Zgodnie z zasadą Pareto 80% dochodu generuje 20% klientów, stąd dla każdego z dostawców ich utrzymanie jest kluczową kwestią. Służą temu różne programy lojalnościowe, ciągłe doskonalenie usług czy produktów, przywiązanie do marki itd. Nie ma w tym nic złego, jeśli nie ogranicza swobody klienta.
Często jednak spotykamy się z praktykami mającymi na celu uzależnienie od dostawcy i konieczności korzystania tylko z jego produktów lub usług. Mówimy wtedy o zjawisku vendor lock-in, występującym również w przypadku usług chmurowych. W artykule opiszę kilka wskazówek, jak uniknąć zagrożeń i nie dać się złapać w pułapkę uzależnienia.
Cykl artykułów
Artykuł jest częścią zaplanowanego na cały rok cyklu artykułów oraz webinarów sponsorowanych przez firmę Aruba Cloud – dostawcę usług chmurowych z centrum przetwarzania w Polsce. W poprzednich omówione zostały zagadnienia:
-
- architektura modelu cloud computingu wg NIST SP 800-145,
- ryzyka natury organizacyjno-prawnej i zarządzania zgodnością na przykładzie pojęcia GRC – Governance, Risk management and Compliance,
- standardy bezpieczeństwa, jakie powinna spełniać usługa chmurowa i jak możemy sprawdzić, czy te standardy faktycznie spełnia,
- zarządzanie tożsamością w chmurze i standardy SAML, OpenID, OAuth,
- wdrożenie i zarządzanie uprawnieniami w chmurze,
- przygotowania do wielkiej awarii,
- bezpieczeństwo centrum danych,
- bezpieczeństwo środowiska wirtualnego,
- szyfrowanie w chmurze,
- zarządzanie incydentami w chmurze.
Ważnym elementem naszego cyklu są także webinary, gdzie będzie można nie tylko posłuchać o chmurze, ale także zadać swoje pytania i otrzymać na nie odpowiedzi. Najbliższe już 25 października o godzinie 20:00 i 26 października o godzinie 12:00. Temat: Zarządzanie cyklem bezpieczeństwa danych w chmurze. Podczas webinaru uczestnicy dowiedzą się, jakie są fazy cyklu życia danych oraz na jakie wyzwania na każdym z etapów można natknąć się przy przetwarzaniu danych w chmurze (gdzie one są i kto ma do nich dostęp). Przedstawiona zostanie też propozycja podejścia do zarządzania bezpieczeństwem danych w chmurze oraz kilka przykładów zabezpieczeń na każdym z etapów cyklu. Możecie zapisywać się już teraz.

Podstawowe pojęcia
Vendor lock-in – uzależnienie od usługi/produktu od konkretnego dostawcy. Zmiana dostawcy pociągnęłaby za sobą duże koszty, jakie należałoby ponieść w celu dostosowania się do innych usług/produktów konkurencji. Jakie mogą być konsekwencje vendor lock-in:
- dyktatura ceny – dostawca może narzucać cenę, wiedząc, iż odbiorca nie ma żadnego alternatywnego wyjścia,
- efekt błędnego koła – nie możemy wycofać się z realizowanego projektu ze względu na zbyt wysokie koszty wyjścia i dostosowania się do nowych rozwiązań,
- uzależnienie klientów, rozprzestrzenianie – jeśli nasze dane są zapisywane w konkretnym formacie plików, wówczas podmioty chcące skorzystać z naszych danych również muszą zaopatrzyć się w narzędzie, mogące odczytać dany format,
- niezgodność z regulacjami – opiszę to na przykładzie Rozporządzenia o ochronie danych osobowych (RODO). W przypadku, gdy jesteśmy administratorem danych, musimy zapewnić prawo do przenoszenia danych. Rozporządzenie stanowi, że osoba fizyczna (podmiot danych), wykonując prawo do przenoszenia danych, „ma prawo żądania, by dane osobowe zostały przesłane przez administratora bezpośrednio innemu administratorowi, o ile jest to technicznie możliwe”. Oznacza to, że zgodnie z wymaganiami RODO administratorzy danych mogą zostać zobowiązani do stosowania interoperacyjnych formatów danych, dających możliwość ponownego wykorzystania danych osobowych pierwotnie przekazanych przez osobę, której one dotyczą.
Interoperacyjność (interoperability) – może być definiowana jako stopień, w jakim jest możliwa współpraca różnych systemów oraz ich zdolność do wymiany danych i ich wykorzystania. W kontekście chmury interoperacyjność rozpatrujemy jako możliwość komunikacji pomiędzy aplikacjami, interfejsami, konfiguracjami, formami uwierzytelniania i autoryzacji, formatami danych w poszczególnych modelach usług chmury (publicznej, prywatnej, hybrydowej) lub pomiędzy usługami chmurowym, a systemami on-premise przedsiębiorstwa. W idealnym świecie interoperacyjność zakłada, że interfejsy są ustandaryzowane i klient może przenieść się do innej chmury bez większego wysiłku. Kwestia interoperacyjności pojawia się w dokumencie „Wytyczne dotyczące prawa do przenoszenia danych” autorstwa Grupy roboczej ds. art. 29. Pojawiają się w nim terminy „ustrukturyzowany”, „powszechnie używany” oraz „nadający się do odczytu maszynowego”, stanowiące zestaw minimalnych wymogów, które powinny umożliwiać interoperacyjność danych przekazanych przez administratora. Jako przykłady formatów umożliwiających interoperacyjność podawane są XML, JSON, CSV, które są stosowane również przez polskie urzędy i instytucje w relacjach online z obywatelami (np. e-deklaracje). Zgodnie z opinią Grupy ds. art. 29 powszechne formaty danych powinny być wykorzystywane wraz z przydatnymi metadanymi na możliwie najwyższym poziomie szczegółowości, przy jednoczesnym zachowaniu wysokiego poziomu abstrakcji. Metadane powinny być wykorzystane do prawidłowego opisania znaczenia informacji będących przedmiotem wymiany w celu umożliwienia funkcjonowania i ponownego wykorzystywania tych danych.
Przenaszalność (portability) – w kontekście usług chmurowych jest to zdolność przenoszenia przez klienta aplikacji i danych pomiędzy swoimi własnymi systemami i usługami chmurowymi, usługami różnych dostawców, a także pomiędzy różnymi modelami usług. Głównym problemem spowodowanym przez brak przenaszalności są nadmierne koszty związane z transformacją aplikacji lub danych z systemu źródłowego na system docelowy. Rozróżniamy dwa obszary przenaszalności w chmurze:
- Przenaszalność danych (cloud data portability) – zdolność do łatwego transferu danych z systemu klienta do usługi chmurowej bądź pomiędzy usługami w powszechnie używanym formacie lub za pomocą powszechnie dostępnych narzędzi.
- Przenaszalność aplikacji (cloud application portability) to zdolność do łatwego transferu aplikacji lub jej poszczególnych komponentów z systemu klienta do usługi chmurowej bądź pomiędzy usługami. Może to wymagać ponownego linkowania (relinking) lub rekompilacji docelowej usługi, ale nie powinno wymagać większych zmian w kodzie źródłowym.
Wyzwania interoperacyjności i przenaszalności
Na początek przedstawię model aplikacji, żeby lepiej zilustrować, jakie elementy są zaangażowane w interoperacyjność i przenaszalność.
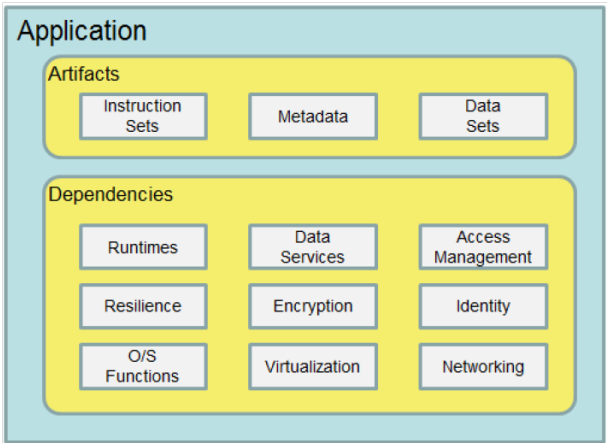
Model aplikacji. Źródło: “Interoperability and Portability for Cloud Computing: A Guide”
Aplikacja składa się z zestawu artefaktów (mogących obejmować zestawy instrukcji, metadane i dane bezpośrednio powiązane z aplikacją) oraz zestawu tzw. dependencies, składających się z różnych bibliotek, serwisów, komponentów i obiektów, takich jak biblioteki wykonawcze, kontrole dostępu, środowiska wirtualizacyjne itd.
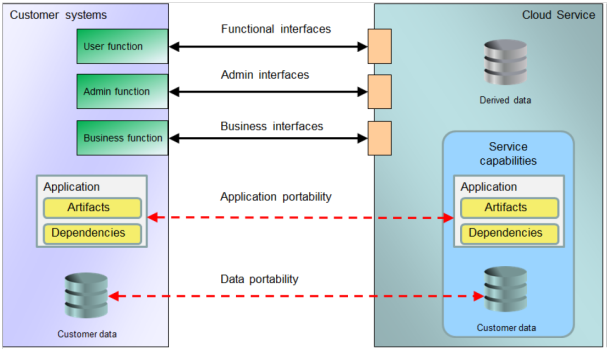
Interoperacyjność i przenaszalność w chmurze. Źródło: “Interoperability and Portability for Cloud Computing: A Guide”
Na powyższej ilustracji widzimy przykład komunikacji pomiędzy systemami klienta a usługami chmurowymi. Wyróżnione są 3 interfejsy:
- funkcjonalny – umożliwiający wykonywanie działań na usługach,
- administracyjny – do zarządzania usługami,
- biznesowy – obejmujący biznesowe aspekty takie jak: subskrypcja, billingi i fakturowanie.
Kwestia interoperacyjności zależy w dużej mierze od rodzaju zastosowanego interfejsu dla każdej z funkcji. Każdy z nich może mieć różne formy, od interfejsu webowego po interfejs programowania aplikacji (API).
Przenoszenie danych klienta do chmury lub pomiędzy usługami albo dostawcami nie powinno stanowić problemu, gdy rozumiemy interfejsy, strukturę i model danych oraz są one w ustandaryzowanym formacie. W modelu SaaS, gdzie dane są pod kontrolą dostawcy, należy też zrozumieć możliwości importowania i eksportowania danych. Jeżeli dodatkowo zależy nam na danych powstałych w wyniku korzystania z usług (derived data), np. zapisów zdarzeń czy danych konfiguracyjnych, musimy również wiedzieć, czy są one dostępne w łatwo przenaszalnym formacie.
O przenaszalności aplikacji możemy mówić w przypadku, gdy aplikacja w chmurze jest zbudowana w modelu IaaS lub PaaS, w których mamy możliwość wpływu na zmiany w aplikacji. W przypadku modelu SaaS musimy pamiętać, że aplikacja jest własnością dostawcy i nie mamy takich możliwości.
Jak zjeść słonia? Pokroić go na kawałki. Jedną z kluczowych technologii w przenoszeniu aplikacji jest konteneryzacja. O kontenerach pisałem więcej w artykule dotyczącym bezpieczeństwa środowiska wirtualnego. Platforma Docker wraz blisko powiązaną inicjatywą Open Container Initiative umożliwiają ustandaryzowane podejście do tworzenia aplikacji, spakowania jej i uruchomienia w innym miejscu. Docker to otwarta platforma dla programistów, administratorów i testerów oprogramowania zajmujących się tworzeniem, wdrażaniem i uruchamianiem aplikacji rozproszonych, czyli zbudowanych z różnych niezależnych elementów. Docker jest określany jako narzędzie, za pomocą którego można umieścić program oraz biblioteki przez niego wymagane w lekkim, przenośnym, wirtualnym kontenerze, dzięki temu można uruchomić go na prawie każdym serwerze z systemem Linux. Docker sprawia, że wykorzystanie konteneryzacji do prototypowania, tworzenia, uruchamiania i działania aplikacji staje się dużo łatwiejsze i zapewnia jej działanie w różnych środowiskach i przenoszenie do różnych dostawców usług. Konteneryzacja jest projektem otwartym, kierującym się standardami oprogramowania otwartego, dzięki temu Docker działa na większości dystrybucji systemów operacyjnych Linux oraz Microsoft i jest wspierany przez większość producentów infrastruktury oraz rozwijany przez ogromną grupę członków społeczności.
W dużej mierze wyzwania dotyczące interoperacyjności i przenaszalności zależą od modelu i architektury chmury, o których pisałem w pierwszym odcinku cyklu. Do pokazania, na jakie problemy możemy się natknąć podczas korzystania z usług chmurowych, posłużę się przykładowym scenariuszem dotyczącym przełączania się pomiędzy dostawcami usługi. Odbiorca usługi, aby uniknąć uzależnienia się od dostawcy A, chce mieć możliwość przełączania się z usługą do dostawcy B
Interoperacyjność
W modelu SaaS aplikacja należy do dostawcy. W tym przypadku nie można brać pod uwagę przeniesienia jej do innego dostawcy, więc należy skupić się na kompatybilności interfejsów. Mało prawdopodobne jest, żeby były identyczne, ale mogą posiadać podobne zestawy reguł do komunikowania się z aplikacją, co może pozwolić na znaczne obniżenie kosztów i czasu związanego m.in. z ich przyswojeniem.
W modelu IaaS i PaaS interoperacyjność nie jest problemem ponieważ aplikacja jest w posiadaniu odbiorcy usług wraz z istniejącymi interfejsami. Problem może stanowić API wykorzystywane do wgrania, rozpakowania i kontrolowania aplikacji.
Przenaszalność danych
W modelu SaaS dane są w posiadaniu odbiorcy usługi, ale ich format jest uzależniony od rozwiązań stosowanych przez dostawcę. Byłoby idealnie, gdyby składnie (zbiór reguł poprawności danych), formaty i semantyka danych (zbiór znaczeń) wraz z metadanymi stosowane przez dostawców A i B były identyczne. Istnieją jednak narzędzia, które umożliwiają transformację i przeniesienie danych mimo różnic w składni. Większym problemem i barierą przy przeniesieniu danych mogą okazać się różnice w semantyce danych.
W modelu IaaS i PaaS składnia i semantyka zależą od odbiorcy usługi i ich wpływ na przenaszalność jest relatywnie niski. W modelu PaaS dostawca może oferować instancje baz danych wspierających standardowe formaty, ale w jaki sposób są one ładowane i z jakim wpływem na składnie, powinno być to wcześniej przeanalizowane
Przenaszalność aplikacji
W przypadku modeli IaaS i PaaS aplikacja należy do klienta, więc pytania o jej przenaszalność na usługi innego dostawcy są bardzo istotne, np. czy docelowe usługi akceptują artefakty aplikacji (np. obraz maszyny wirtualnej czy kontenera), czy usługi wspierają obsługę wszystkich komponentów aplikacji, takich jak biblioteki, serwisy, komponentów, kontrole dostępu, zarządzanie tożsamością. Nie obejdzie się raczej bez zmian, pytanie – jakim kosztem. Dopasowanie kodu do różnych wersji lub bibliotek będzie mniej kosztowe i prostsze w wykonaniu niż przeprojektowanie kodu, żeby dostosować aplikację do różnych interfejsów.
Aspekty interoperacyjności i przenaszalności wg ISO/IEC 19941:2017
Norma ISO/IEC 19941:2017 (Information technology — Cloud computing — Interoperability and portability) prezentuje model 5 aspektów interoperacyjności i 3 aspekty przenaszalności danych, a także 5 aspektów przenaszalności aplikacji wraz z ich rolami.
Aspekty interoperacyjności wg ISO/IEC 19941:2017
| Aspekt | Rola | Obiekty | Rozwiązanie |
| Transport | Transfer danych | Sygnały | Protokoły transferu danych, np. REST HTTP; MQTT |
| Składnia | Zrozumienie formatu przesyłanych danych | Dane | Ustandaryzowane formaty wymiany danych, np. XML, JSON |
| Semantyka | Interpretacja danych z wykorzystaniem modelu danych | Informacja | Wspólne modele danych, np. OData, OWL |
| Behawioralny | Uzyskanie oczekiwanego wyniku na wysłane żądanie | Interfejs programowania | Model UML, warunki wstępne i końcowe, ograniczenia |
| Zgodnościowy | Zapewnienie zgodności z obowiązującymi regulacjami, przepisami prawnymi, politykami | Przepisy prawne, regulacje, polityki | Określone, ujednolicone, ustandaryzowane zasady |
W przypadku gdy aspekty związane z transportem i składnią nie będą jednakowe, można zastosować systemy pośrednie w postaci szyny lub translatorów. Przy różnicach w pozostałych aspektach interoperacyjność może być skomplikowana (dostosowanie kodu) bądź niemożliwa (niezgodność z przepisami prawa).
Aspekty przenaszalności danych
| Aspekt | Rola | Obiekty | Rozwiązanie |
| Składnia | Zrozumienie formatu przesyłanych danych | Dane | Ustandaryzowane formaty wymiany danych, np. XML, JSON |
| Semantyka | Interpretacja danych wykorzystaniem modelu danych | Informacja | Wspólne modele danych, np. OData, OWL |
| Zgodnościowy | Zapewnienie zgodności z obowiązującymi regulacjami, przepisami prawnymi, politykami | Przepisy prawne, regulacje, polityki | Określone, ujednolicone, ustandaryzowane zasady |
Wszystkie aspekty muszą być spełnione, żeby przenaszalność danych była możliwa. Niedopasowania składniowe można zniwelować za pomocą mapujących składnię źródłową na docelową, a semantyczne za pomocą konwertowania danych do formatu docelowego. Przykładowa lista konwerterów prezentowana na stronie: https://www.w3.org/2001/sw/wiki/Category:Converter
Aspekty przenaszalności aplikacji
| Aspekt | Rola | Obiekty | Rozwiązanie |
| Instrukcje | Prawidłowe wykonanie kodu | Artefakty wykonywalne | Java, C++, BPEL
|
| Składnia | Zrozumienie i możliwość użycia formatu artefaktów aplikacji | Artefakty aplikacji | Zip, tar, jar
|
| Metadane | Zrozumienie i możliwość użycia metadanych specyfikujących zależności środowiskowe do uruchomienia aplikacji | Artefakty metadanych | YAML, JSON, Script, XML
|
| Behawioralny | Uzyskanie oczekiwanego wyniku przy uruchamianiu aplikacji | Funkcjonalne i niefunkcjonalne zachowania aplikacji | Model UML, warunki wstępne i końcowe, ograniczenia |
| Zgodnościowy | Zapewnienie zgodności z obowiązującymi regulacjami, przepisami prawnymi, politykami | Przepisy prawne, regulacje, polityki | Określone, ujednolicone, ustandaryzowane zasady |
Aspekt instrukcji (np. obsługa danych, operacje logiczne i arytmetyczne, lokalizacja pamięci itd.) zakłada, że system docelowy zrozumie instrukcje zawarte w artefaktach wykonywalnych. W wielu językach programowania, takich jak Java czy node.js, instrukcje są uniwersalne i wymagają silnika do ich uruchomienia (Java VM).
Aspekt składniowy wymaga, aby system docelowy rozumiał i wspierał formaty wykorzystane w artefaktach aplikacji. W innym przypadku wymagany jest proces konwersji.
Aspekt metadanych jest powiązany z metadanymi aplikacji wraz z ich artefaktami. System docelowy musi rozumieć metadane oraz potrafić je obsłużyć do uruchomienia aplikacji.
Biorąc pod uwagę aspekt behawioralny, należy uwzględnić, że w przypadku, gdy zestaw testów (test suite) po stronie systemu docelowego się nie powiedzie, konieczne może być dostosowanie kodu lub metadanych.
Aspekt zgodnościowy wymaga, aby aplikacja została wytworzona zgodnie z obowiązującymi przepisami prawa, regulacjami i politykami. Dla przykładu RODO określa zasady uwzględnienia ochrony danych osobowych w fazie projektowania, tzw. data protection by design, w skrócie privacy by design, oraz prywatności jako ustawienia domyślnego (tzw. privacy by default). Zakładają one wdrożenie adekwatnych środków technicznych (pseudonimizacji, szyfrowanie, kontroli dostępu itd.) w celu skutecznej realizacji zasad ochrony danych. Niedopasowanie w tym aspekcie może generować duże koszta dostosowania docelowego systemu oraz dotkliwe kary uwzględnione przez regulatorów.
Podsumowanie
- Rozważ wykorzystanie kontenerów, które są szerzej wspierane niż wirtualne maszyny.
- Jednym z rozwiązań do integracji różnych interfejsów, serwisów, protokołów pomiędzy wewnętrznymi usługami a usługami chmurowymi lub pomiędzy usługami chmurowymi różnych dostawców jest zastosowanie dodatkowej warstwy pośredniej w postaci szyny ESB (Enterprise Service Bus) oferowanej również w formie usługi przez wielu dostawców.
- Zidentyfikuj, czy wszystkie aspekty interoperacyjności i przenaszalności danych i aplikacji są dopasowane pomiędzy systemami wewnętrznymi a systemami dostawcy lub pomiędzy usługami różnych dostawców.
- W modelu SaaS upewnij się, że interfejsy, API, protokoły i formaty danych są dobrze zdefiniowane w usługach.
- W modelu PaaS zweryfikuj, czy komponenty aplikacji są oparte na otwartych standardach i technologiach.
- Dla IaaS sprawdź, czy usługi wspierają i akceptują powszechnie używane i standardowe formaty, jak OVF, Docker czy API.
- Upewnij się, że usługi wspierają korzystanie z zewnętrznych usług w zakresie zarządzania dostępem czy tożsamością, takich jak OAuth 2.0, OpenID czy SAML.
Poniżej lista otwartych standardów, które warto sprawdzić pod kątem ich wspierania przez usługi oferowane przez dostawców. Mogą się one okazać bardzo pomocne w aspektach interoperacyjności i przenaszalności.
- Open Virtualization Format (OVF) – otwarty standard zaprojektowany do przenoszenia i kompresji urządzeń wirtualnych rozwijany przez Distributed Management Task Force (DMTF).
- Cloud Data Management Interface (CDMI) – standard wprowadzony przez SNIA (Storage Networking Industry Association), umożliwia zarządzanie danymi przechowywanymi w chmurze z poziomu samej chmury i określa wspólny format bezpiecznej wymiany danych. Tworzy i zapamiętuje metadane określające poziom usług danych, czas ich przechowywania, ilość i miejsce lokalizacji kopii zapasowych.
- Open Cloud Computing Interface (OCCI) – zbiór otwartych specyfikacji budowanych na bazie protokołu HTTP przy wykorzystaniu zbioru praktyk REST. Dzięki temu dostawcy usług mogą oferować różnego typu usługi za pomocą jednolitego interfejsu.
- Topology and Orchestration Specification for Cloud Applications (TOSCA) – standard rozwijany przez OASIS, umożliwiający opis aplikacji i infrastruktury usług chmurowych, relacje pomiędzy komponentami usług oraz zachowania usług.
- Cloud Application Management for Platforms (CAMP) – kolejny standard opracowany przez OASIS, definiujący interoperacyjne protokoły do pakowania i dystrybucji aplikacji.
- LDAP, OAuth, OpenID Connect I SAML – standardy umożliwiające wykorzystanie zewnętrznych narzędzi do zarządzania tożsamością i dostępem.
- Open Container Initiative – projekt stworzony w celu opracowania otwartych standardów dla konteneryzacji.
Przypominamy także o możliwości zapisania się na webinary z Marcinem – najbliższe już 25 października o godzinie 20:00 i 26 października o godzinie 12:00. Tematem spotkania będzie zarządzanie cyklem bezpieczeństwa danych w chmurze. Możecie zapisywać się już teraz.
Dla zachowania pełnej przejrzystości: za opublikowanie tego artykułu pobieramy wynagrodzenie.



Komentarze
Gdyby nie ten cykl artykułów, nie wiedziałbym, że można napisać kilka tysięcy słów i nic nie napisać. Polecam, Krzysztof H.
Hm, ciekawe, bo z mojego punktu widzenia zawiera dużo interesujących mnie rzeczy w uporządkowanej formie. I wiedzę tę da się wykorzystać nie tylko przy zamawianiu usług sponsora artykułu. Jest raczej uniwersalna.
Mam tak samo, ostatnie artykuły na z3s to tysiące bezwartościowych slow.
Zeeeero meteorytyki. Prawie jak nudny wykład polityka..
Jeśli dla kogoś ten artykuł to zero merytoryki, to prawdopodobnie ma za słaby background żeby zrozumieć, o czym to w ogóle jest. Ewentualnie siedzi w innej branży.
Myślałem, że będzie poruszony temat taki jak Kubernetes lub podobne, a tutaj ledwo wspomniany Docker i kontenery. Uważam, że oprogramowanie takie jak np. Rancher jest warte opisania w kwestii uniknięcia vendor lock-in.
Bardzo dobre przykłady i na pewno do szerszego opisania przy rozwinięciu tematu. W tym musiałem upchnąć wiele wątków i podać najbardziej znany przykład.
Jestem przekonany ze wielokrotnie ta teoria zostanie przepisana do roznych prac dyplomowych. Kto wie, moze ktos nawet zrobi jeszcze jeden doktorat. Bo juz przynajmniej jeden zapewne ktos obronil udowadniajac ze polskie slowo 'monopolista’ znacznie madrzej brzmi jako 'vendor lock-in’ (naturalnie wymawiane z akcentem z Texasu: 'wendr lak yn’).
Niekoniecznie można się uzależnić od dostawcy, który jest monopolistą i niekoniecznie monopolista musi stosować praktyki mające na celu uzależnienie od swoich produktów. Chodzi o możliwość wyboru i łatwej zmiany czego w przypadku vendor lock-in nie ma. Wiem że to makaronizm, ale powszechnie funkcjonuje. Sam ich nie lubię i tam gdzie mogę staram się stosować staropolskie odpowiedniki. Tak jak w tym artykule posługuję się terminem uzależnienia od dostawcy.
@Czapa
1) Monopolizacja jest, gdy masz do wyboru jednego dostawcę. A vendor lock-in, gdy wybrany przez Ciebie dostawca (niekoniecznie monopolista) blokuje Ci zmianę, zależnie od branży np. poprzez dziwne formaty danych, niekompatybilne złącza, kary umowne itp.
2) Niektóre ważne zwroty obcojęzyczne nie mają dobrego polskiego odpowiednika i zazwyczaj wchodzą wtedy do użytku jako nowe słowa. Szczególnie jeśli dotyczą zjawisk zależnych od technologii opracowanej w konkretnym języku. Nie zawsze trzeba z tym na siłę walczyć. Polecam anegdotę o zastąpieniu na łodziach podwodnych komendy „szas generalny” spolszczoną jej wersją „wycisk ogólny”.
Polecam notację ArchiMate do diagramów architektury. Została stworzona specjalnie z myślą o uniwersalnym języku opisu i interoperacyjności programistów i architektów, podobnie jak UML dla sotfu.
Oprócz tego zwróciło moją uwagę dziwne uwagi w kontekście przenaszalności danych w modelu PaaS. Skoro mamy dostęp np. do silnika bazy danych, to nie musi być ona, ani otwarta, ani open source. A samo stwierdzenie „W modelu IaaS i PaaS składnia i semantyka zależą od odbiorcy usługi i ich wpływ na przenaszalność jest relatywnie niski.” co najmniej jest intrygujące. Przecież jeśli mamy dostęp do bazy danych to możemy ją sobie wyeksportować?
Poza tym materiał to całkiem fajne zestawienie możliwych ścieżek i wartościowe wskazówki na co warto zwracać uwagę.