Gdy nie działa strona WWW, wszyscy robią się nerwowi. Właściciel, bo nie zarabia, klienci, bo nie mogą wydać swoich pieniędzy i administrator, bo musi naprawić. Co zatem zrobić, by nie trzeba było się denerwować?
Artykuł jest częścią cyklu poświęconego usługom chmurowym Aruba Cloud. Wcześniej opisaliśmy, jak backup w chmurze może uratować czas (lub pracę) informatyka. Dzisiaj przejdziemy do zapewnienia dostępności usług.
W 2019 roku dokonanie zakupu na portalu aukcyjnym czy zlecenie przelewu przez bankowość internetową to dla nas prosta i intuicyjna czynność. Sytuacje, w których zmagamy się z niedostępnością kluczowego dla naszego funkcjonowania rozwiązania, są nieraz bardzo kłopotliwe i z pewnością frustrujące. Tym bardziej, jeżeli jest to usługa biznesowa: poczta elektroniczna, system obsługi płatności czy nawet nasza strona internetowa.
Jak zatem budować nasze zaplecze techniczne, aby było dostępne przez cały czas? Czy SLA na poziomie 100% jest w ogóle możliwe? Z pewnością nakłady na ,,high availability” muszą być odpowiednio wyważone. Środki poniesione na systemy redundantne powinny być tym większe, im potencjalny przestój systemu jest dla nas bardziej kosztowny.
W dotychczasowej serii artykułów stworzonych we współpracy z firmą Aruba wykorzystywaliśmy zasoby usługi Cloud Smart. Jej ogromną zaletą jest niska cena i prostota wdrożenia, stanowi ona kompaktowe rozwiązanie, a co za tym idzie ma też swoje ograniczenia. W odpowiedzi na oczekiwania klientów potrzebujących wyższej dostępności i przede wszystkim skalowalności Aruba Cloud przygotowała pakiet o nazwie Cloud Pro.
Wdrożenie klastra Apache
W dzisiejszym artykule przedstawimy, jak wdrożyć klaster serwerów WWW wraz z dedykowanym load balancerem. Możecie zacząć od lektury opisu lub obejrzeć film, przedstawiający wszystkie niezbędne etapy konfiguracji:
Jeżeli jest to Twoja pierwsza styczność z produktami firmy Aruba, to w poprzednich artykułach z naszego cyklu znajdziesz stosowną instrukcję założenia konta. Mając już dostęp do panelu zarządzającego oraz środki na koncie, możemy od razu przystąpić do tworzenia naszej infrastruktury. Na początek jednak przyjrzyjmy się poniższemu schematowi:
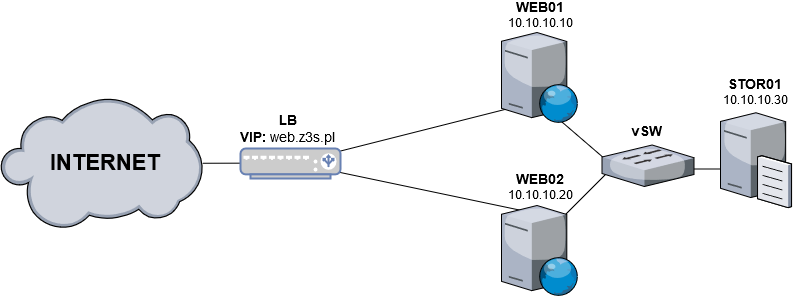
Jak widać powyżej, nasze środowisko składa się z trzech serwerów oraz rozwiązania w postaci gotowego load balancera. Dzięki dedykowanemu vSwitchowi wszystkie instancje systemu będą połączone ze sobą w ramach jednej wewnętrznej podsieci. Load balancer będzie odpowiedzialny za równoważenie ruchu przychodzącego. W przeciwieństwie do systemów dostępnych w ramach Cloud Smart, dla wersji Cloud Pro środki nie są od razu rezerwowane, ponieważ obowiązuje tutaj godzinowe rozliczenie kosztów.
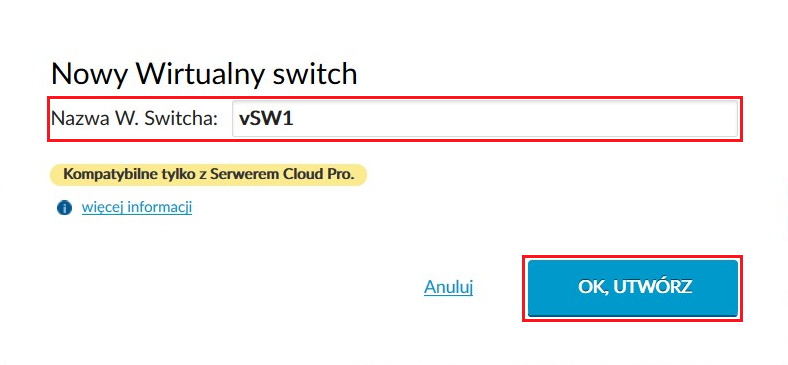
Wdrożenie rozpoczynamy od utworzenia wirtualnego przełącznika z poziomu odpowiedniej zakładki:

Dodanie vSwitcha sprowadza się do kliknięcia na przycisk

i nadania mu nazwy:
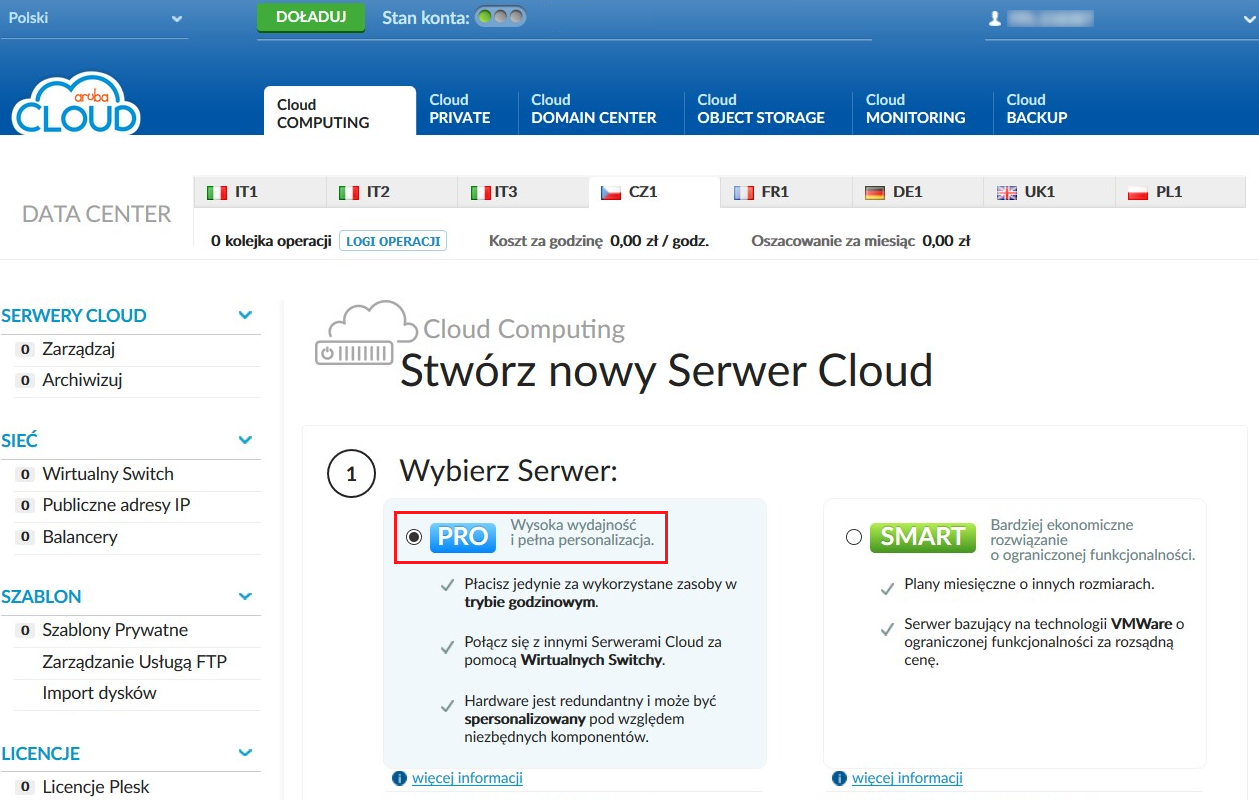
Następnie wracamy do zakładki Cloud COMPUTING i rozpoczynamy proces tworzenia pierwszej instancji poprzez kliknięcie na

Wybieramy serwer w wersji PRO:
Następnie określamy platformę wirtualizacji i szablon systemu operacyjnego. Dla potrzeb naszego przykładowego wdrożenia będziemy wykorzystywać systemy CentOS 7.x x64. Kolejno definiujemy poszczególne parametry naszego serwera, takie jak liczba vCore, rozmiar pamięci RAM i przestrzeń dyskowa HD1:
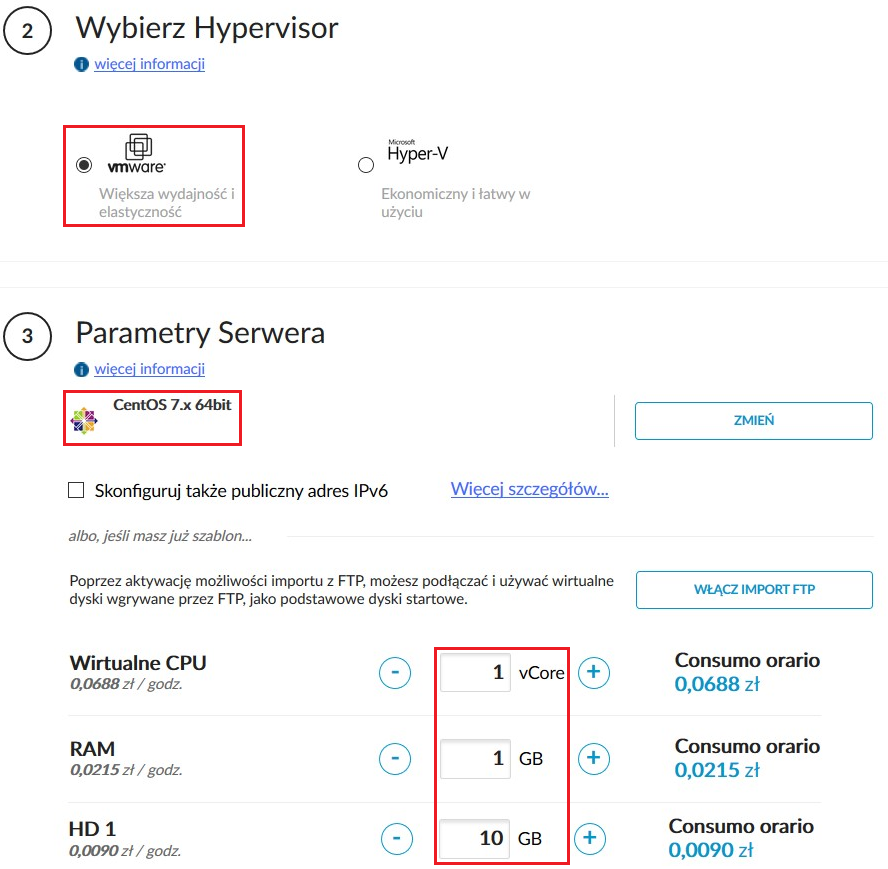
W naszej konfiguracji do każdej z instancji dodajemy po jeszcze jednym dodatkowym dysku (np. o rozmiarze 10 GB):
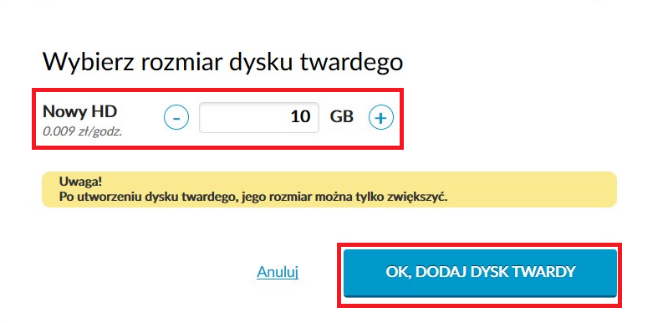
Ponadto nasz system jest wyposażony w 3 interfejsy sieciowe. Pierwszy z nich jest zawsze automatycznie adresowany publicznym IP, jaki wykorzystamy później do zarządzania systemem przez SSH. Drugi interfejs podłączamy do wcześniej utworzonego vSwitcha:
Podczas podłączania w konfiguracji podajemy adres IP i maskę podsieci pierwszego serwera:
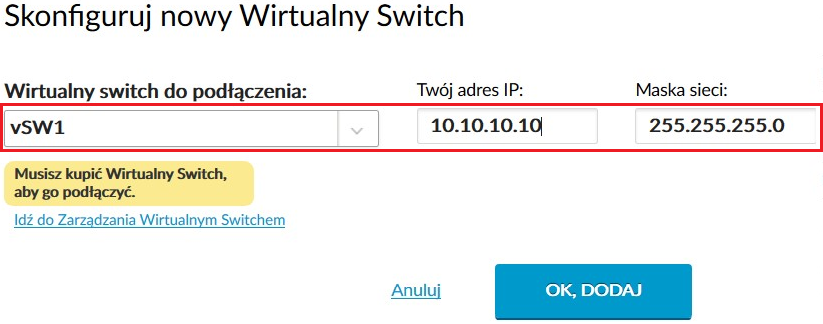
UWAGA: Zalecamy ustawienie tak wąskiej maski, jak to jest tylko możliwe – oczywiście rozmiar podsieci musi uwzględniać bezpieczny zapas na wypadek jej rozbudowy w przyszłości.
Od utworzenia serwera dzielą nas jeszcze dwa kroki – zdefiniowanie jego nazwy:
oraz skonfigurowanie dostępu do niego poprzez zdefiniowanie hasła użytkownika root. Zalecamy wdrożenie logowania z wykorzystaniem uprzednio wygenerowanej pary kluczy:
Po uzupełnieniu wszystkich niezbędnych informacji możemy przystąpić do zakończenia kreatora, który tym samym wywoła uruchomienie naszej instancji.
Powyżej opisane czynności powtarzamy dokładnie tak samo dla serwerów WEB02 i STOR01.
Poniżej znajduje się lista kolejnych kroków, jakie należy przeprowadzić na instancjach WEB01 i WEB02, aby spiąć między nimi klaster wysokiej dostępności dla usługi Apache (httpd). Zalecamy, aby zestaw komend z każdego punktu wykonać kolejno na każdym z serwerów, zanim przejdziemy do kolejnego.
1. Na obu serwerach w pierwszej kolejności włączamy usługę firewalld:
systemctl enable firewalld && systemctl start firewalld
2. Do plików hosts obu serwerów dopisujemy ich adresy IP i nazwy:
sed -i '/WEB/d' /etc/hosts echo '10.10.10.10 WEB01' >> /etc/hosts && echo '10.10.10.20 WEB02' >> /etc/hosts
UWAGA: Jeżeli nazwy nadane instancjom nie zaczynają się od frazy ,,WEB”, to powyższe polecenia muszą zostać odpowiednio zmodyfikowane.
3. Definiujemy poprawne nazwy hostów:
[root@web01 ~] hostnamectl set-hostname web01 [root@web02 ~] hostnamectl set-hostname web02
4. Instalujemy wymagane pakiety na każdej z instancji:
yum -y install pcs dlm fence-agents-all gfs2-utils httpd iscsi-initiator-utils wget rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org && rpm -Uvh \ http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm && yum install -y kmod-drbd84 drbd84-utils semanage permissive -a drbd_t
5. Instalacja Pacemaker Configuration System automatycznie tworzy w systemie użytkownika o nazwie ,,hacluster”. Na obu instancjach tworzymy dla niego hasło, które będzie wykorzystywane do autoryzacji pomiędzy poszczególnymi nodami klastra:
echo 'haslo_klastra' | passwd --stdin hacluster
6. Przechodzimy do szczegółowej konfiguracji firewalld. Najpierw definiujemy strefy na odpowiednich interfejsach. W naszym wypadku eth0 to interfejs publiczny, a eth1 – wewnętrzny:
firewall-cmd --zone=public --change-interface=eth0 --permanent firewall-cmd --zone=internal --change-interface=eth1 --permanent
7. Nody naszego klastra mają się komunikować w ramach sieci wewnętrznej. W związku z tym dodajemy odpowiednie reguły dla strefy internal na obu instancjach:
firewall-cmd --zone=internal --add-service=high-availability --permanent firewall-cmd --zone=internal --add-port=7789/tcp --permanent
8. Na koniec zezwalamy na ruch http/https dla sieci wewnętrznej i przeładowujemy firewalla:
firewall-cmd --zone=internal --add-service=http --permanent firewall-cmd --zone=public --add-service=http --permanent firewall-cmd --reload
9. Uruchamiamy usługę PCSD:
systemctl start pcsd && systemctl enable pcsd
UWAGA: Kolejne polecenia wykonujemy tylko na serwerze WEB01.
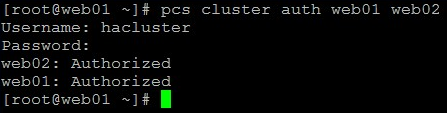
10. Weryfikujemy, czy uwierzytelnienie pomiędzy nodami przebiega poprawnie:
pcs cluster auth web01 web02
Po podaniu poprawnego hasła powinniśmy zobaczyć poniższy komunikat:
11. Spinamy klaster serwerów ze sobą, nadając mu jednocześnie nazwę ,,klasterweb”:
pcs cluster setup --start --name klasterweb web01 web02
12. Na koniec włączamy klaster i sprawdzamy jego status:
pcs cluster status
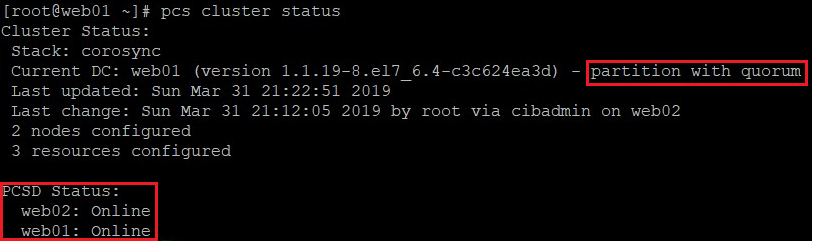
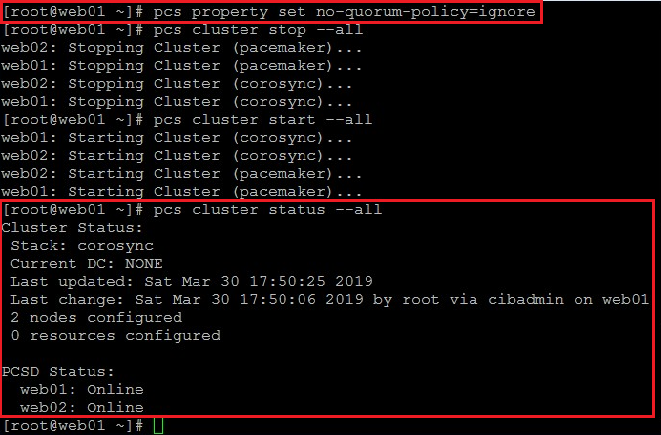
13. Jak widać powyżej, stan klastra osiągnął kworum. W przypadku naszej konfiguracji, gdzie wykorzystywać będziemy tylko dwa serwery z usługą httpd, sprawdzanie kworum musi być ignorowane. Klaster pozostaje aktywny, dopóki kworum wynosi więcej niż połowa nodów, a co za tym idzie – wyłączenie jednego naszego serwera dezaktywowałoby nasz klaster:
pcs property set no-quorum-policy=ignore && pcs cluster stop --all pcs cluster start --all && pcs cluster status --all
Po wykonaniu powyższych poleceń stan klastra powinien wyglądać jak poniżej:
Active-Passive
Teraz skonfigurujemy przestrzeń współdzieloną na pliki dla usługi Apache. Ponownie polecenia wykonujemy na WEB01 i WEB02.
1. Zaczynamy od utworzenia woluminów logicznych na drugim dysku (/dev/sdb):
pvcreate /dev/sdb vgcreate wwwdata /dev/sdb lvcreate -n drbd-wwwdata -l 100%FREE wwwdata
UWAGA: Jeżeli dodatkowy dysk nie jest widoczny, to konieczny jest restart systemu.
2. Przechodzimy do skonfigurowania replikacji naszych woluminów logicznych w oparciu o DRBD (Distributed Replicated Block Device). W tym celu na serwerach tworzymy plik konfiguracyjny: /etc/drbd.d/wwwdata.res
Plik ten ma mieć następującą zawartość:
resource wwwdata {
protocol C;
meta-disk internal;
device /dev/drbd1;
syncer {
verify-alg sha1;
}
net {
allow-two-primaries;
}
on web01 {
disk /dev/wwwdata/drbd-wwwdata;
address 10.10.10.10:7789;
}
on web02 {
disk /dev/wwwdata/drbd-wwwdata;
address 10.10.10.20:7789;
}
}
Uruchamiamy usługę DRBD i aktywujemy zasób dyskowy:
systemctl enable drbd && systemctl start drbd drbdadm create-md wwwdata modprobe drbd
Sprawdzamy stan zasobu:
cat /proc/drbd
Zasób powinien uruchomić się automatycznie, jeżeli jednak tak się nie stanie, na obu serwerach należy go uruchomić poniższym poleceniem:
drbdadm up wwwdata
Zasób będzie skonfigurowany, ale jego stan może być niezsynchronizowany:

Tylko na serwerze WEB01 wykonujemy polecenie wymuszenia synchronizacji dysków:
drbdadm primary --force wwwdata watch -n 1 'cat /proc/drbd'
Czekamy, aż synchronizacja dobiegnie końca:
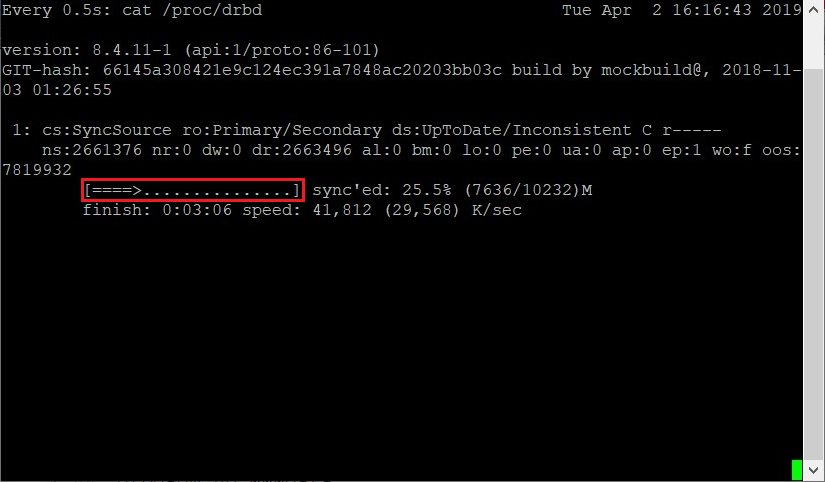
Kończymy komendę watch kombinacją klawiszy Ctrl+C i zabieramy się za tworzenie systemu plików i struktury katalogowej (polecenia wydajemy tylko na WEB01):
mkfs.xfs /dev/drbd1 mount /dev/drbd1 /var/www && mkdir /var/www/html && umount /dev/drbd1
Montowanie i odmontowanie zasobu na razie wykonujemy testowo – docelowo za obsługę tego mechanizmu będzie odpowiadać PCSD.
3. Przystępujemy do skonfigurowania klastra pod system DRBD, wykonując poniższe polecenia tylko na serwerze WEB01:
pcs cluster cib drbd_cfg pcs -f drbd_cfg resource create klasterweb_data ocf:linbit:drbd \ drbd_resource=wwwdata op monitor interval=60s pcs -f drbd_cfg resource master klasterweb_data_clone klasterweb_data \ master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 \ notify=true pcs cluster cib-push drbd_cfg --config
Na koniec włączamy ładowanie modułów DRBD na systemach WEB01 i WEB02 wraz ze starem systemu:
echo drbd >/etc/modules-load.d/drbd.conf
Ponownie przechodzimy tylko do konfiguracji serwera WEB01 i chwilowo wyłączamy mechanizm STONITH, ponieważ jego poprawna konfiguracja zostanie wykonana na późniejszym etapie:
pcs property set stonith-enabled=false && crm_verify -L
4. Tworzymy wspólne zasoby danych dla kastra:
pcs cluster cib fs_cfg pcs -f fs_cfg resource create klasterweb_apache \ Filesystem device="/dev/drbd1" \ directory="/var/www" \ fstype="xfs" pcs -f fs_cfg constraint colocation add \ klasterweb_apache with klasterweb_data_clone INFINITY with-rsc-role=Master pcs -f fs_cfg constraint order \ promote klasterweb_data_clone then start klasterweb_apache pcs -f fs_cfg constraint colocation add klasterweb_apache with klasterweb_data_clone INFINITY pcs -f fs_cfg constraint order klasterweb_data_clone then klasterweb_apache pcs cluster cib-push fs_cfg --config pcs resource show
Ostatnim poleceniem weryfikujemy, czy zasób został utworzony prawidłowo:

5. Dodajemy mechanizm monitorowania usługi Apache. Na serwerach WEB01 i WEB02 tworzymy plik /etc/httpd/conf.d/status.conf zawierający poniższe linie:
<Location /server-status>
SetHandler server-status
Require local
</Location>
Stworzenie pliku status.conf spowoduje aktywację serwisu pod następującym URL-em: http://localhost/server-status. PCS będzie odpytywać ten adres celem monitorowania stanu usługi.
Na obu serwerach edytujemy plik /etc/httpd/conf/httpd.conf i na samym jego końcu dopisujemy poniższy wiersz:
PidFile /var/run/httpd/httpd.pid
Następnie na obu serwerach WEB01 i WEB02 wywołujemy poniższe polecenia:
systemctl enable httpd
Przechodzimy do serwera WEB01 i testowo restartujemy cały klaster:
pcs cluster stop --all && pcs cluster start --all
Po pomyślnym restarcie wdrażamy mechanizm monitorowania stanu usługi Apache (heartbeat):
pcs resource create klasterweb_apache_status ocf:heartbeat:apache \ configfile=/etc/httpd/conf/httpd.conf \ statusurl="http://localhost/server-status" \ op monitor interval=1min pcs resource op defaults timeout=240s pcs resource op defaults
6. Sprawdzamy, który serwer jest aktywną instancją klastra:
pcs status | grep 'Masters'

Przechodzimy do konsoli aktywnego serwera (powyżej WEB02) i wykonujemy na nim test opisany w kolejnym punkcie.
7. Tworzymy testową podstronę i weryfikujemy stan pracy klastra:
mkdir /var/www/html echo '<h1>TEST</h1>' > /var/www/html/index.html pcs status
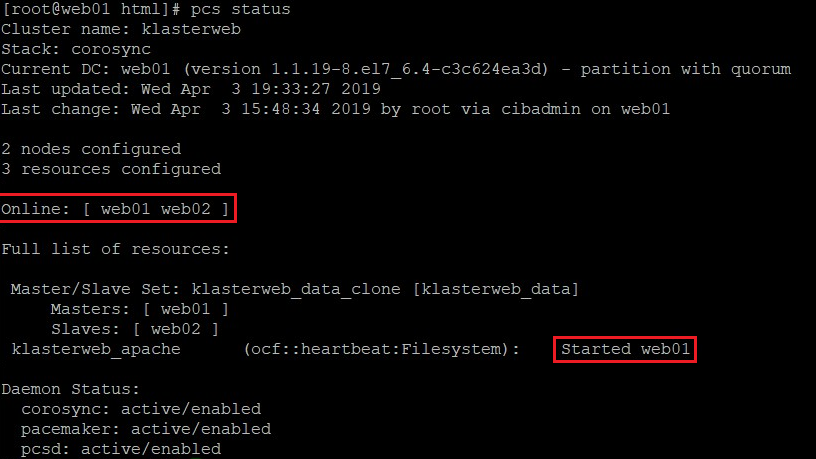
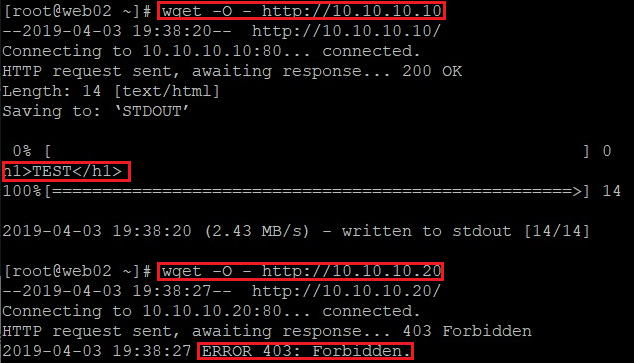
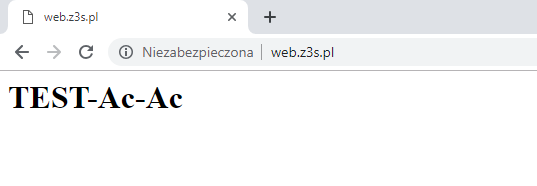
Jak widać powyżej, aktywnym serwerem jest WEB01. Korzystając z klienta wget, na dowolnym serwerze możemy sprawdzić, jaka zawartość jest serwowana na każdej z instancji:
wget -O - http://10.10.10.10 wget -O - http://10.10.10.20
STONITH
Pacemaker umożliwia wdrożenie mechanizmu o nazwie STONITH (Shot The Other Node In The Head). Pozwala on na automatyczne odłączanie uszkodzonych serwerów z klastra. Do pracy STONITH-a wymagane jest tworzenie dedykowanego, współdzielonego urządzenia blokowego:
1. W pierwszej kolejności musimy aktywować wcześniej wyłączony mechanizm STONITH:
pcs property set stonith-enabled=true
2. Idąc dalej, na serwerze STOR01 przeprowadzamy instalację usługi celu iSCSI (tzw. iscsi target)
yum -y install targetcli systemctl enable target && systemctl start target
3. Tworzymy odpowiednie reguły i strefy firewalld:
systemctl enable firewalld && systemctl start firewalld firewall-cmd --zone=public --change-interface=eth0 --permanent firewall-cmd --zone=internal --change-interface=eth1 --permanent firewall-cmd --zone=internal --add-port=3260/tcp --permanent firewall-cmd --reload
4. Partycjonujemy drugi dysk (/dev/sdb) z wykorzystaniem LVM:
pvcreate /dev/sdb vgcreate klasterweb_data /dev/sdb lvcreate -l 100%FREE -n klasterweb_stonith klasterweb_data
5. Zanim przystąpimy do konfiguracji iSCSI, musimy z obu serwerów WEB01 i WEB02 odczytać i zanotować ich unikalne nazwy inicjatorów:
cat /etc/iscsi/initiatorname.iscsi
6. Przystępujemy do konfiguracji iSCSI, korzystając z narzędzia targetcli:
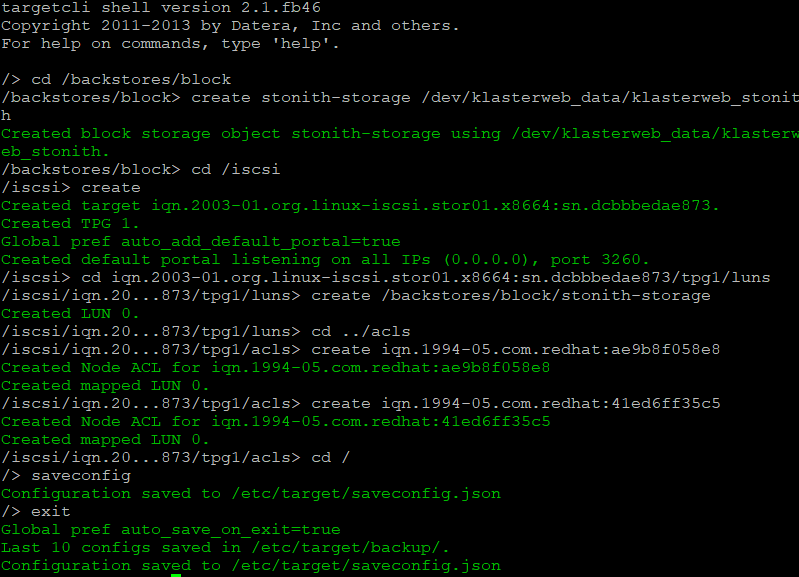
targetcli cd /backstores/block create stonith-storage /dev/klasterweb_data/klasterweb_stonith cd /iscsi create cd iqn.2003-01.org.linux-iscsi.stor01.x8664:sn.3144b90ea92b/tpg1/luns create /backstores/block/stonith-storage cd ../acls create iqn.1994-05.com.redhat:b7b0f376d60 create iqn.1994-05.com.redhat:ff9a3a19b696 cd / saveconfig exit
Efekt powyższych poleceń powinien przedstawiać się następująco:
7. Po stronie serwerów WEB01 i WEB02 skanujemy i podłączamy target iSCSI:
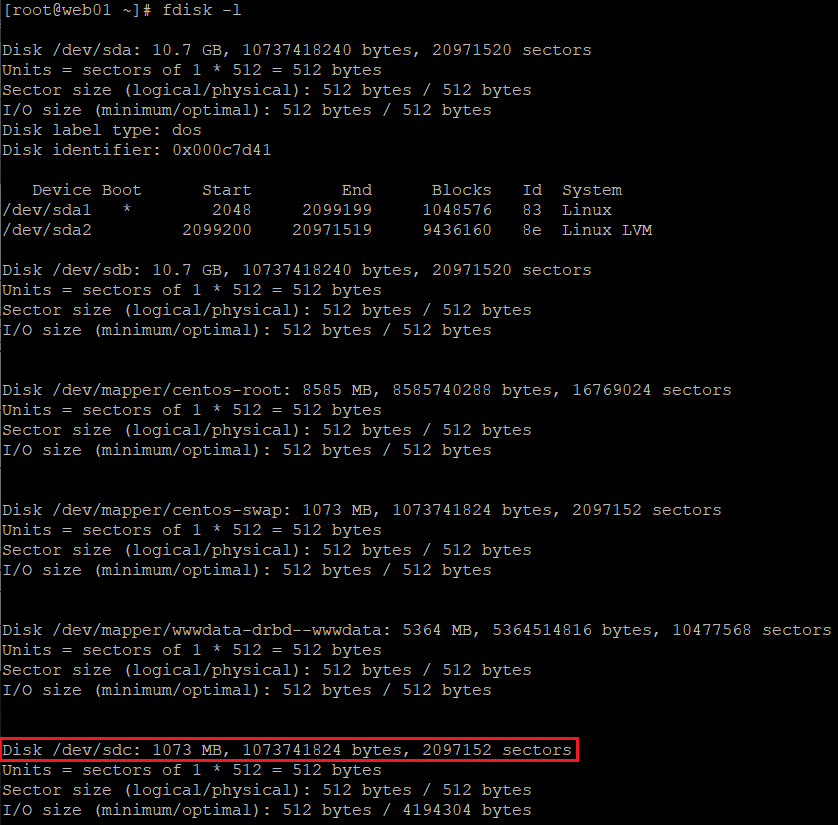
systemctl enable iscsi systemctl enable iscsid systemctl start iscsi iscsiadm --mode discovery --type sendtargets --portal 10.10.10.30 iscsiadm -m node -T iqn.2003-01.org.linux-iscsi.stor01.x8664:sn.3144b90ea92b -l -p 10.10.10.30:3260 fdisk -l
Powinniśmy zobaczyć, że nowe urządzenie blokowe zostało podłączone do każdego z serwerów:
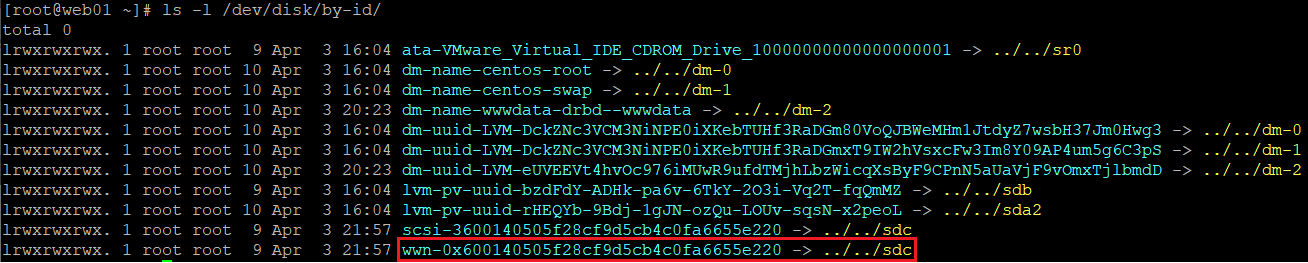
8. Identyfikujemy i notujemy ID dysku podłączonego przez iSCSI:
ls -l /dev/disk/by-id/
9. Tworzymy zasoby niezbędne do monitorowania klastra. Polecenia wydajemy tylko na serwerze WEB01:
pcs stonith create webcluster_stonith \ fence_scsi pcmk_host_list="web01 web02" \ pcmk_monitor_action="metadata" \ pcmk_reboot_action="off" \ devices="/dev/disk/by-id/wwn-0x600140505f28cf9d5cb4c0fa6655e220" \ meta provides="unfencing" pcs stonith show
Ostatnim poleceniem weryfikujemy, czy zasób został utworzony prawidłowo:

Active-Active
Wdrożyliśmy klaster Apache w modelu Active-Passive, co w praktyce oznacza, że ruch może być generowany tylko do jednej, aktywnej instancji. Aby skorzystać z load balancera, niezbędne jest wdrożenie trybu Active-Active. Poniżej opisujemy, jak skonwertować nasz klaster do pracy w takim trybie.
Poniższe polecenia wykonujemy tylko na instancji WEB01, ponieważ PCS synchronizuje swoją konfigurację w ramach całego klastra:
1. Przygotowujemy klaster pod wdrożenie usługi DLM (Distributed Lock Manager).
pcs cluster cib dlm_cfg pcs -f dlm_cfg resource create dlm ocf:pacemaker:controld \ op monitor interval=60s pcs -f dlm_cfg resource clone dlm clone-max=2 clone-node-max=1 pcs cluster cib-push dlm_cfg --config
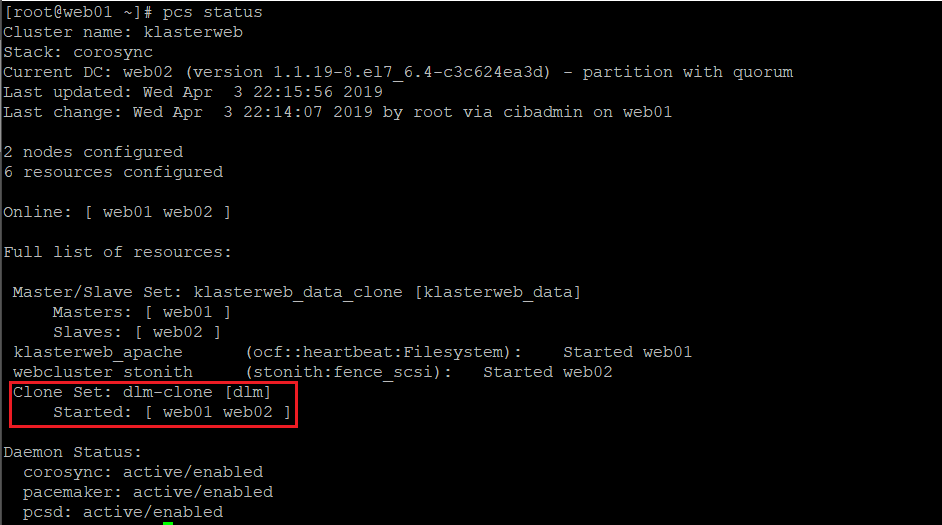
2. Weryfikujemy poprawność uruchomienia DLM:
pcs status
3. Wyłączamy zasób dyskowy klastra w celu odmontowania /dev/drbd1 i zmieniamy obecny system plików na format gfs2:
pcs cluster stop web02 pcs resource disable klasterweb_apache mkfs.gfs2 -p lock_dlm -j 2 -t klasterweb:apache /dev/drbd1
UWAGA: Zmiana systemu plików skasuje wszystkie dane z partycji /dev/drbd1
4. Aktualizujemy zasób plikowy klastra i konfigurujemy DLM:
pcs resource disable klasterweb_apache && pcs resource update klasterweb_apache fstype=gfs2 pcs constraint colocation add klasterweb_apache with dlm-clone INFINITY pcs constraint order dlm-clone then klasterweb_apache
5. Nowy system plików klastra jest gotowy. Pozostaje nam skonfigurowanie klastra w taki sposób, aby wszystkie nody podmontowały ten sam zasób i odpowiadały jednocześnie na żądania HTTP kierowane z load balancera:
pcs cluster cib active_cfg pcs -f active_cfg resource clone klasterweb_apache pcs -f active_cfg constraint pcs -f active_cfg resource update klasterweb_data_clone master-max=2 pcs cluster cib-push active_cfg --config pcs resource enable klasterweb_apache pcs cluster stop --all pcs cluster start --all
6. Na koniec przetestujmy, czy klaster pracuje w trybie Active-Active:
pcs cluster cib active_cfg pcs -f active_cfg resource clone klasterweb_apache pcs -f active_cfg constraint mkdir /var/www/html echo '<h1>TEST-Ac-Ac</h1>' > /var/www/html/index.html wget -O - http://10.10.10.10 wget -O - http://10.10.10.20
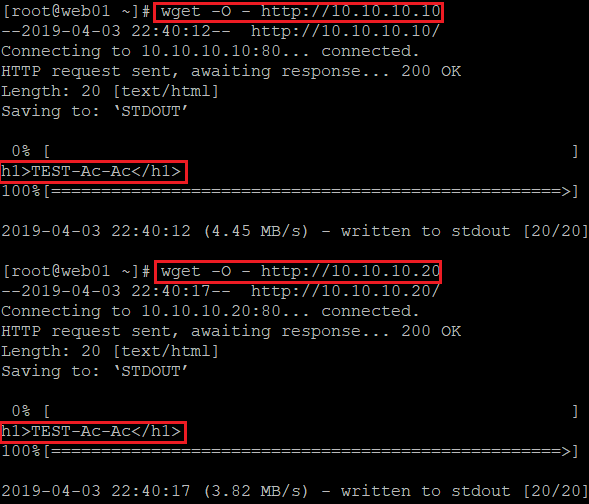
W przeciwieństwie do trybu Active-Passive wykonany test dla obydwu instancji zwraca wyświetlenie tej samej zawartości serwera WWW.
Wdrożenie load balancera
Ostatnim etapem naszej instalacji jest uruchomienie load balancera – dokonujemy tego z poziomu odpowiedniej zakładki na panelu zarządzającym:
Balancera tworzymy poprzez kliknięcie na przycisk

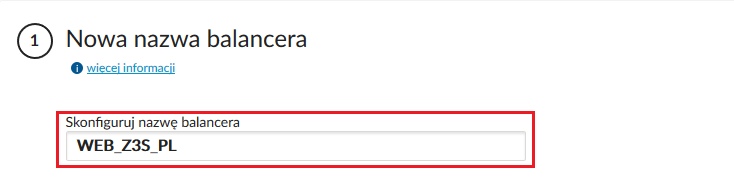
następnie definiujemy jego nazwę:
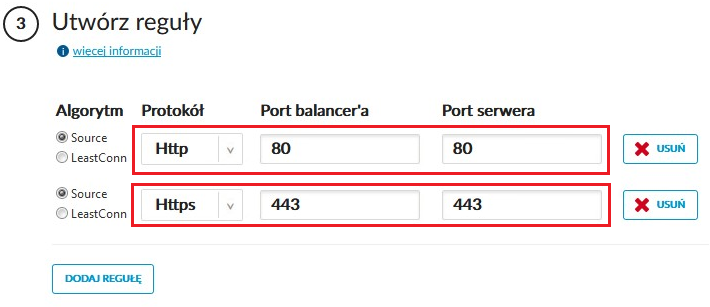
W konfiguracji zaznaczamy serwery WEB01 i WEB02 oraz definiujemy reguły dla portów 80 i opcjonalnie 443:

Na koniec przechodzimy do utworzenia load balancera:
Rozwiązanie automatycznie otrzyma nowy publiczny adres IP, jaki możemy wykorzystać do utworzenia nowego rekordu A na naszym serwerze DNS. Na koniec należy przetestować z poziomu dowolnej przeglądarki, czy load balancer prawidłowo przekieruje ruch do obu naszych serwerów:
Podsumowanie
Opisaliśmy szereg czynności prowadzących do uruchomienia klastra wysokiej dostępności wraz z load balancingiem. Rozwiązanie to przynosi następujące korzyści:
- Skalowalność – w dowolnym momencie pracy klastra, bez przerywania jego funkcjonowania, możemy dodawać kolejne instancje.
- Zwiększanie zasobów instancji – w przypadku Cloud Pro możemy dowolnie zmieniać zasoby naszych maszyn (vCore, RAM, HDD). Jest to możliwe tylko wtedy, gdy rozszerzana instancja zostanie wyłączona. Dzięki klastrowi poszczególne instancje możemy wyłączyć bez przerywania pracy całego systemu (np. aplikacji sklepu internetowego).
- Odporność na błędy aplikacyjne – mechanizm STONITH dostarcza funkcję monitorowania stanu nodów klastra i ich automatycznego przywracania.
Za usługę Cloud Pro pobierane są opłaty według wykorzystania – należy o tym pamiętać, ponieważ w przypadku wyłączenia instancji opłaty za jej utrzymanie są nadal pobierane. Jeżeli testujesz usługę lub potrzebujesz niezawodnego środowiska labowego, po zakończonych działaniach swoje instancje możesz zawsze zarchiwizować:

W takim przypadku niewielkie opłaty są naliczane jedynie za przestrzeń dyskową, jaką zajmują zarchiwizowane dyski naszych instancji.
Posłowie
Niniejszy artykuł skupia się przede wszystkim na wdrożeniu środowiska zapewniającego wysoką dostępność. Warto zatem pamiętać o dobrych praktykach związanych z właściwym zabezpieczeniem zarówno systemu operacyjnego, jak i usług działających w jego ramach. W przypadku potrzeby lepszego zabezpieczenia usługi serwera WWW zachęcamy do zapoznania się z naszymi wcześniejszymi publikacjami:



Komentarze
Panowie ja rozumiem, ze Aruba placi za promocje. Ale:
Dzis sie uzywa do takich rzeczy Terraform. Istnieje nawet nieoficjalne wsparcie dla Aruby i tu nalezaloby sie zapytac panow z Aruby dlaczego nierobia nic w tym kierunku aby to wsparcie bylo natywne. To samo zreszta tyczy sie Proxmoxa ale to juz inna historia.
@Wujek,
jakieś potwierdzenie Twoich słów (wiarygodne źródło), „…Dzis sie uzywa do takich rzeczy Terraform…”?
Z miałą chęcią Ciotka się zapozna.
Dodając do komentarza Wujka Pawla – nie pamiętam kiedy ostatnio używałem apache, chyba w krasnalu na windowsie 15 lat temu :D
Pod php to tylko nginx + varnish + redis + rabbit – to jest stack dla webaplikacji
Ja mam dwa serwery z Nextcloudem. Jeden z Apache (PHP FPM) + Redis, drugi Nginx (PHP FPM) + Redis. Nie widze roznicy. Oba to fizyczne maszyny (R410) z dyskami SAS.
@Przemek,
poważnie nie ogarniasz że jest to przykład, którego zadaniem nie jest wybór najlepszej z najlepszej opcji webserwera a pokazanie PRZYKŁADU, w tym przypadku Apache.
Przy okazji, dyskusja co jest lepsze czy apache/Nginx/czy serwer pisany w Pythonie nie ma znaczenia.
@Przemek, akurat w opisanej przez Ciebie konfiguracji najmniejsza różnice robi czy masz apache czy nginx
IMHO zdecydowanie przekombinowane podejście. Użycie DRBD do spółki z GFS wprowadza dodatkową warstwę abstrakcji i potencjalnych problemów – np. split-brain (kto widział DRBD w akcji, ten wie). Pacemaker użyty do monitorowania stanu serwerów localhost, a loadbalancer używa publicznych IP jako backendu…
Maszyna wirtualna w charakterze shared storage do zapewniania HA – czym ona się różni od webserwerów (pod kątem hardware/dostępności) i co się stanie jak ta maszyna padnie (a razem z nią blok device do DLM ?) – coś czuję SPOF. Skalowalność w tym przypadku mocno dyskusyjna – spróbujcie szybko rozszerzyć to DRBD o kolejne node’y/apache.
Poszczególne webserwery powinny być niezależne od siebie, odpowiednie healtchecki na loadbalancerze (oraz obsługiwane w aplikacji, sam status apache’a to za mało) i do tego autoscaling.
Dobry artykuł i oby więcej takich, jednak ewidentnie zabrakło drugiej pary oczu do przeczytania przed publikacją.
– RedHat nie wspiera gfs na dbrd, co skreśla tą konfigurację na starcie
– Do czego miał służyć trzeci interfejs w maszynach?
– Skoro mamy już storage wpięty w jakiś san, to czemu nie zduplikować ścieżek i z niego nie podciągnąć dysku? Albo nawet podciągnąć to bezpośrednio na serwery web?
– Fencing można tez zrobić bez potrzeby użycia kolejnego systemu. Wtedy ta konfiguracja miałaby nawet jeszcze jakiś sens, w trybie active-pasive.