We wrześniu 2008 Microsoft natrafił na podejrzany błąd zgłoszony przez jednego użytkownika. Żmudne śledztwo wykazało, że był to ślad wykorzystania błędu typu 0day o niezwykłej wadze – zdalnego wykonania kodu na każdym Windowsie.
Błędy tego typu to tęczowe jednorożce świata bezpieczeństwa. Jeden pakiet, którym można przejąć pełną kontrolę nad każdym komputerem z systemem Windows na całym świecie jest marzeniem każdego atakującego. Microsoft, dzięki sprytnym mechanizmom identyfikacji takich przypadków, był w stanie zlokalizować nieudany atak i na jego podstawie znaleźć błąd i go załatać. Zanim do tego doszło, ktoś przez dwa miesiące hakował za jego pomocą bardzo dokładnie wybrane ofiary.
Koszyk z błędami
Gdy Windows napotyka na błąd, daje użytkownikowi możliwość wysłania raportu na ten temat do centrali. Setki milionów raportów trafiają do Microsoftu. Każdy taki raport wpada do odpowiedniej kolejki, gdzie jest kategoryzowany i na podstawie danych o częstości występowania konkretnych usterek podejmowane są decyzje o kolejności wprowadzania poprawek. Podczas kiedy zespoły odpowiedzialne za prawidłowe działanie systemu interesują się najpopularniejszymi błędami, zespół odpowiedzialny za bezpieczeństwo zaczął przyglądać się błędom z drugiego końca rankingu.
Pojedyncze wystąpienia pewnych zdarzeń zaczęły interesować Microsoft po tym, jak przeanalizował historię błędu MS07-029. Gdy opublikowano informację o luce, liczba błędów z nią związanych (a więc efekt niedoskonałego działania pierwszych eksploitów) znacząco wzrosła. To skłoniło inżynierów do weryfikacji, jak wyglądała historia koszyka z tymi błędami. Gdy przewinęli historię wstecz, znaleźli pojedyncze wystąpienia błędów na kilka tygodni przed ogłoszeniem luki. Analiza tych przypadków potwierdziła, że błąd był aktywnie wykorzystywany w atakach. Od tego momentu Microsoft zaczął się przyglądać pojedynczym błędom, by wykryć nieznane jeszcze próby ataku.
Pakiet po pakiecie
We wrześniu 2008 Microsoft uruchomił wewnętrzny system analizy błędów pod kątem obecności kodów eksploitów (np. obecności shellcodu) w danych przesyłanych przez klientów po awarii systemu (co ciekawe, w projekcie ważną rolę odegrał takżę nasz rodak, Adam „pi3” Zabrocki). 25 września pojawił się pierwszy kandydat – błąd w bibliotece netapi32.dll. W rankingu błędów znajdował się w okolicach miejsca 45 000 – system odnotował tylko dwa przypadki jego wystąpienia. Wart był jednak analizy – choć błędów w netapi32.dll było sporo, to wszystkie dotyczyły prób wykorzystania MS06-040 sprzed dwóch lat. Wszystkie oprócz tych dwóch.
Jedną z technik przesyłania kodu eksploita do systemu jest wysłanie tuż przed samym atakiem niewinnego żądania do tej samej usługi, zawierającego odpowiedni znacznik i serię poleceń do wykorzystania na potem. Dane te znajdują się w pamięci systemu w momencie, gdy przychodzi właściwe polecenie zawierające złośliwy kod. Kod ten, często o ograniczonej długości, może odnaleźć wtedy wysłane wcześniej dane i z nich skorzystać. Wcześniejsze eksploity na netapi32.dll nie korzystały z tej techniki – te dwa jej używały. Drugim czerwonym światłem był fakt, że eksploit nie tylko wywołał błąd – ale także zadziałał. W pamięci procesu widać było, ze zdążył on uruchomić funkcję pobierania pliku z zewnętrznego adresu. Połączenie tych informacji z faktem, że na komputerze, który padł ofiarą ataku, obecna była najnowsza wersja biblioteki netapi32.dll nasuwało jedyny możliwy wniosek – ktoś używa błędu typu 0day.
Poszukiwanie błędu w bibliotece dopiero się jednak zaczynało. Mając do dyspozycji jedynie kod źródłowy biblioteki oraz fragmenty pamięci zapisane w czasie trwania ataku pracownicy Microsoftu musieli teraz znaleźć błąd w bibliotece. Było to bardzo trudne zadanie. Eksploit mógł już nadpisać istotne fragmenty kodu, brak było możliwości przeprowadzenia eksperymentu i obserwacji jego działania a kod biblioteki po pobieżnej analizie wydawał się nie mieć żadnych błędów. Szef inżynierów odpowiedzialnych za bezpieczeństwo kodu sam siadł do analizy – chciał udowodnić, że błędu nie ma i to, co zarejestrowały systemy, było wynikiem np. błędnego sterownika albo losowego przeskoku bitów. Analiza nie była łatwa, ale błąd w końcu udało się zlokalizować. Była jednak także zła informacja – błąd umożliwiał zdalne wykonanie dowolnego kodu z uprawnieniami SYSTEM na prawie każdym komputerze z Windowsem. Cała firma została postawiona na baczność – ten rodzaj błędu umożliwiał powstanie robaka, który zainfekuje setki milionów komputerów.
Niecierpliwy atakujący i jego pomyłka
W trakcie gdy Microsoft pracował nad analizą błędu a następnie jego załataniem, atakujący cierpliwie hakował precyzyjnie wybrane komputery. Czasem jednak popełniał błędy, które powodowały awarie systemu. Prawdopodobnie to niecierpliwość atakującego umożliwiła Microsoftowi namierzenie ataku. Błąd wykorzystywany w ataku znajdował się w kodzie przekształcającym nazwy ścieżek (np. z \jakis\…\adres.txt na \adres.txt). By móc go wykorzystać, atakujący najpierw wywoływał podatną funkcję z odpowiednim ciągiem znaków, zawierającym znak „/” oraz serię poleceń do wykonania. Dane te nie powodowały żadnej awarii, a system umieszczał je na stosie procesu. Następnie w kolejnym żądaniu atakujący wywoływał błąd i kazał procesowi szukać znaku „/” poza obszarem bufora. Proces znajdował wcześniej przesłane dane i wykonywał swoje zadanie. Warunkiem sukcesu było wywołanie obu żądań w tym samym wątku. Jak już wspominaliśmy, w analizowanym zrzucie pamięci procesu widać było, że pobiera on już plik z zewnętrznego adresu – jednak atakujący, najwyraźniej nie mogąc się doczekać efektu swojego działania, spróbował jeszcze raz wywołać błąd – lecz tym razem trafił na inny wątek, który nie mogąc znaleźć znaku „/” spowodował awarię, która trafiła do Microsoftu.
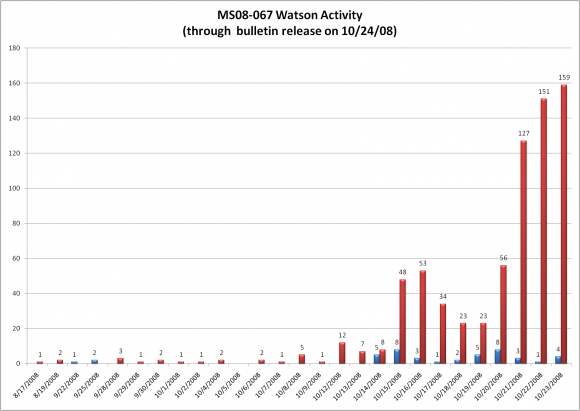
Jak wyglądała aktywność atakującego? Nieudane próby zostały w części zarejestrowane przez Microsoft (są to tylko przypadki, gdzie użytkownik wybrał opcję wysłania raportu o błędzie), zaś udane próby można było prześledzić, ponieważ w znanym wariancie udany atak powodował pobranie pliku z konkretnego serwera, do którego udało się uzyskać dostęp badaczom analizującym ten atak. Microsoft sporządził wykres tej aktywności:
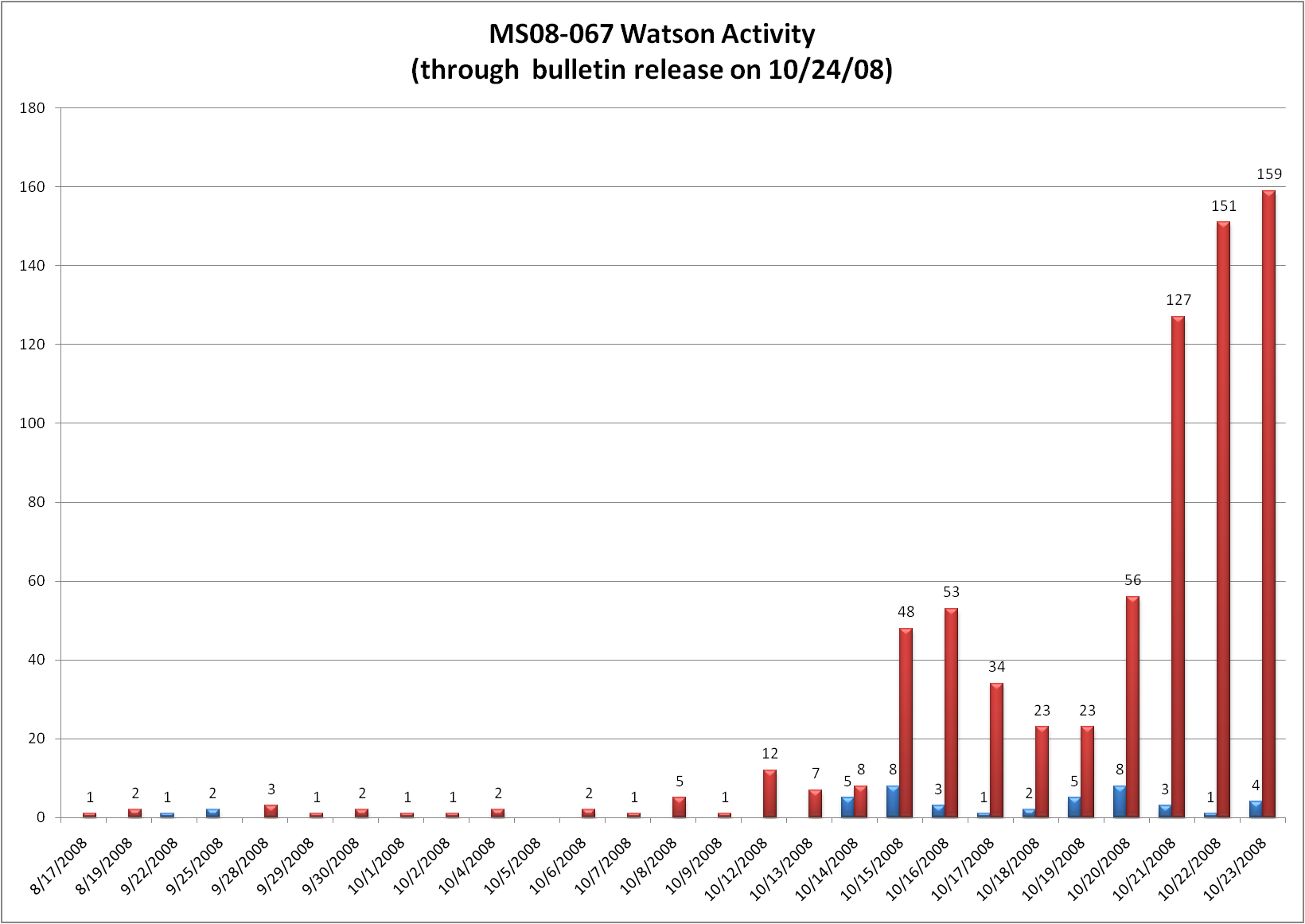
Wykres aktywności atakującego
Czerwone słupki to zarejestrowane próby udane, niebieskie to zarejestrowane próby nieudane. Jak widać pierwsza udana próba zostawiła ślad już 17 sierpnia a do dnia 23 października, kiedy to Microsoft opublikował informację o błędzie oraz odpowiednią łatę, tajemniczy odkrywcy błędu przeprowadzili kilkaset udanych ataków. Pierwsze ataki miały miejsce w Japonii, Malezji, Wietnamie oraz na Filipinach. Wobec takiej skali zjawiska Microsoft nie czekał nawet do planowanego terminu wydania aktualizacji we wtorek, tylko opublikował łaty najszybciej jak było to możliwe. W ciągu tygodnia załatanych zostało co najmniej 400 milionów systemów (nie licząc tych, które znajdowały się za korporacyjnymi firewallami i korzystały z lokalnych repozytoriów aktualizacji). Tajemnicze ataki ustały natychmiast po publikacji informacji o błędzie. Gdy miesiąc później pojawił się słynny Conficker, ciągle mógł zainfekować dziesiątki milionów komputerów – ale to już całkiem inna historia.


Komentarze
macie zajebiste niusy
Po blasterze i sasserze ludzie i tak nie nauczyli się zabezpieczać komputery.
Nie nauczyli się do tej pory.
Poszli nawet dalej.
Korzystają z bankowości z dziurawych smartfonów, na które przychodzą jednorazowe smsy.
To jest normalnie strzał w stopę.
Z niecierpliwością czekam, aż czyściciele kont będą jeździć z imsi catcherami, bo komp przejęty, ale telefon jeszcze nie.
Możliwe, że w przyszłości będą powszechne smsy szyfrowane end-to-end.
Szyfrowane SMSy już istnieją – znaczy może nie technicznie, bo nie są przesyłane drogą którą idą inne SMSy, ale na Androida jest aplikacja TextSecure która właśnie szyfruje wiadomości end-to-end przez Internet. Kwestia ile osób tego używa i z iloma osobami możemy sprawdzić klucze.
Jedyną szansą aluminiowa czapeczka.
Fajny tekst. Zastanawia mnie tylko na ile w czasie, gdy zrobiło się głośno o zbieraniu danych wszelakich przez Windows 10, opublikowanie takiego tekstu przez pracownika Microsoftu nie jest sprytną zagrywką taktyczną.
Jak to jest, że Microsoft zadziwiająco często uzyskuje dostęp do serwerów przestępców? Legalnie włamują się na ich serwery? Przecież tak czy siak przełamują zabezpieczenia, uzyskują dostęp do danych do których nie powinni mieć dostępu – jak to jest?
Myślę, że tak jak w przypadku ubijania botnetów: drogą oficjalną.
Wydaje mi się, że jest to kwestia tego, co mają zamiar zrobić z pozyskanymi danymi. Jeśli jest to pozyskiwanie dowodów na poczet przyszłego śledztwa władz, to stosują drogę oficjalną. Jeśli natomiast chodzi o zwykły rekonesans lub ubicie jakichś złośliwych „usług” na cudzych serwerach, to mają odpowiednie Grey-Haty od tego. Nie wiem, ale gdybym był jakimś bonzo od bezpieczeństwa w wielkiej firmie, to tak bym robił. Zwłaszcza, że jeśli chodzi o te sprawy, to relacja korpo-rząd jest raczej symbiotyczna, nikt nikomu pod górkę nie chce robić, chodzi o bezpieczeństwo obu stron.
Pojadę klasykiem: różnica między win10, a w win7 polega na tym, że w licencji win10 oficjalnie i bezpośrednio napisano, do jakich danych M$ ma dostęp ;)
Ja tam używam win 10 i ciesze się że jestem „częścią czegoś większego” ;D
poważnie.
To przecież odpalcie sobie sniffer najlepiej ponad systemem
poobserwujcie co i gdzie leci po wyłączeniu tych wszystkich kontrowersyjnych funkcji, masz zastrzeżenia irewaling i już
jak przestanie działać OS to system do śmieci . Chociaż i tak sądzę że NSA podobnie jak McAfee jest wszędzie ;>
w skrócie mówiąc chciałem powiedzieć że w teorii przynajmniej da się przecież to wszystko wyłączyć, ale to zawsze miło jak ktoś chce dosrać maga korporacyji
A po co ja mam to wszystko wyłączać, by móc normalnie używać systemu? Jaką mam pewność, że „wyłączone” w ten sposób usługi nie mogą być ponownie włączone zdalnie przez jakiegoś oblecha z trzyliterowej organizacji? To tak jakby kupić zarobaczonego kundla i próbować go odrobaczyć i odpicować, licząc, że wyjdzie z niego rasowy pudel. Żenujące… -_-
Ciekawa historia. Widać, że Microsoft coraz bardziej się stara :)
Chyba zrobić Cię w konia.
dlaczego ludzie ufają produktom apple a MS już nie ?
Dlaczego ufają *nixom ? Proste bo są naiwni
to czysty marksizm leninizm bolszewia nazizm ! *UNIX to komunistyczny system, wytwór propagandy Lenina !!!!!
raczej Gnu Gevary
Jednak NSA szuka 0-dayow w WER. Wlasnie MS to potwierdzil w pewnym sensie ;-)
”Błąd wykorzystywany w ataku znajdował się w kodzie przekształcającym nazwy ścieżek”
aż mi się conficker przypominiał :’) swoją drogą, ciekawe jak wyglądał kod źrodłowy tej biblioteki przed łatkami, skoro w tak prostej funkcji znaleziono tyle błędów…
a chwila, w tagach zauważyłem ze chodzi o MS08-067, czyli ten sam błąd co wykorzystywany przez confickera :D
„Cała firma została postawiona na baczność – ten rodzaj błędu umożliwiał powstanie robaka, który zainfekuje setki milionów komputerów.”
trochę im to zajęło, pamiętam wielką plagę tego robactwa w 2008 :D
Litosci. Nie bledow, a typowych backdoorow. Ten „blad” zostal dopiero wtedy „zalatany”, jak go zaczeli uzywac Chinczycy. Jednak wczesniej, od czasow Windows 2000 jakos nikomu nie przeszkadzal.