi się nałożyć patche koderów Z3S na plugin Cordovy. W połączeniu z dekompresorem NRV2E i parserem formatu dowodów udało mi się złożyć z tego apllikację: https://play.google.com/store/apps/details?id=com.github.dex4er.dekoder_dowodu_rejestracyjnego Aplikacja jest oczywiście na licencji GPL 2.0 z dostępnymi źródłami i obszerną instrukcją dla deweloperów. Mam nadzieję, że zachęci to do dalszych eksperymentów i powstaną jakieś użyteczne aplikacje w ramach przedsięwzięć open government data.
Dlatego właśnie każde oprogramowanie finansowane z budżetu państwa powinno zostać upublicznione z wolną licencją.
Polecam podpisać otwarty list (akcja organizowana przez Free Software Fundation):
https://publiccode.eu/
PWPW stworzyła też rozwiązanie on-line do rezerwowania egzaminów na prawo jazdy (info-Car). Wygląda na to, że świetnie na nim zarabia kosztem kandydatów na kierowców.
Prowizja za każdą płatność on-line (niezależnie od kwoty): 2 PLN. Niezależnie od tego czy płacimy 30 PLN za egzamin teoretyczny, czy 140 PLN za praktyczny. Dodatkowo nie da się wykonać jednej wpłaty, czyli za 2 egzaminy 4 PLN prowizji.
Alternatywą jest wpłata na konto WORD (darmowa, trwająca nieco dłużej), ale tylko 2 WORDy w całym kraju eksportują swoje salda do programu PWPW…
Oczywiście można by wpłacić na konto i umówić egzamin bezpośrednio w WORD, ale w tej formule np. WORD Wrocław umożliwia umówienie terminu jedynie osobiście w ich siedzibie – bilet MPK w jedną stronę: 3,40 PLN. Ręce opadają.
https://github.com/github/dmca/blob/master/2018/2018-08-06-PWPW.md
Dostali jeszcze jedno DMCA, tym razem od samego PWPW
No to płać setki dolarów miesięcznie za to
Ponieważ od kilku tygodni pracuję nad aplikacją desktopową odczytującą kody Aztec z dowodów rejestracyjnych, więc siłą rzeczy musiałem trafić na ten artykuł, kiedy nastąpiły trudności ze zdekodowaniem danych wyjściowych z kodu Aztec. Robię to w c# i korzystam oczywiście z nugetowej wersji biblioteki PolishVehicleRegistationCertificateDecoder pana Bartosza Soi. Do wyprostowania obrazka stosuję openCV Warp. Nieważne… Co do tej biblioteki o StrasznieDługiejNazwie, to robi psikusa przy niektórych stringach, które można odczytać z niektórych dowodów rejestracyjnych, a ponieważ apka Z3S również korzysta z tejże biblioteki, jedynie ją portując (chociaż akurat Base64 mają zaimplementowane z innego źródła), to ten sam psikus można zobaczyć posługując się tą aplikacją.
Po moich wielogodzinnych badaniach doszedłem do wniosku, ze problem tkwi w dekodowaniu Base64 i braku jednego standardu w implementacji Base64. Ponieważ zależało mi, aby uzyskać jakikolwiek wynik (poza komunikatem o błędzie) więc posłużyłem się małym hackiem, który spowodował, że ta biblioteka dekompresuje te stringi, których wcześniej nie odczytywała.
Czy udało się komuś skodzić skrypt JS do pliku html? Od trzech dni się meczę i nic. Interpreter nie wie co to Buffor (const binInput: Buffer = Buffer.from(b64Input, 'base64′)).
A może ktoś skorzystał z tego? ;-)
https://decoder.carq.pl/api/docs
lub jeszcze szerszej wersji:
https://carq.pl/api/v2/docs/index.html?fbclid=IwAR1CekgfuI9vNko908fK9ptSN3IvVA6FgNgKYr8cK4-qFP4-2N2rQWv7j8E#api-Logowanie-rootGet
Korzystaliśmy i jest masa problemów, co jakiś czas serwer nie odpowiada lub odpowiada błędami mimo poprawnej autoryzacji, koniec końców stanęło na rozwiązaniu firmy Pelock.