
Trzymanie kopii bezpieczeństwa prywatnych czy firmowych danych w chmurze jest kuszące – chmura jest odporniejsza na pożary czy kradzieże sprzętu. Rodzi jednak pewne dodatkowe ryzyka – które zredukujemy, budując w niej własne rozwiązanie.
Artykuł jest częścią cyklu poświęconego usługom chmurowym Aruba Cloud. Wcześniej opisaliśmy, jak backup w chmurze może uratować czas (lub pracę) informatyka oraz jak zapewnić dostępność usług. Dzisiaj zbudujemy własnego Dropboksa.
Internetowe rozwiązania wykorzystywane do udostępniania plików pojawiły na długo przed spopularyzowaniem pojęcia chmury plikowej. Możliwość przechowywania naszych danych w modelu, dzięki któremu będziemy mieli do nich dostęp z każdego miejsca na świecie, niezależnie od platformy sprzętowej czy programowej, jest niewątpliwie bardzo wygodna. Sama kwestia przechowywania danych w ramach zasobów innych podmiotów budzi wiele kontrowersji, wywołując przy tym sporo burzliwych dyskusji. W kontekście bezpieczeństwa wiele zależy od tego, co tak naprawdę chcemy przechowywać w chmurze i w jaki sposób zapewniać (zabezpieczać) dostęp do określonych zasobów.
Możemy w całości powierzyć nasze zasoby plikowe zewnętrznemu dostawcy i skorzystać z gotowego rozwiązania takiego jak Dropbox, Google Drive czy OneDrive. Poza największymi graczami dostępnych jest jeszcze wiele innych usług, które starają się konkurować z tymi najbardziej popularnymi atrakcyjną ceną czy dodatkowymi opcjami ,,premium”.
Organizacje potrzebujące przetwarzać bardzo duże ilości danych, dla których prognoza ich przyrostu jest ciężka do przewidzenia, najbardziej doceniają model zasobów dyskowych określanych jako ,,object storage”. Dzięki obiektowemu podejściu do obsługi danych możliwe jest stworzenie swoistej warstwy abstrakcji, w ramach której usługodawca izoluje całe zaplecze systemu storage od platformy dostępu do danych wykorzystywanej przez usługobiorcę.
W kolejnym artykule cyklu poświęconego rozwiązaniom Aruba Cloud, w oparciu o wcześniej opisany klaster serwerów Apache, prezentujemy scenariusz wdrożenia własnej chmury plikowej umożliwiającej przechowywanie danych w oparciu o usługę Aruba Cloud Object Storage. Poniżej znajdziecie film, pokazujący cały proces konfiguracji, a pod nim wersję tekstowo – obrazkową instrukcji.
Chmura plikowa ,,następnej generacji”
Nextcloud to otwartoźródłowa platforma pozwalająca na stworzenie własnej ,,chmury plikowej” w modelu ,,self-hosting”. Może ona działać w oparciu o różnego rodzaju zasoby. W zależności od potrzeb i możliwości może to być lokalny serwer i storage, system dzierżawiony (dedykowany lub VPS) oraz instancja chmurowa. Sam proces instalacji i wdrożenia nie należy do skomplikowanych, mając jednak na uwadze główne przeznaczenie systemu, należy we właściwy sposób dobrać zaplecze pod storage wykorzystywany do składowania plików. Nextcloud może wykorzystać zasoby dyskowe, w jakie jest wyposażony serwer lub korzystać z tzw. magazynów zewnętrznych: systemów NAS (CIFS/SMB), WebDAV, SFTP czy Amazon S3. Przedstawiana przez nas implementacja skupia się na ostatnim z wymienionych protokołów, czyli Amazon Simple Storage Service.
Dzięki wykorzystaniu rozwiązania w postaci Object Storage już na samym etapie wdrożenia nie musimy planować i rezerwować rozmiaru przestrzeni dyskowej. Usługa Aruba Cloud Object Storage jest dostarczana w ramach kilku planów taryfowych, przy czym pierwszy z nich to tak naprawdę model kosztowy ,,Pay-per-use”. Dzięki takiemu rozwiązaniu opłaty (naliczane godzinowo) ponosimy za każde 10 GB danych składowanych w naszych koszykach (bucketach).
Wielkość docelowej przestrzeni w usłudze jest praktycznie nieograniczona, same dane są składowane nadmiarowo (replikacja na trzech oddzielnych urządzeniach storage) i przechowywane zawsze w tym samym obszarze geograficznym.
Cloud Object Storage – konfiguracja
Skonfigurowanie konta usługi Cloud Object Storage zajmuje dosłownie kilkanaście sekund. Wymagane jest aktywne konto Aruba Cloud oraz środki pieniężne, jakie będą potrzebne do utrzymania tzw. ,,Konta Storage”. Po zalogowaniu do Panelu Kontrolnego Aruba Cloud przechodzimy do sekcji ,,Cloud OBJECT STORAGE:

W celu uruchomienia kreatora konfiguracji klikamy na przycisk

Podajemy nazwę ,,Konta Storage”, definiujemy bezpieczne hasło oraz wybieramy region składowania danych. Na koniec wybieramy odpowiedni plan taryfowy i zatwierdzamy wszystkie parametry, klikając na ,,UTWÓRZ KONTO OBJECT STORAGE”:

Instalacja w ramach klastra
Nextcloud zostanie przez nas wdrożony na wcześniej przygotowanym środowisku, jakie opisaliśmy w naszym poprzednim artykule. Samo rozwiązanie może być także zainstalowane od podstaw na zupełnie nowej instancji lub na lokalnym serwerze. W przypadku wyboru platformy Centos 7.x scenariusz postępowania będzie dokładnie taki sam, jak w poniższych instrukcjach. Jedyną różnicę będą w zasadzie stanowić polecenia dotyczące restartu klastra:
pcs cluster stop --all && pcs cluster start --all
Należy je po prostu zastąpić poleceniem przeładowania usługi Apache (httpd):
systemctl restart httpd
Proces wdrożenia zaczynamy od instalacji niezbędnych prerekwizytów, jaką wykonujemy na obu serwerach WEB01 i WEB02.
1. Nextcloud w najnowszej stabilnej wersji oznaczonej numerem 15 wymaga silnika PHP w wersji minimum 7.0. Nie jest ona domyślnie dostarczana wraz z systemem CentOS, dlatego najpierw niezbędne jest dodanie odpowiedniego repozytorium i przeprowadzenie deinstalacji starszych wersji pakietów:
rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm yum -y install epel-release yum-utils && yum -y remove php php-common && yum -y update
2. Następnie na obu instancjach instalujemy wymagane pakiety:
yum -y install httpd php72w php72w-dom php72w-mbstring php72w-gd php72w-pdo php72w-json php72w-xml php72w-zip php72w-curl php72w-pear php72w-intl setroubleshoot-server bzip2 php72w-mysql php-opcache php72w-pecl-redis samba-client
Baza danych
Nextcloud wspiera trzy silniki bazodanowe: SQLite, MySQL(MariaDB) i PostrgeSQL. MariaDB jest domyślnie dostarczana wraz z system CentOS 7.x, zapewniając przy tym rozsądny poziom wydajności dla instalacji średniej wielkości (od kilkudziesięciu do maksymalnie kilkuset aktywnych użytkowników Nextcloud).
Instalację MariaDB przeprowadzamy na serwerze STOR01, do którego połączenia będą realizowane przez oba nody klastra WEB01 i WEB02:
1.Pobieramy, instalujemy i konfigurujemy wymagane pakiety:
yum -y update && yum -y install mariadb-server mariadb-client systemctl enable mariadb && systemctl start mariadb
2. Zabezpieczamy instancję MariaDB korzystając z narzędzia mysql_secure_instalation:
mysql_secure_installation <enter> y <enter> New password: haslo_mysql <enter> Re-enter password: haslo_mysql <enter> y <enter> y <enter> y <enter> y <enter>
Wynik działania naszego kreatora powinien wyglądać w następujący sposób:
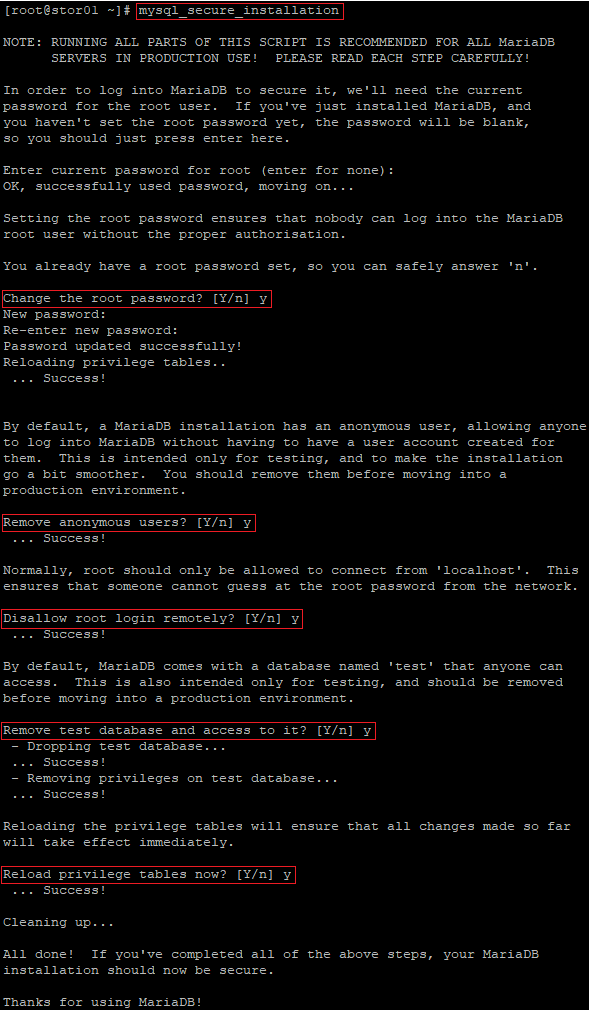
Tym samym hasło roota zostało ustawione, zablokowaliśmy możliwość zdalnego logowania na tym użytkowniku oraz usunęliśmy testową bazę danych.
3. Konfigurujemy reguły firewalld w taki sposób, aby połączenia do usługi MariaDB były możliwe tylko w sieci wewnętrznej (internal) i tylko z serwerów WEB01 i WEB01. W tym celu skorzystamy ze składni rich rules:
firewall-cmd --permanent --zone=internal --add-rich-rule='rule family=ipv4 source address=10.10.10.10/32 port port=3306 protocol=tcp accept' firewall-cmd --permanent --zone=internal --add-rich-rule='rule family=ipv4 source address=10.10.10.20/32 port port=3306 protocol=tcp accept' firewall-cmd --reload
4. Na koniec tworzymy bazę danych Nextcloud i użytkownika do niej przypisanego:
mysql -u root -phaslo_mysql CREATE DATABASE nextcloud; CREATE USER 'nextcloud'@'10.10.10.%' IDENTIFIED BY 'nextcloud_password'; GRANT ALL PRIVILEGES ON nextcloud.* TO 'nextcloud'@'10.10.10.%'; FLUSH PRIVILEGES; QUIT;
Instalacja Nextcloud
Z racji współdzielenia przestrzeni plikowej przeznaczonej dla aplikacji webowych instalację Nextcloud możemy w zasadzie przeprowadzić na dowolnej instancji klastra. Sam proces składa się z dwóch etapów:
- przygotowanie środowiska i rozpakowanie plików aplikacji Nextcloud od strony powłoki systemu operacyjnego,
- konfiguracja aplikacji przeprowadzana z poziomu przeglądarki internetowej.
Pierwszy etap rozpoczynamy od pobrania właściwego pakietu instalacyjnego Nextcloud i jego rozpakowania.
1.Przechodzimy do odpowiedniego webkatalogu (/var/www/html) i pobieramy najnowszą stabilną wersję Nextcloud:
cd /var/www/html curl -o nextcloud-15-latest.tar.bz2 https://download.nextcloud.com/server/releases/latest-15.tar.bz2 tar -xvjf nextcloud-15-latest.tar.bz2 mkdir nextcloud/data chown -R apache:apache nextcloud rm -f nextcloud-15-latest.tar.bz2
2. OPCJONALNIE: W przypadku aktywnej polityki Selinuxa należy dodatkowo ustawić właściwe konteksty na katalogach i plikach aplikacji Nextcloud – poniższe polecenia możemy wykonać z poziomu dowolnej instancji klastra:
semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/data(/.*)?' semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/config(/.*)?' semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/apps(/.*)?' semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/.htaccess' semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/.user.ini' restorecon -Rv '/var/www/html/nextcloud/'
Dodatkowo w przypadku obu instancji WEB01 i WEB02 na każdej z nich musimy pozwolić usłudze httpd na wykonywanie połączeń z bazą danych:
setsebool -P httpd_can_network_connect_db 1
3. Na koniec przeładowujemy cały klaster – proces możemy wykonać bez przerwy pracy systemu (restartując najpierw WEB01, a potem WEB02) lub w całości (parametr: –all):
pcs cluster stop --all && pcs cluster start --all
Po rozpakowaniu plików Nextcloud kreator instalacji aplikacji jest dostępny z poziomu przeglądarki. Sama aplikacja została rozpakowana do katalogu w ścieżce bezwzględnej /var/www/html/nextcloud, stąd też jej wywołanie w przeglądarce jest możliwe po wpisaniu adresu http://naszadomena.tld/nextcloud.
1. W przypadku naszego środowiska w przeglądarce wywołujemy adres URL http://web.z3s.pl/nextcloud i wprowadzamy dane niezbędne do skonfigurowania usługi:
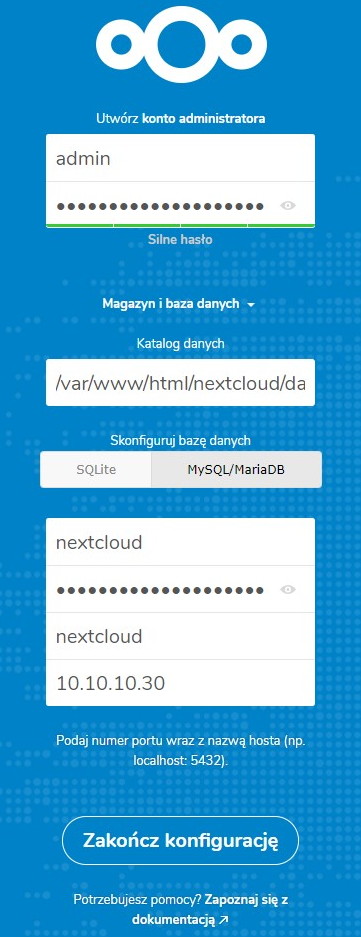
– nazwę bazy danych oraz użytkownika i hasło logowania do niej podajemy dokładnie takie jak na etapie instalacji i konfiguracji MariaDB. Po wprowadzenia wszystkich danych klikamy na przycisk

2. Proces finalizacji konfiguracji i przygotowania naszej aplikacji może potrwać od kilkudziesięciu sekund do kilku minut. Po jego zakończeniu zostaniemy od razu zalogowani na koncie wcześniej utworzonego administratora i naszym oczom ukaże się kreator pierwszego użycia:
Optymalizacja OPcache i Redis
W przypadku produkcyjnego wykorzystania Nextcloud zalecane jest włączenie mechanizmów optymalizacji silnika PHP i zapewnienia dodatkowego magazynu danych dla pamięci podręcznej (Redis NoSQL). Włączenie OPcache wymaga zainstalowania odpowiednich pakietów (co wykonaliśmy wcześniej) oraz aktywacji tego mechanizmu w pliku konfiguracyjnym /etc/php.ini. Na końcu sekcji [php] tego pliku dopisujemy poniższe linijki:
opcache.enable=1 opcache.enable_cli=1 opcache.interned_strings_buffer=8 opcache.max_accelerated_files=10000 opcache.memory_consumption=128 opcache.save_comments=1 opcache.revalidate_freq=1
Wpis w pliku konfiguracyjnym powinien przedstawiać się w następujący sposób:

Konfigurację OPcache wykonujemy na obu serwerach WEB01 i WEB02.
Następnie przechodzimy do konsoli serwera STOR01 i instalujemy serwer Redis:
yum -y install redis
Serwer ma być dostępny dla instancji WEB01 i WEB02, dlatego w pliku konfiguracyjnym /etc/redis.conf ustawiamy właściwy adres IP na jakim usługa ma nasłuchiwać:
bind 10.10.10.30
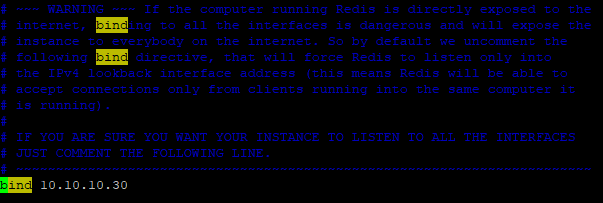
Restartujemy usługę i definiujemy odpowiednie reguły firewalld:
systemctl enable redis && systemctl start redis firewall-cmd --permanent --zone=internal --add-rich-rule='rule family=ipv4 source address=10.10.10.10/32 port port=6379 protocol=tcp accept' firewall-cmd --permanent --zone=internal --add-rich-rule='rule family=ipv4 source address=10.10.10.20/32 port port=6379 protocol=tcp accept' firewall-cmd --reload
Ponownie przechodzimy do wiersza poleceń dowolnej instancji klastra i edytujemy plik konfiguracyjny Nextcloud (/var/www/html/nextcloud/config/config.php) poprzez dopisanie następującej sekcji:
'memcache.locking' => '\OC\Memcache\Redis', 'memcache.distributed' => '\OC\Memcache\Redis', 'memcache.local' => '\OC\Memcache\Redis', 'redis' => [ 'host' => '10.10.10.30', 'port' => 6379, 'timeout' => 3, ],
Nasz plik konfiguracyjny powinien wyglądać w następujący sposób:

Na koniec ponownie restartujemy klaster, aby wprowadzone zmiany zostały aktywowane:
pcs cluster stop --all && pcs cluster start --all
OPCJONALNIE: W przypadku aktywnego Selinuxa musimy jeszcze zezwolić usłudze httpd na wykonywanie połączeń z silnikiem Redis:
semanage port -m -t http_port_t -p tcp 6379
Integracja – Object Cloud Storage
Ostatnim etapem naszego wdrożenia jest podłączenie zewnętrznego magazynu, czyli integracja z naszym kontem Aruba Object Cloud Storage. Najpierw jednak samą funkcję zewnętrznych magazynów musimy aktywować z poziomu wiersza poleceń. W tym celu logujemy się do powłoki wiersza poleceń na dowolnej instancji klastra i wydajemy polecenie:
sudo -u apache php /var/www/html/nextcloud/occ app:enable files_external
Po wykonaniu powyższej komendy odświeżamy w przeglądarce panel zarządzający usługą Nextcloud. Z listy rozwijanej menu widocznego w prawym górnym rogu ekranu (litera ,,A” reprezentująca nazwę naszego konta ,,admin”) wybieramy pierwszą opcję o nazwie ,,Ustawienia”:
Następnie w menu po lewej stronie, w sekcji ,,Administracja” powinna pojawić się wcześniej niedostępna opcja o nazwie ,,Magazyny zewnętrzne”:
Klikając w nią będziemy mieli możliwość uruchomienia kreatora konfiguracji dla protokołu Amazon S3. Konfigurujemy go, podając nazwę folderu i wybierając protokół:
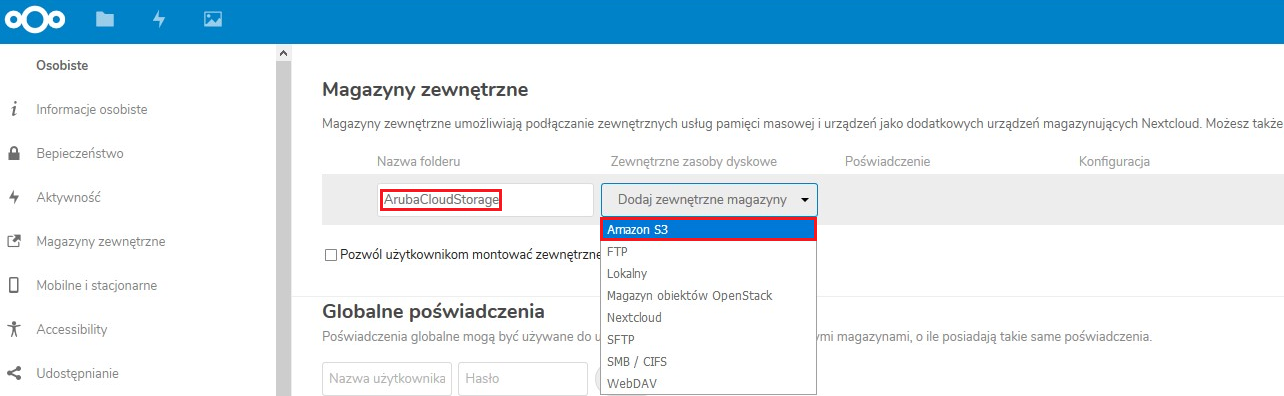
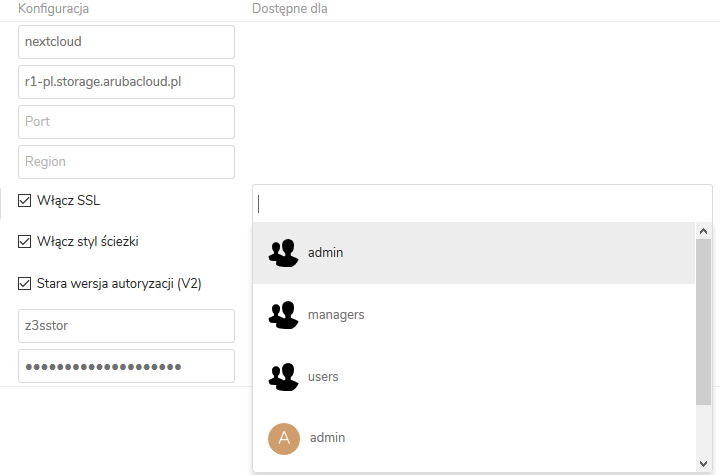
Następnie wprowadzamy wszystkie parametry niezbędne do podłączenia naszego nowego bucketa:

Kosz: dowolna nazwa bucketa (np. nextcloud). Koszyk nie musi być wcześniej utworzony, jednak jego nazwa musi być unikalna dla danego regionu.
Serwer: adres systemu Aruba Object Cloud Storage rozpoczynający się od nazwy regionu (np. r1-pl.storage.arubacloud.pl).
Zaznaczamy opcje: Włącz SSL / Włącz styl ścieżki / Stara wersja autoryzacji (V2).
Klucz dostępu: nasza nazwa konta Cloud Object Storage (w naszym przykładzie: z3sstor).
Sekretny klucz: hasło do konta Cloud Object Storage zdefiniowane podczas jego tworzenia.
Dostęp dla: W tej części konfiguracji możemy definiować, czy dany zewnętrzny zasób storage ma być dostępny dla wszystkich użytkowników Nextclouda czy też tylko dla określonej grupy lub nawet pojedynczych użytkowników:
Po zakończeniu konfiguracji zewnętrznego magazynu danych przechodzimy do głównego panelu Nextclouda i testujemy poprawność jego działania, np. poprzez załadowanie, pobranie i skasowanie testowych danych:
Podsumowanie
Nextcloud jest narzędziem o ogromnych możliwościach – nasz artykuł skupia się tylko i wyłącznie na samym procesie rozruchu systemu wraz z jego podstawową konfiguracją. Dodatkowo dla systemu dostępnych jest mnóstwo dodatkowych modułów (https://apps.nextcloud.com/), wiele z tych dodatków pozwala na lepsze zabezpieczenie naszego systemu, chociażby poprzez wdrożenie dwuskładnikowego uwierzytelniania (2FA).
Na przykładzie naszego środowiska korzystamy tylko z protokołu HTTP, dlatego przy każdym publicznym modelu wdrożenia zalecamy w pierwszej kolejności uruchomić obsługę HTTPS. Instrukcję, jak to zrobić, znajdziecie w jednym z naszych wcześniejszych artykułów z cyklu: Jak wdrożyć automatycznie odnawiane, darmowe certyfikaty SSL od Let’s Encrypt



Komentarze
Bardzo fajny artykuł.
Postawiłbym sobie takie coś na swoim serwerze gdyby nie to, że jest dysk google:)
Dlaczego lepszy jest Nextcloud od ownCloud ?
Jaka różnica i dlaczego wybraliście Nextcloud ?
Obawiam się, że nie dojdziesz.
Chłopaki z OwnCloud się pokłócili i powstał Nextcloud.
Próbowałem coś więcej znaleźć ale wygląda na słowo przeciw słowu, sytuacja dość nieciekawa i pieniądze w tle.
Ja wszędzie używam OwnCloud bo nie bardzo widzę sens zmiany (czyt. poświęcenie masy czasu żeby mieć to samo lub prawie to samo). Wszystko działa nieźle, tyle, że klient na Androida jest badziewny.
Jak ktoś ma doświadczenia z NextCloud to niech napisze, chętnie się dowiem.
Oidp oficjalna wersja zdaje się mówić, ze ownCloud zaczął za bardzo się komercjalizować, zamykanie kodu, rozjazd pomiędzy wersją community i płatną. Oryginalnemu autorowi się to nie podobało i zrobił fork.
Osobiście uciekłem z own do next. Dlaczego:
– own problemy z update gdy wersja szła do góry
– pluginy niezgodne z nowszą wersją own
– znaczące spowolnienie działania przy aktywnej ilości włączonych wtyczek
– zmiana sposobu nazewnictwa katalogów na dane dla userów wraz ze zmianami subwersji
– miałem również problemy z ldap a w zasadze z AD, pozwalało logować sie jednal nie listowało użytkowników
– hasło zmienione w ad używając own nie działało
– lepsze dopracowanie pluginów w next (tzn jabber webconf itp)
– nawet zmiana „skina” w own wiąże się babraniem się w kodzie, next ma stronę personalizacji.
Nie mowie ze ten produkt jest zły lub dobry – każdy ma inne oczekiwania.
Zobaczcie rozwiązanie seafile – troszę słabsze możliwościami jednak wbudowane szyfrowanie (nawet root nie podejrzy) którego nie można wyłączyć (prawie) powoduje że nawet ubogi soft ma coś do zaoferowania.
mysql -u root -phaslo_mysql ? :)
Przepraszam, jaka ta chmura „własna” jeżeli tak naprawdę jest w Aruba więc i tak nie wiadomo gdzie te dane leżą i kto ma do nich dostęp? (-:
dokładnie !!! artykuł myli, to nie jest własna chmura tylko u kogoś –w chmurach; własne rozwiązanie to nas4free, lub freenas, lub openmediavault postawione na energooszczednym kompie/serwerze.
Można uruchomić na tym wszelkie usługi typu sync (np syncthing, rsync, webdav, nfs, ftp, sambe, ssh czy inne do podlaczenia androida/telefonu z dostepem spoza nata.
Ewentualnie ubuntu serwer z usługami typu webmin.
Bardzo nieefektywna konfiguracja bez PHP-FPM. Jest wrecz niezalecane uzywanie PHP bez FPM. Nie ma tez nic o hardeningu samego PHP i Apache. Po przejsciu przez w/w tutorial polecam wejscie na https://twoja-chmura.xy/settings/admin/overview
Ja wiem, ze to tekst sponsorowany ale przydaloby sie zeby ktos to przeczytal przed publikacja.
Czepiasz sie. Przyczep sie jeszcze do wyboru apache bo przeciez ngnix jest szybszy i stabilniejszy prawda? ;)
Może jest. Nie wiem. Nginxa używam jako reverse proxy dla Nextclouda, który właśnie stoi na Apache. Jeżeli podstawy konfiguracji to dla ciebie czepialstwo to nie chciałbym widzieć infrastruktury za którą odpowiadasz.
@Wujek,
jak sam zauważyłeś nie ma nic o hardeningu, a wynika to z faktu że to jest podstawowa konfiguracja. To samo jest z nieefektywną konfiguracją PHP.
Mam nadzieje, że zdajesz sobie sprawę, że jeżeli każdy wpis o podstawach miał zawierać wszystkie/większość dobrych praktyk, zaleceń to nie byłby podstawami.
@Wujek, mogę Cię zapewnić że chciałbyś zobaczyć infrastrukturę, za którą odpowiadam ;)
No to albo robisz dobrze albo wcale. Poradnik jak wyzej raczej prowadzi do tworzenia kolejnych zle/slabo skonfigurowanych/zabezpieczonych serwisow dostepnych publicznie w internecie. O ile Rysiek ze Zbyszkiem z gimnazjum nr x moga sobie takich porad na swoich blogu udzielac o tyle od z3s oczekiwalbym czegos innego.
trzeba być niepełnosprawnym umysłowo, żeby korzystać z wątpliwego wynalazku jakim jest chmura do umieszczania jakichkolwiek wrażliwych danych. świat zwariował, marketing robi swoje, a ludzie nie mają pojęcia czym jest chmura a czym prywatne serwery. ten artykuł namawia do kolejnej idiotycznej rzeczy jaką jest „własna chmura”, to tak jakby armatą zabijać mrówkę.
Ja mam Nextclouda na swoim serwerze w swojej lokalizacji. Nie trzymam tam wrazliwych informacji. Prosze o porade.
> ludzie nie mają pojęcia czym jest chmura a
> czym prywatne serwery.
> ten artykuł namawia do kolejnej idiotycznej
> rzeczy jaką jest „własna chmura”
W ogóle „chmura” to nowomowa marketingowa. To po prostu inny komputer do którego zdalnie uzyskuje się dostęp przez połączenie sieciowe. Jedyne bezpieczne użycie takiego rozwiązania to fizyczna kontrola nad tym zdalnym komputerem.
Rozwiązaniem gorszym jest trzymanie danych na zdalnym komputerze nad którym fizycznej kontroli nie mamy, ale wszystko co tam trafia jest zaszyfowane kluczem którego poza nami nikt nie posiada. Wadą jest udostępnianie takiemu komputerowi metadanych. Jak dużo ich będzie i jak groźne będą to zależy już od czynników wielu…sd
Czy możesz rozwinąć swoją myśl „…Rozwiązaniem gorszym jest trzymanie danych na zdalnym komputerze nad którym fizycznej kontroli nie mamy, ale wszystko co tam trafia jest zaszyfowane kluczem którego poza nami nikt nie posiada…”.
Dlaczego uważasz że umieszczanie danych zaszyfrowanym kluczem jest gorszym rozwiązaniem?
Uważasz, że ktoś jest w stanie 'złamać’ szyfrowanie w rozsądnym czasie?
@pytajnik
trzymanie danych na odległym komputerze nad którym nie masz kontroli jest gorsze niż trzymanie ich na komputerze nad którym masz kontrolę
zaszyfrowanie chroni treść, ale ten kto kontroluje zdalny komputer będzie miał dostęp do informacji o metadanych – jak często są przeglądane, zmieniane, kto i skąd się do nich łączy, itd., pozatym nieraz można dużo wywnioskować o strukturze tych danych – to już zależy od tego w jaki sposób zaimplementować szyfrowanie
Tutaj sie zgodze wlasny serwer jest bliski idealnej koncepcji bezpieczenstwa, z drugiej strony trzeba isc na kompromis dostepnosci danych. U mnie dane w chmurze to jeden wielki kontener szyfrowany po mojej stronie z odpowiednim poziomem szyfrowania.
Mam od pewnego czasu Nextcloud więc mogę się podzielić informacjami.
+ działa i nie wymaga cudów do uruchomienia
+ można dodać aplikacje, niektóre z nich są ciekawe
+ duża ilość konfiguracji, użytkowników, itp
+ obsługa przez program lub przeglądarkę
+ win, linux, android, wszędzie działa
– kiepski klient na Androida – jest rozwijany, ale:
— przesyłanie małych plików to tragedia – plik po 1 MB może się przesyłać nawet 10 sekund
— po pewnym czasie powstaje lista plików do przesłania, którą trzeba ręcznie klikać, plik po pliku, bo jest komunikat „czeka na połączenie”, a jak się kliknie na plik to nagle program widzi połączenie, wysyła jeden plik i znowu czeka
— potrafi przesłać 95% z pliku np. 100 MB i anulować przesyłanie z informacją o błędzie serwera. Za chwilę prześle ten plik bez problemów
— generalnie baaaardzo powolny i zasobożerny, po zrobieniu zdjęć czasami pół dnia zajmie mu zauważenie, że są nowe pliki do przesłania
— po dodaniu katalogu synchronizuje tylko nowe pliki, pliki które już tam są ignoruje
— brak możliwości zapisania pliku na „dysku”. Trzeba ściągnąc jako dostępny offline i szukać w katalogu pamięci podręcznej, żeby go np. skopiować na kartę pamięci
— przy dłuższej pracy czasami zapomni o synchronizacji jakiegoś pliku. Ot tak sobie.
— przy dłuższej pracy czasami zapomni, że plik ma być dostępny offline i plik nagle znika z dysku, trzeba go zaznaczyć ponownie i znowu czekać aż się ściągnie
– brak sensownego narzędzia do backupu
to takie moje uwagi
Udało się komuś ustawić object store z aruby jako główny udział (primary storage) w nextcloud?
A czemu tej aplikacji nie można zainstalować na XAMPP? Próbowałem przetestować ją w środowisku lokalnym i nic. Pojawia się error 404.
Witam fajna sprawa .Ja zainstalowałem jednego nextclouda na raspberry pi z dyskiem 500Gb wszystko ładnie śmiga synchronizacja z win10 + samba wszystko w ustawieniach nextcloudpi ,co ważne wszystko jest na moim dysku ,jest też aplikacja mobilna .Wcześniej były instalki na debianie OMV później instalacja docker itd droga przez mękę dla osób mniej obytych w linuxie .Drugi nextcloud postawiony na terminalu Mini-komputer EDJ1900 Celeron J1900 i to jest strzał w 10 -4Gb ramu 4 rdzenie wszystko śmiga aż miło .Pozdrawiam dostęp z zewnątrz jeśli mamy zewnętrzne stałe ip +przekierowanie dwóch portów i w drogę polecam .